购物网站设计方案网站设计公司网站制作
🧠 1. 什么是伪分布式模式(Pseudo-distributed Mode)?
在 Hadoop 中,伪分布式模式是一种 用一台机器模拟多节点集群 的运行方式。
-
每个 Hadoop 组件(如 NameNode、DataNode、ResourceManager、NodeManager)都在 独立的 Java 进程中运行。
-
适合做开发、调试、学习使用。
简单来说:“一台电脑,装扮成一群电脑”。
🔁 2. 什么是 MapReduce?
MapReduce 是一种用于大数据处理的编程模型,由两个阶段组成:
| 阶段 | 作用说明 |
|---|---|
| Map | 对数据进行切分处理,比如统计每个词出现一次 |
| Reduce | 对中间结果合并,比如把相同的词频加总 |
经典例子是:统计一篇文章中每个单词出现了几次(WordCount)
🔧 3. 开始运行 WordCount 示例程序
我们使用的是 Hadoop 自带的 MapReduce 示例程序:hadoop-mapreduce-examples-3.3.4.jar
里面包括了经典的应用程序,比如:wordcount, grep, pi 等。
🪜 步骤一:查看有哪些示例程序
$ hadoop jar /usr/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar📌 这条命令会列出 JAR 包里的所有示例,比如:
-
wordcount:统计词频 -
grep:用正则表达式匹配文本 -
pi:估算圆周率

🪜 步骤二:查看 wordcount 的用法
$ hadoop jar /usr/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount你会看到提示:
Usage: wordcount <input> <output>说明它需要两个参数:
-
输入路径(input):HDFS 上的目录,里面放文本文件
-
输出路径(output):结果存储的目录(注意不能事先存在)

🪜 步骤三:准备环境
✅ 1)启动 HDFS 和 YARN
$ start-dfs.sh $ start-yarn.sh-
start-dfs.sh启动分布式文件系统(NameNode、DataNode) -
start-yarn.sh启动任务调度系统(ResourceManager、NodeManager)
✅ 2)创建用户目录(如果没建过)
$ hdfs dfs -mkdir -p /user/user这一步是给你在 HDFS 上建一个“个人文件夹”。

🪜 步骤四:上传输入文件
✅ 创建输入目录并上传文件:
$ hdfs dfs -mkdir input$ hdfs dfs -put text.txt input-
mkdir input是在 HDFS 上建一个input文件夹 -
put text.txt input把本地的text.txt文件上传进去
🪜 步骤五:运行 WordCount 程序!
$ hadoop jar /usr/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount input output-
输入目录是
input -
输出目录是
output -
程序会在后台运行 Map 和 Reduce 任务,统计每个单词的出现次数。
🪜 步骤六:查看结果
✅ 方法一:下载输出结果到本地
$ hdfs dfs -get output/part-* $ cat part-r-00000-
part-r-00000是 Reduce 阶段的输出文件。 -
里面是每个单词及其频率,比如:
a 5 and 3 hadoop 10
✅ 方法二:直接在终端查看输出内容
$ hdfs dfs -cat output/part-*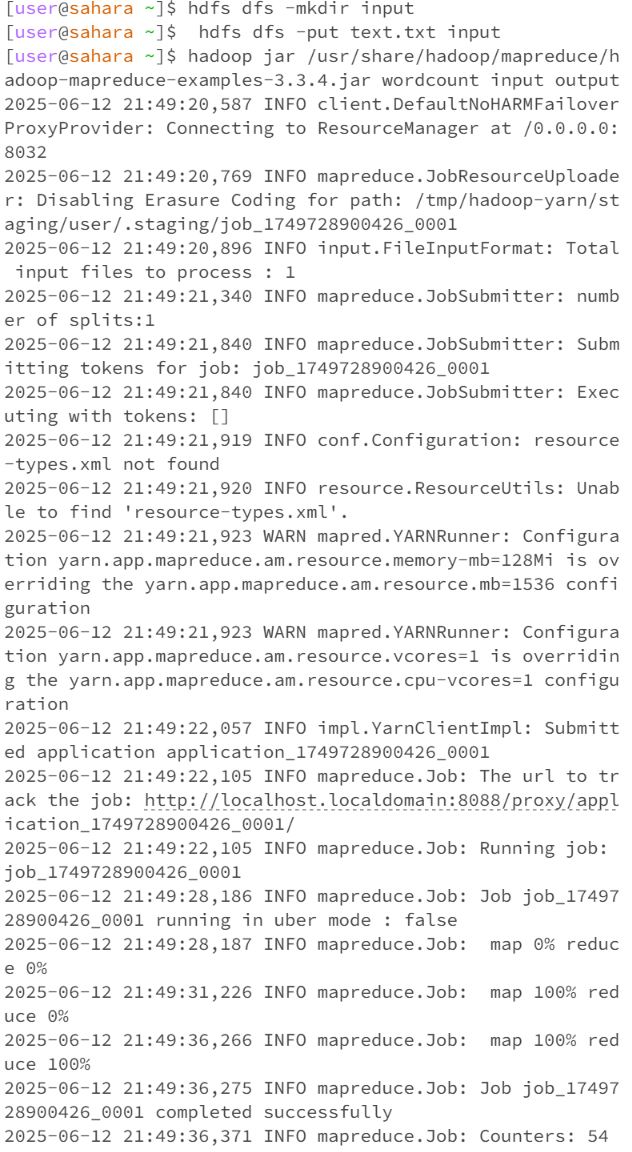
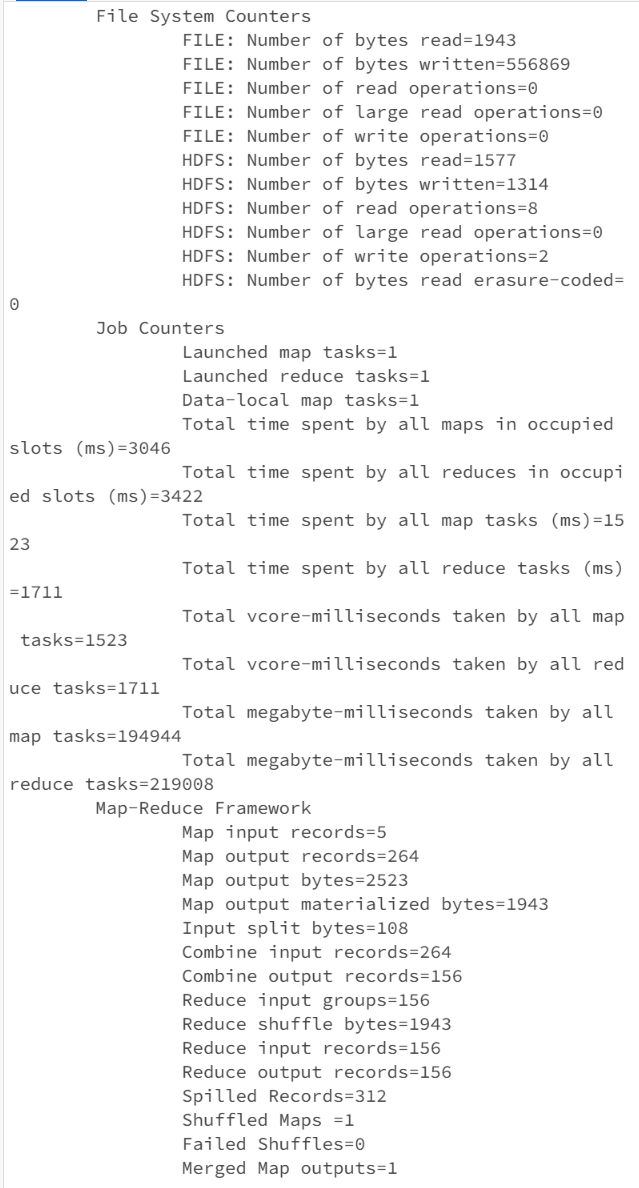
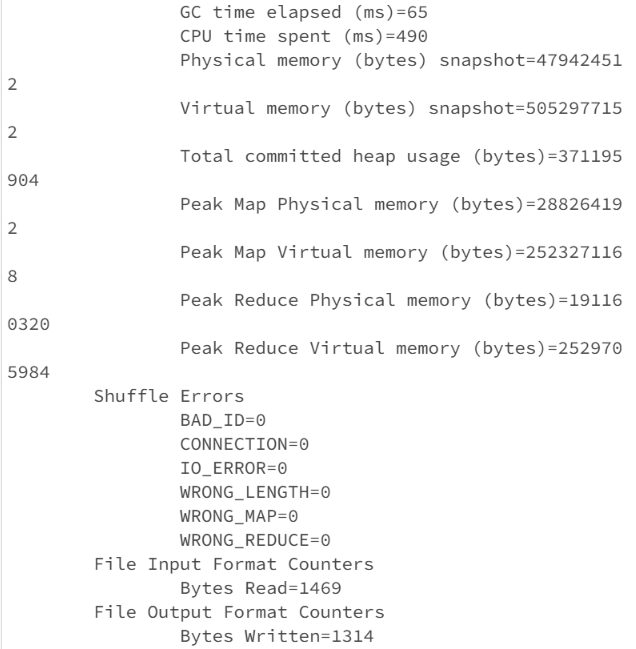

⚠️ 常见错误:输出目录已存在!
如果你再次运行程序,而 output 文件夹还存在,就会报错。
🧹 解决方案一:删掉旧的输出目录
$ hdfs dfs -rm -r output🧳 解决方案二:用新的输出目录
比如:
$ hadoop jar ... wordcount input output2$ hdfs dfs -cat output2/part-*✅ 总结流程图(简化)
Step 1: 启动 Hadoop → start-dfs.sh → start-yarn.shStep 2: 准备数据 → 上传 text.txt 到 HDFS 的 input 文件夹Step 3: 运行程序 → hadoop jar ... wordcount input outputStep 4: 查看结果 → cat output/part-*✅ 一句话总结
Hadoop 的 MapReduce 示例程序(如 wordcount)能在伪分布式模式中运行,读取 HDFS 上的文本文件,统计词频,并将结果保存到 HDFS 的输出目录中。