不错的建设工程人员查询家庭优化大师免费下载
摘要
科学知识主要存储在书籍和科学期刊中,通常以PDF的形式。然而PDF格式会导致语义信息的损失,特别是对于数学表达式。我们提出了Nougat,这是一种视觉transformer模型,它执行OCR任务,用于将科学文档处理成标记语言,并证明了我们的模型在新的科学文档数据集上的有效性。
引言
存储在pdf中的知识,信息提取有难度,其中数学表达式的语义信息会丢失。现有的OCR方法没有办法识别公式。为此,我们引入了Nougat,这是一种基于transformer的模型,能将文档页面的图像转换为格式化的标记文本。这篇论文的主要贡献如下:
1) 发布能够将PDF转换为轻量级标记语言的预训练模型;
2) 我们引入了一个将pdf转为标记语言的pipeline;
3) 我们的方法仅依赖于页面的图像,支持扫描的论文和书籍;
模型
以前的VDU(视觉文档理解)方法要么依赖于第三方OCR工具,要么专注于文档类型,例如:收据、发票或类似表单的文档。最近的研究表明,不需要外部OCR,在VDU中也能实现有竞争力的结果。
如图1所示,我们的模型基于donut构建,是一个encoder-decoder模型,允许端到端的训练。
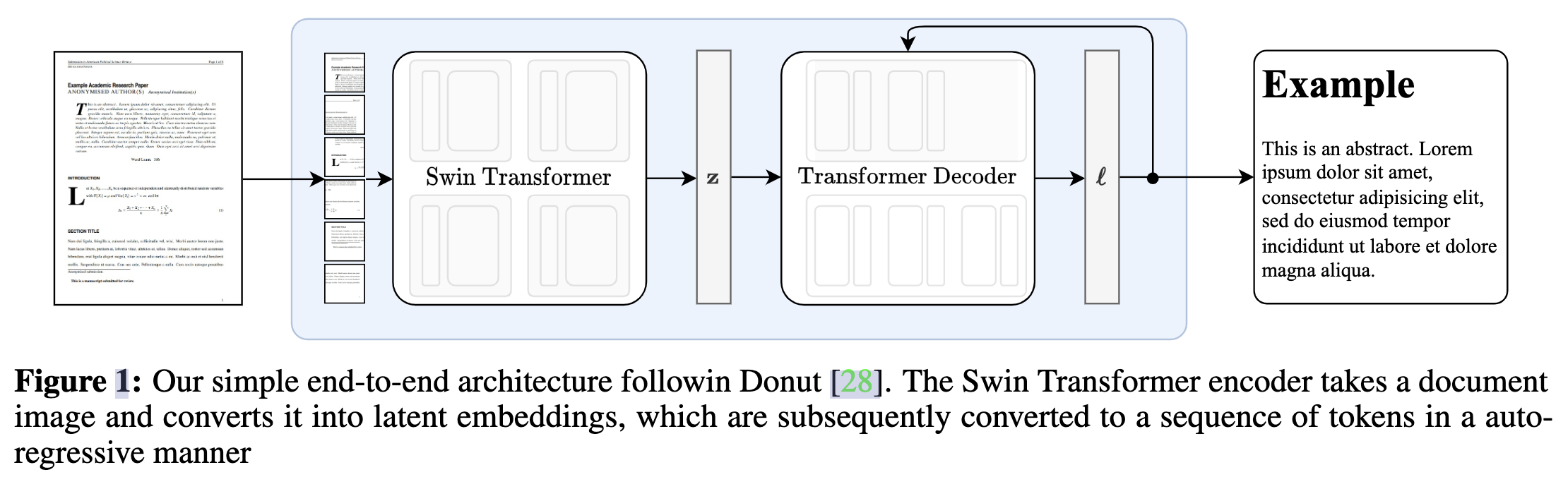
编码器
视觉encoder首先接受一张文档图像,裁剪边距并调整图像大小成固定的尺寸(H,W);如果图像小于矩形,那么增加额外的填充以确保每个图像具有相同的维度。我们使用了Swin Transformer,将图像分为不重叠的固定大小的窗口,然后应用一系列的自注意力层来聚集跨窗口的信息。该模型输出一个embedding patch ,其中d是隐层维度,N是patch的数目。
解码器
使用带有cross-attention的mBART解码器解码,然后生成一系列tokens,最后tokens被投影到vocabulary的大小,产生logits。我们使用作为decoder;
SetUP
我们用96 DPI的分辨率渲染文档图像。由于swin transformer的限制性,我们将input size设置为(896,672);文档图像先resize,然后pad到所需的大小,这种输入大小允许我们使用Swin基础模型架构。我们用预训练的权重初始化了模型,Transformer解码器的最大序列长度是4096。这种相对较大的规模是因为学术研究论文的文本可能是密集的,尤其表格的语法是token密集的。BART解码器是一个10层的decoder-only transformer。整个架构共有350M参数;在推理的时候,文本使用greedy decoding生成的。
训练:使用AdamW优化器训练3个epoch,batch_size是192;初始化学习率是;
数据增强
在图像识别任务中,使用数据增强来提高泛化性是有效的。由于我们的训练集只有学术论文,所以我们需要应用一系列的transformation来模拟扫描文档的缺陷和可变性。这些变换包括:腐蚀,膨胀,高斯噪声,高斯模糊,位图转换,图像压缩,网格失真和弹性变换。每个都有一个固定的概率来应用给给定图像。每个转换的效果如图所示:

在训练过程中,我们会用随机替换token的方式给groud truth增加扰动。
数据
目前没有pdf页面和其对应的source code的成对数据集。因为我们根据arxiv上的开源文章,建立了自己的数据集。对于layout多样性,我们引入了PMC开源非商业数据集的子集。在预训练过程中,也引入了一部分行业文档库数据。
ARXIV
我们从arxiv上收集了174w+的pape,收集其源代码并编译pdf。为了保证格式的一致性,我们首先用latex2html处理源文件,并将他们转为html文件。这一步很重要,因为他们是标准化的并且去掉了歧义,尤其是在数学表达式中。转换过程包括:替换用户定义的宏,添加可选括号,规范化表以及用正确的数字替换引用。然后我们解析html文件,并将他们转换为轻量级标记语言,支持标题,粗体和斜体文本、公式,表等各种元素。这样,我们能保证源代码格式是正确的,方便后续处理。整个过程如图所示:

PMC
我们还处理了来自PMC的文章,其中除了PDF文件之外,还可以获得具有语义信息的XML文件。我们将这些文件解析为与arxiv文章相同的标记语言格式,我们选择使用PMC少得多的文章,因为XML文件并不总是具有丰富的语义信息。通常,方程和表格存储为图像,这些情况检测起来并非易事,这导致我们决定将PMC文字的使用限制在预训练阶段。
IDL
IDL是行业产生的文档集合。这个仅用在预训练阶段,用于教模型基本的OCR;
分页
我们根据pdf的页中断来分割markdown标记,然后将每个pdf页面转为图像,来获得图像-标记pair。在编译过程中,Latex会自动确定pdf的页面中断。由于我们没有重新编译每篇论文的Latex源,我们必须启发式地将源文件拆分为对应不同页面的部分。为了实现这一点,我们使用PDF页面上的嵌入文本和源文本进行匹配。
然而,PDF中的图像和表格可能不对应他们在源代码中的位置。为了解决这个问题,我们在预处理阶段去掉了这些元素。然后将识别的标题和XML文件中的标题进行比较,并根据他们的Levenshtein距离进行匹配。一旦源文档被分成单个页面,删除的图形和表格就会在每个页面的末尾重新插入。