isite企业建站系统外链查询工具
1、filebeat概述
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash或kafka进行索引
1.1 Filebeat两个主要组件
prospector 和 harvester。
prospector:探测者
harvester:采集器
prospector 负责管理harvester并找到所有要读取的文件来源。 如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。
Prospector*(勘测者):**负责管理Harvester并找到所有读取源。Prospector会找到/apps/logs/目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
Harvester**(收割机):**负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到制定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive(如果此选项开启,filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m)。
Filebeat如何记录文件状态:
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
Filebeat目前支持两种prospector类型:log和stdin。
负责读取单个文件的内容。 如果文件在读取时被删除或重命名,Filebeat将继续读取文件。
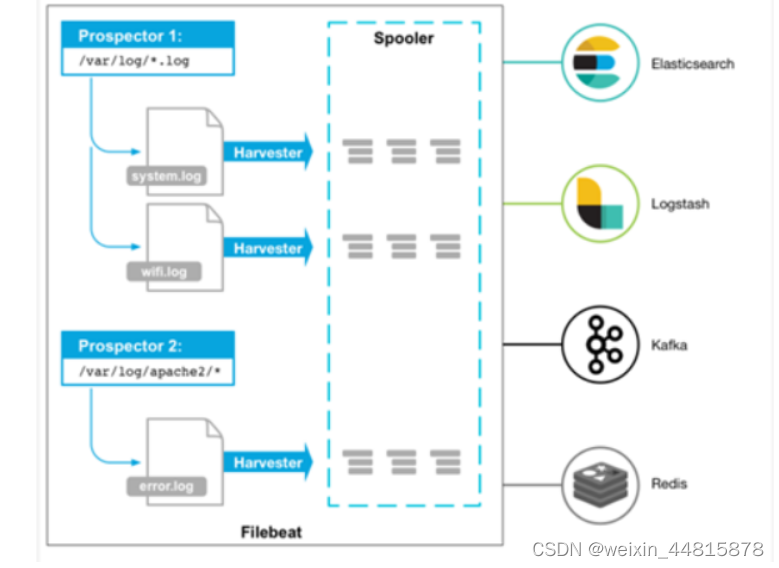
总结:
1.Prospectors:检测和采集日志数据的组件,可以检测新的日志文件或文件增量,并向Harvesters发送读取请求。
2.Harvesters:读取日志文件的组件,会读取Prospector传来的日志文件,进行过滤和捕捉,并将事件发送给Spooler。
3.Spooler:收集Harvester读取的事件,并进行缓冲,最后批量发送给输出(Output)。
4.Registry记录哪些文件被读取过,和读取到的Offset,用于下次检测文件增量。
5.Filebeat通过不断反复以上步骤,来持续监控和采集日志数据。
在 /usr/local/filebeat-7.8.0-linux-x86_64/data/registry/filebeat
2.filebeat 和logstarch 对比优缺点?
Filebeat和Logstash都是ELK栈中的重要组件,但有以下主要优缺点对比:
2.1 filebeat优缺点
filebeat优点:
1.轻量级,资源消耗小,易于在每台服务器部署。
2.模块化设计,支持丰富的输入和输出插件,易于扩展。
3.能保存状态并支持断点续传,避免重复发送数据。
4.文件采集不依赖inotify,适用于各环境。
Filebeat缺点:
1.依赖其他组件(如Logstash)进行复杂的数据处理和分析。
2.不支持实时数据分析,有一定延迟。
Harvester 和 Spooler 采用的是批量采集和批量发送的方式,因此存在一定的延迟,无法做到实时数据分析。
延迟的主要原因有两个:
-
缓存策略导致的延迟:Harvester 采集到的数据会先缓存在本地磁盘中,等待 Spooler 进行批量传输。如果缓存的事件数量较少,或者数据采集频率较低,可能需要等待一段时间才能达到一定的批量大小,从而导致延迟。
-
网络传输导致的延迟:Spooler 批量传输数据到目标数据存储也需要一定的时间,特别是当目标数据存储和 Harvester 所在服务器之间的网络较慢或不稳定时,会导致更大的延迟。
因此,如果需要实现实时数据分析,需要采用实时数据传输的方式,例如使用 Kafka 等消息队列,将数据采集和数据分析解耦,实现高效实时的数据传输和处理。同时,还需要优化数据采集和传输的性能和稳定性,以保证数据的实时性和准确性。
3.支持的日志格式有限,很多格式需要自定义parser。
2.2 logstash优缺点
Logstash优点:
1.功能强大,支持丰富的数据过滤、转换和输出。
2.支持实时数据处理和分析。
3.支持的日志格式和数据源广泛,社区支持强大。
4.配置灵活,Pipeline可以组合多种filter和output,实现复杂的数据处理逻辑。
Logstash缺点:
1.资源消耗较大,不易在大规模服务器上部署。
2.配置和管理复杂,Pipeline的调试和维护难度较大。
3.不保存状态,无法断点续传,会重复处理以发送数据。
4.依赖Filebeat等工具进行数据采集,本身不具备文件监控能力。
总结:Filebeat跟Logstash虽然位于ELK栈的不同层面,但可以相互配合,形成完整的日志采集和处理体系。Filebeat专注于高效稳定的日志采集,Logstash专注于强大灵活的数据处理。Filebeat的轻量级和Logstash的功能强大,可以很好的弥补彼此的不足。所以在实际应用中,常常会同时使用Filebeat和Logstash,实现日志数据的采集、过滤、转换、丰富和输出。通过理解两者的优缺点,可以让我们更好的利用ELK栈,构建高效、灵活且易于维护的日志解决方案