哪个公司做网站比较好网络推广的方式和途径有哪些
网络爬虫
概述
网络爬虫是LangChain中的一项关键功能,允许用户自动从互联网上收集信息。这项功能对于研究和数据收集尤其有价值,因为它可以大幅减少手动搜索和信息整理的工作量。
从网络收集内容有几个主要组件:
Search搜索:使用工具如GoogleSearchAPIWrapper查询并获取URL列表。Loading加载:将URL转换为HTML内容,使用工具如AsyncHtmlLoader或AsyncChromiumLoader。Transforming转换:将HTML内容转换为格式化文本,使用HTML2Text或BeautifulSoup等工具。
准备
安装相关依赖库
pip install langchain-openai langchain playwright beautifulsoup4
设置OpenAI的BASE_URL、API_Key
import osos.environ["OPENAI_BASE_URL"] = "https://xxx.com/v1"
os.environ["OPENAI_API_KEY"] = "sk-dtRXRfYzHDZQT8Cr2874xxxx13F97bF24b7a"
加载器
使用Chromium的无头实例爬取HTML内容,无头模式意味着浏览器在没有图形用户界面的情况下运行,这通常用于网页抓取。
主要有2种方式:
| 方式 | 加载器 | 描述 |
|---|---|---|
| Python的asyncio库 | AsyncHtmlLoader | 使用该库aiohttp发出异步 HTTP 请求,适合更简单、轻量级的抓取。 |
| Playwright | AsyncChromiumLoader | 使用 Playwright 启动 Chromium 实例,该实例可以处理 JavaScript 渲染和更复杂的 Web 交互。 |
注意:
Chromium 是 Playwright 支持的浏览器之一,Playwright 是一个用于控制浏览器自动化的库。
from langchain_community.document_loaders import AsyncChromiumLoader# 加载HTML
loader = AsyncChromiumLoader(["https://www.langchain.com"])
html = loader.load()
转换
html2text
html2text 是一个 Python 包,它将 HTML 页面转换为干净、易于阅读的纯文本,无需任何特定的标签操作。它最适合目标是提取人类可读文本而不需要操作特定HTML元素的场景。
要使用html2text,首先需要额外安装
pip install html2text
使用示例如下:
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import Html2TextTransformer# 加载HTML
loader = AsyncChromiumLoader(["https://www.langchain.com"])
html = loader.load()# # 转换
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(html)# 结果
res = docs_transformed[0].page_content[0:500]
print(res)
Beautiful Soup
Beautiful Soup 提供对 HTML 内容更细粒度的控制,支持特定标签的提取、删除和内容清理。它适合根据需要提取特定信息并清理 HTML 内容的情况。
要使用Beautiful Soup,首先也是需要安装
pip install beautifulsoup4
使用示例如下
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
# 加载HTML
loader = AsyncChromiumLoader(["https://www.langchain.com"])
html = loader.load()# # 转换
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(html, tags_to_extract=["h1"])# 结果
res = docs_transformed[0].page_content[0:500]
print(res)
从HTML内容中爬取文本内容标签说明
<p>:段落标签。在HTML中定义段落,并用于组合相关句子或短语<li>:列表项标签。用于有序(<ol>)和无序(<ul>)列表中,定义列表中的各个项<div>:分区标签。块级元素,用于组合其他内联或块级元素<a>:锚点标签。用于定义超链接<span>:内联容器,用于标记文本的一部分或文档的一部分
提取
定义模式、架构来指定想要提取的数据类型。键名很重要,因为它告诉 LLM想要什么样的信息。
# 定义模式、架构来指定想要提取的数据类型
schema = {"properties": {"all_tutorial_category": {"type": "string"},"category_item": {"type": "string"},},"required": ["all_tutorial_category"],
}
提取网页内容的爬虫实现如下
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from langchain_openai import ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitterllm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
from langchain.chains import create_extraction_chain# 定义模式、架构来指定想要提取的数据类型
schema = {"properties": {"category_item": {"type": "string"},},"required": ["category_item"],
}# 执行提取链
def extract(content: str, schema: dict):return create_extraction_chain(schema=schema, llm=llm).invoke(content)# 使用AsyncChromiumLoader加载器
def scrape_with_playwright(urls, schema):loader = AsyncChromiumLoader(urls)docs = loader.load()bs_transformer = BeautifulSoupTransformer()# 限制爬取指定标签内容docs_transformed = bs_transformer.transform_documents(docs, tags_to_extract=["h4"])print("使用 LLM 提取内容")# 获取网站的前 1000 个token文本splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)splits = splitter.split_documents(docs_transformed)# 拆分处理extracted_content = extract(schema=schema, content=splits[0].page_content)# 打印内容# pprint.pprint(extracted_content)return extracted_contentif __name__ == '__main__':urls = ["https://www.runoob.com/"]extracted_content = scrape_with_playwright(urls, schema=schema)print(extracted_content)
执行部分日志如下,可以看出数据提前成功
text': [{'category_item': 'HTML'}, {'category_item': 'CSS'}, {'category_item': 'Bootstrap'},
{'category_item': 'Font Awesome'}, {'category_item': 'Foundation'}, {'category_item': 'JavaScript'},
{'category_item': 'HTML DOM'}, {'category_item': 'jQuery'}, ........{'category_item': 'Markdown'}, {'category_item': 'HTTP'},
{'category_item': 'TCP/IP'}, {'category_item': 'W3C'}]}
自动化
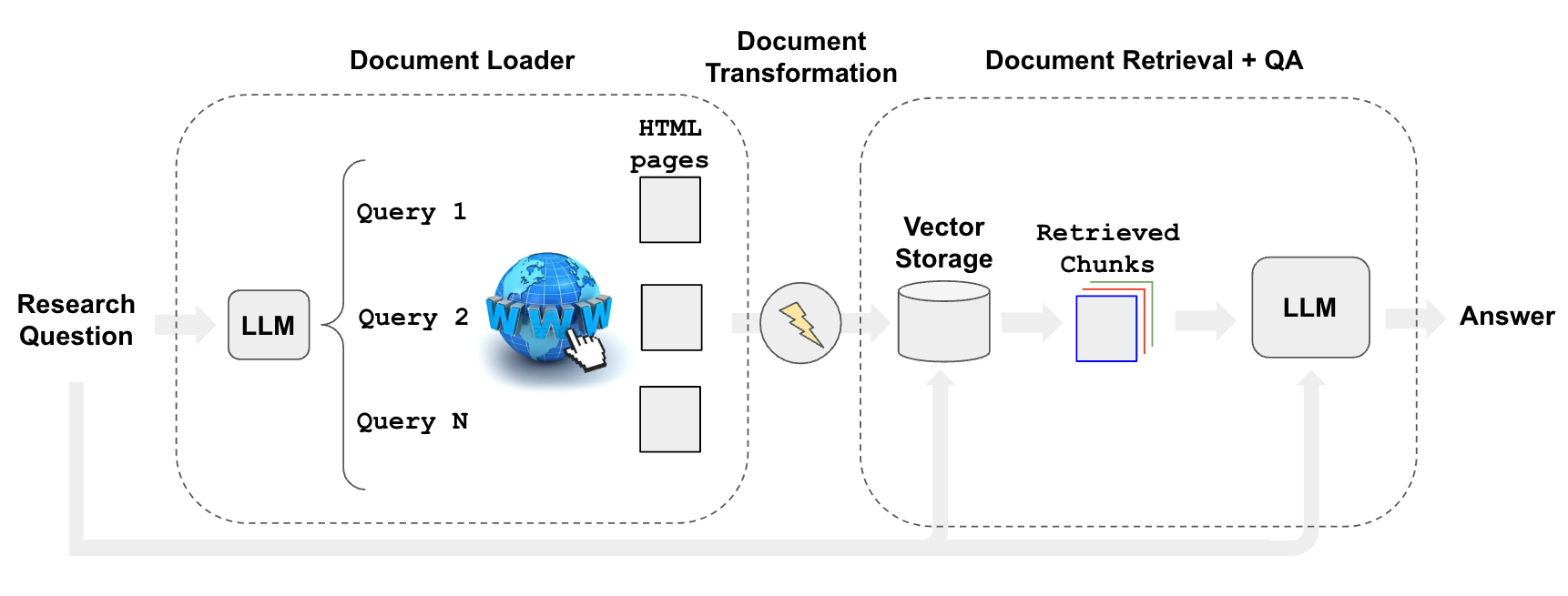
可以使用检索器(如WebResearchRetriever)来自动化网络研究过程,以便使用搜索内容回答特定问题。
借助Google的Custom Search JSON API,以程序化地检索和显示来自可编程搜索引擎的搜索结果。,具体阅读文档创建GOOGLE_API_KEY和GOOGLE_CSE_ID
自动化爬取实现如下
from langchain.retrievers.web_research import WebResearchRetriever
from langchain_chroma import Chroma
from langchain_community.utilities import GoogleSearchAPIWrapper
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
import logging
from langchain.chains import RetrievalQAWithSourcesChainimport osos.environ["GOOGLE_API_KEY"] = 'AIzaSyBNrdu0_xxxxx-Vk2nDs'
os.environ["GOOGLE_CSE_ID"] = '405fxxxxxx64ca1'# 向量存储:使用 Chroma 客户端进行初始化
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), persist_directory="./chroma_db_oai"
)# LLM
llm = ChatOpenAI(temperature=0)# 搜索
search = GoogleSearchAPIWrapper()"""
使用上述工具初始化检索器:使用 LLM 生成多个相关搜索查询(一次 LLM 调用)
对每个查询执行搜索
选择每个查询的前 K 个链接(并行多个搜索调用)
从所有选定的链接加载信息(并行抓取页面)
将这些文档索引到矢量存储中
为每个原始生成的搜索查询查找最相关的文档
"""
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search
)# 设置日志
logging.basicConfig()
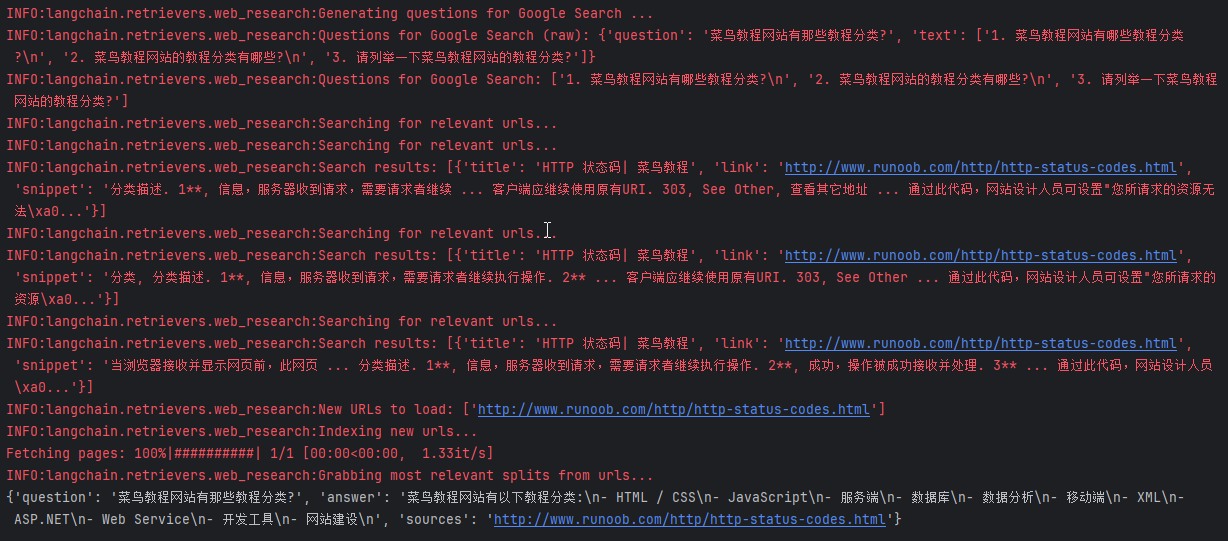
logging.getLogger("langchain.retrievers.web_research").setLevel(logging.INFO)# 执行
user_input = "菜鸟教程网站有那些教程分类?"
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=web_research_retriever
)
result = qa_chain.invoke({"question": user_input})
print(result)
输出结果如下