网站页面效果图怎么做营销软文是什么意思
Yolov5
Anchor
1.Anchor是啥?
anchor字面意思是锚,是个把船固定的东东(上图),anchor在计算机视觉中有锚点或锚框,目标检测中常出现的anchor box是锚框,表示固定的参考框。
目标检测是"在哪里有什么"的任务,在这个任务中,目标的类别不确定、数量不确定、位置不确定、尺度不确定。传统非深度学习方法和早期深度学习方法,都要金字塔多尺度+遍历滑窗的方式,逐尺度逐位置判断"这个尺度的这个位置处有没有认识的目标",这种穷举的方法非常低效。
最近SOTA的目标检测方法几乎都用了anchor技术。首先预设一组不同尺度不同位置的anchor,覆盖几乎所有位置和尺度,每个anchor负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标,anchor技术将问题转换为"这个固定参考框中有没有认识的目标,目标框偏离参考框多远",不再需要多尺度遍历滑窗,真正实现了又好又快,如在Faster R-CNN和SSD两大主流目标检测框架及扩展算法中anchor都是重要部分。
目标检测中的固定的参考框
yolov5s.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
# 控制模型的大小
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8 目标框anchor是原图 八分之一stride的大小- [30,61, 62,45, 59,119] # P4/16 十六分之一- [116,90, 156,198, 373,326] # P5/32
#感受野比较小,适合小目标检测,浅层次的feature
#往下,感受野变大??适合检测大物体
# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args]
# number(layer重复的次数 实际上会乘上depth_multiple: 0.33,1*0.33)
# args(每层输出的channel,实际上会乘上width_multiple: 0.50 ,64*0.50
# 向上取整
#每行是一个layer的类别,
# 第一列,输入的feature从哪儿来的,-1表示输入来自上一层的输出
# [64, 6, 2, 2] 64是输出的channel,输入channel由上一层决定,6是卷积核大小,stride,padding[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
# 1-P2/4,第一层,p2 ,4 :featuremap的大小变成了原图的 四分之一[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9# SPPF :不同尺度feature的融合]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
#20*20*1024的feature map[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
bottleneck 和detect部分
.pt文件 训练文件
路径在这
detect.py
核心部分
# 通过命令行设置其中的一些参数
# 不同文件对应不同的模型(weights不同,目标检测的置信度不同# --source,输入是个文件夹,会对文件夹下所有的文件进行检测
也可以指定一张图片的相对路径,
可以是视频,会分成一帧一帧来处理
只支持YouTube视频链接,别的视频要下载下来
检测不到的objections 是因为没有进行标记
if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--weights', nargs='+', type=str, default='yolov5l.pt', help='model.pt path(s)')parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcamparser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')置信度,检测结果某个区域置信度大于0.25就当作是个物体实际运用过程中,对参数进行调整和确认的parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')default=0.45,iou的值大于阈值就当作一个objection,从两个框中任选一个来表示这个物体,小于阈值就当作不同的物体设置为0,框和框之间不会有交集parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')-- device:使用CPU还是GPU,可以不同设置,默认是空parser.add_argument('--view-img', action='store_true', help='display results')在命令行中制定了这个参数,就会parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')parser.add_argument('--nosave', action='store_true', help='do not save images/videos')parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')增强检测结果的一些方式 parser.add_argument('--augment', action='store_true', help='augmented inference')parser.add_argument('--update', action='store_true', help='update all models')parser.add_argument('--project', default='runs/detect', help='save results to project/name')parser.add_argument('--name', default='exp', help='save results to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')opt = parser.parse_args()print(opt)check_requirements(exclude=('pycocotools', 'thop'))
通过命令行设置其中的一些参数不同文件对应不同的模型(weights不同,目标检测的置信度不同
# --source,输入是个文件夹,会对文件夹下所有的文件进行检测
也可以指定一张图片的相对路径,
可以是视频,会分成一帧一帧来处理
只支持YouTube视频链接,别的视频要下载下来
检测不到的objections 是因为没有进行标记
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
对输入的image进行 resize,再送入神经网络中
这些训练模型,指定image size是640
训练过程,网络运算过程中对图片大小进行缩放,会恢复,输入输出尺寸其实保持不变,
最好是和训练模型指定的image size进行匹配,不匹配也没关系
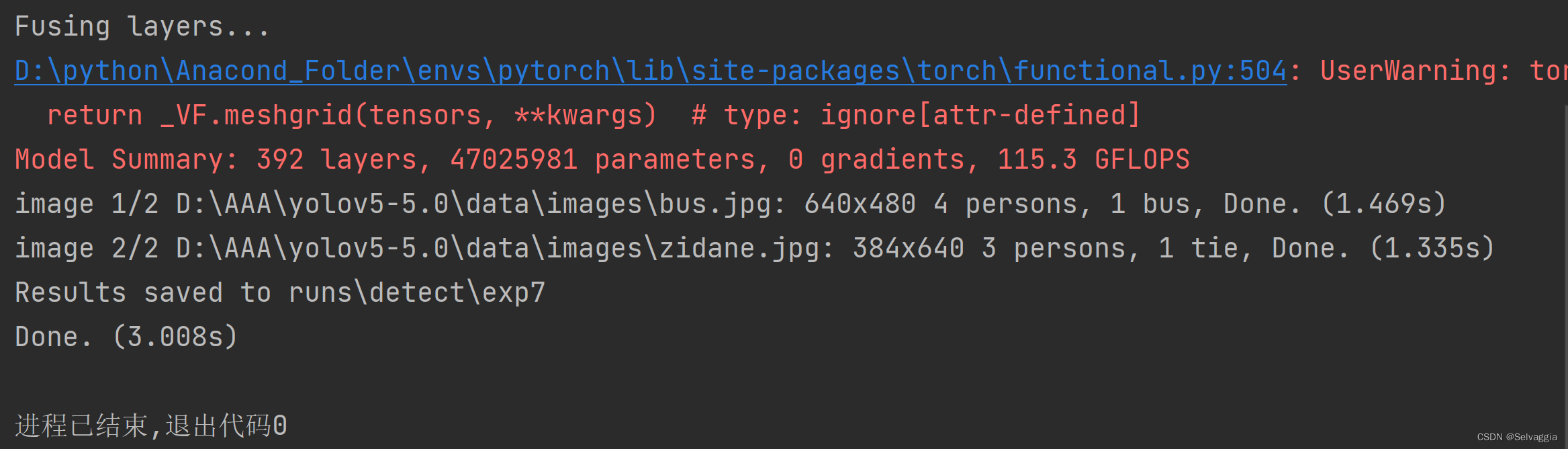
运行结果
进行实时检测,rstp链接
通过手机电脑摄像头检测