三峡建设委员会网站怎么在百度上推广
mybatis-plus作为mybatis的增强工具,它的出现极大的简化了开发中的数据库操作,但是长久以来,它的联表查询能力一直被大家所诟病。一旦遇到left join或right join的左右连接,你还是得老老实实的打开xml文件,手写上一大段的sql语句。
直到前几天,偶然碰到了这么一款叫做mybatis-plus-join的工具(后面就简称mpj了),使用了一下,不得不说真香!彻底将我从xml地狱中解放了出来,终于可以以类似mybatis-plus中QueryWrapper的方式来进行联表查询了,话不多说,我们下面开始体验。
1 引入依赖
首先在项目中引入引入依赖坐标,因为mpj中依赖较高版本mybatis-plus中的一些api,所以项目建议直接使用高版本。
<dependency><groupId>com.github.yulichang</groupId><artifactId>mybatis-plus-join</artifactId><version>1.2.4</version>
</dependency>
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version>
</dependency>引入相关依赖后,在springboot项目中,像往常一样正常配置数据源连接信息就可以了。
2 数据准备
因为要实现联表查询,所以我们先来建几张表进行测试。
订单表:
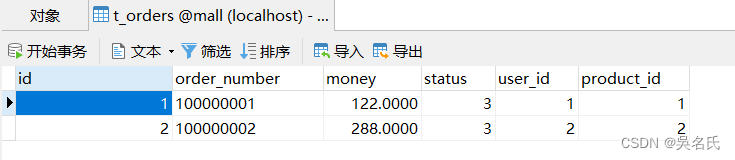
用户表,包含用户姓名:
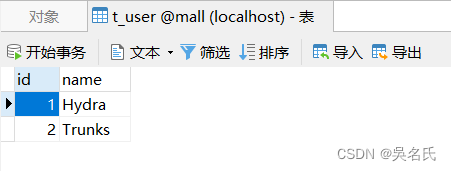
商品表,包含商品名称和单价:
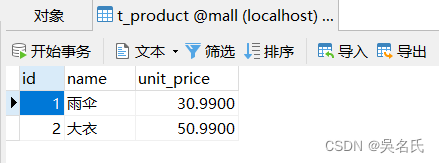
在订单表中,通过用户id和商品id与其他两张表进行关联。
3 修改Mapper
以往在使用myatis-plus的时候,我们的Mapper层接口都是直接继承的BaseMapper,使用mpj后需要对其进行修改,改为继承MPJBaseMapper接口。
@Mapper
public interface OrderMapper extends MPJBaseMapper<Order> {
}对其余两个表的Mapper接口也进行相同的改造。此外,我们的service也可以选择继承MPJBaseService,serviceImpl选择继承MPJBaseServiceImpl,这两者为非必须继承。
4 查询
Mapper接口改造完成后,我们把它注入到Service中,虽然说我们要完成3张表的联表查询,但是以Order作为主表的话,那么只注入这一个对应的OrderMapper就可以,非常简单。
@Service
@AllArgsConstructor
public class OrderServiceImpl implements OrderService {private final OrderMapper orderMapper;
}4.1使用MPJLambdaWrapper进行联表查询
接下来,我们体验一下再也不用写sql的联表查询:
public void getOrder() {List<OrderDto> list = orderMapper.selectJoinList(OrderDto.class,new MPJLambdaWrapper<Order>().selectAll(Order.class).select(Product::getUnitPrice).selectAs(User::getName,OrderDto::getUserName).selectAs(Product::getName,OrderDto::getProductName).leftJoin(User.class, User::getId, Order::getUserId).leftJoin(Product.class, Product::getId, Order::getProductId).eq(Order::getStatus,3));list.forEach(System.out::println);
}不看代码,我们先调用接口来看一下执行结果:

可以看到,成功查询出了关联表中的信息,下面我们一点点介绍上面代码的语义。
首先,调用mapper的selectJoinList()方法,进行关联查询,返回多条结果。后面的第一个参数OrderDto.class代表接收返回查询结果的类,作用和我们之前在xml中写的resultType类似。
这个类可以直接继承实体,再添加上需要在关联查询中返回的列即可:
@Data
@ToString(callSuper = true)
@EqualsAndHashCode(callSuper = true)
public class OrderDto extends Order {String userName;String productName;Double unitPrice;
}接下来的MPJLambdaWrapper就是构建查询条件的核心了,看一下我们在上面用到的几个方法:
selectAll():查询指定实体类的全部字段
select():查询指定的字段,支持可变长参数同时查询多个字段,但是在同一个select中只能查询相同表的字段,所以如果查询多张表的字段需要分开写
selectAs():字段别名查询,用于数据库字段与接收结果的dto中属性名称不一致时转换
leftJoin():左连接,其中第一个参数是参与联表的表对应的实体类,第二个参数是这张表联表的ON字段,第三个参数是参与联表的ON的另一个实体类属性
除此之外,还可以正常调用mybatis-plus中的各种原生方法,文档中还提到,默认主表别名是t,其他的表别名以先后调用的顺序使用t1、t2、t3以此类推。
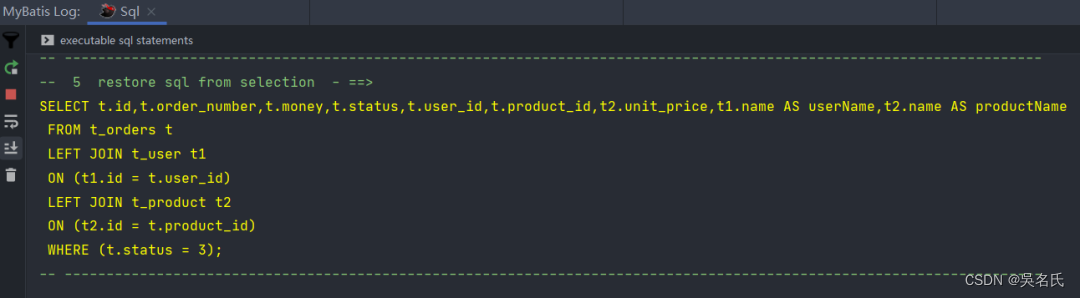
我们用插件读取日志转化为可读的sql语句,可以看到两条左连接条件都被正确地添加到了sql中:
4.2 使用MPJQueryWrapper进行联表查询
和mybatis-plus非常类似,除了LamdaWrapper外还提供了普通QueryWrapper的写法,改造上面的代码:
public void getOrderSimple() {List<OrderDto> list = orderMapper.selectJoinList(OrderDto.class,new MPJQueryWrapper<Order>().selectAll(Order.class).select("t2.unit_price","t2.name as product_name").select("t1.name as user_name").leftJoin("t_user t1 on t1.id = t.user_id").leftJoin("t_product t2 on t2.id = t.product_id").eq("t.status", "3"));list.forEach(System.out::println);
}运行结果与之前完全相同,需要注意的是,这样写时在引用表名时不要使用数据库中的原表名,主表默认使用t,其他表使用join语句中我们为它起的别名,如果使用原表名在运行中会出现报错。
并且,在MPJQueryWrapper中,可以更灵活的支持子查询操作,如果业务比较复杂,那么使用这种方式也是不错的选择。
5 分页查询
mpj中也能很好的支持列表查询中的分页功能,首先我们要在项目中加入分页拦截器:
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.H2));return interceptor;
}接下来改造上面的代码,调用selectJoinPage()方法:
public void page() {IPage<OrderDto> orderPage = orderMapper.selectJoinPage(new Page<OrderDto>(2,10),OrderDto.class,new MPJLambdaWrapper<Order>().selectAll(Order.class).select(Product::getUnitPrice).selectAs(User::getName, OrderDto::getUserName).selectAs(Product::getName, OrderDto::getProductName).leftJoin(User.class, User::getId, Order::getUserId).leftJoin(Product.class, Product::getId, Order::getProductId).orderByAsc(Order::getId));orderPage.getRecords().forEach(System.out::println);
}注意在这里需要添加一个分页参数的Page对象,我们再执行上面的代码,并对日志进行解析,查看sql语句:
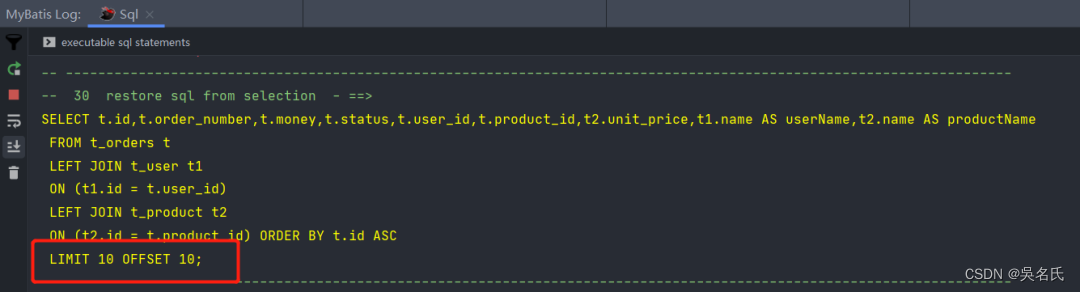
可以看到底层通过添加limit进行了分页,同理,MPJQueryWrapper也可以这样进行分页。
6 最后总结
经过简单的测试,个人感觉mpj这款工具在联表查询方面还是比较实用的,能更应对项目中不是非常复杂的场景下的sql查询,大大提高我们的生产效率。当然,在项目的issues中也能看到当前版本中也仍然存在一些问题,希望在后续版本迭代中能继续完善。