浙江嘉兴建设局网站seo工具网站
目录
1、进程间通信介绍
进程间通信的概念
进程间通信的本质
进程间通信的分类
2、管道
2.1、什么是管道
2.2、匿名管道
匿名管道的原理
pipe函数
匿名管道使用步骤
2.3、管道的读写规则
2.4、管道的特点
2.5、命名管道
命名管道的原理
使用命令创建命名管道
mkfifo创建命名管道
用命名管道实现server & client间的通信
2.6、匿名管道和命名管道的区别
3、system V共享内存
3.1、共享内存的原理
3.2、共享内存的数据结构
3.3、共享内存函数
shmget创建共享内存
shmctl释放共享内存
shmat关联共享内存
shmdt去关联共享内存
3.4、用共享内存实现serve&client通信
3.5、共享内存与管道进行对比
4、system V IPC联系
临界资源、临界区、原子性、互斥
信号量
IPC资源
1、进程间通信介绍
进程间通信的概念
进程间通信(IPC,Interprocess communication)是一组编程接口,让程序员能够协调不同的进程,使之能在一个操作系统里同时运行,并相互传递、交换信息。 这使得一个程序能够在同一时间里处理许多用户的要求。 因为即使只有一个用户发出要求,也可能导致一个操作系统中多个进程的运行,进程之间必须互相通话。
进程间通信的目的:
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程间通信的本质
进程间通信的本质:让不同的进程看到同一份资源(内存,文件,内核缓冲等)
- 由于各个运行进程之间具有独立性,这个独立性主要体现在数据层面,而代码逻辑层面可以私有也可以公有(例如父子进程),因此各个进程之间要实现通信是非常困难的。
- 各个进程之间若想实现通信,一定要借助第三方资源,这些进程就可以通过向这个第三方资源写入或是读取数据,进而实现进程之间的通信,这个第三方资源实际上就是操作系统提供的一段内存区域。
因此,进程间通信的本质就是,让不同的进程看到同一份资源(内存,文件内核缓冲等)。 由于这份资源可以由操作系统中的不同模块提供,因此出现了不同的进程间通信方式。

进程间通信的分类
管道
- 匿名管道pipe
- 命名管道
System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
2、管道
通信之前,要让不同的进程看到同一份资源(文件,内存块)。我下面谈的进程间通信,不是告诉我们如何通信,而是如何让这两个进程先看到同一份资源。因为资源的不同,会决定不同种类的通信方式,而管道,是提供共享资源的一种手段。
- 如下假设内存中有进程1和进程2,这俩进程想要通信,磁盘上有一个文件,当这俩进程都把这个文件打开的时候,此时就建立了进程1和进程2的一份公共文件,示例:
上述就是一个简单的进程间通信的小测试,但是,我们尽量不要把通信的方式放到外设上(效率低),而是内存级的通信。

2.1、什么是管道
管道是Unix中最古老的进程间通信的形式,我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”。
- 例如我们统计当前使用云服务器上的登录用户个数:
其中,who命令和wc命令都是两个程序,当它们运行起来后就变成了两个进程,who进程通过标准输出将数据打到“管道”当中,wc进程再通过标准输入从“管道”当中读取数据,至此便完成了数据的传输,进而完成数据的进一步加工处理。
- 注意:who命令用于查看当前云服务器的登录用户(一行显示一个用户),wc -l用于统计当前的行数。
现实中的管道是单向的,并且是传输资源的。进程间通信中的管道也是单向的,并且是传输数据的。当要写入的数据量不大于PIPE_BUF(一般是4096字节)时,linux将保证写入的原子性。当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。


2.2、匿名管道
匿名管道的原理
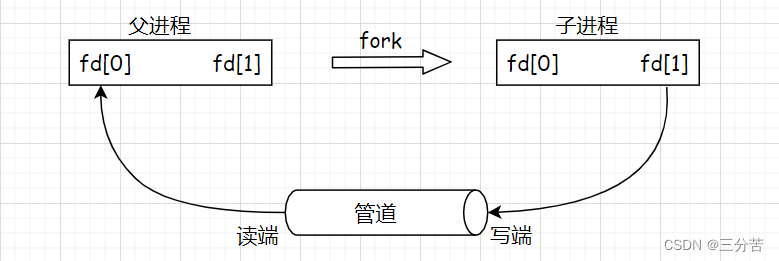
进程间通信的本质就是,让不同的进程看到同一份资源,使用匿名管道实现父子进程间通信的原理就是,让两个父子进程先看到同一份被打开的文件资源,然后父子进程就可以对该文件进行写入或是读取操作,进而实现父子进程间通信。
解释上图:
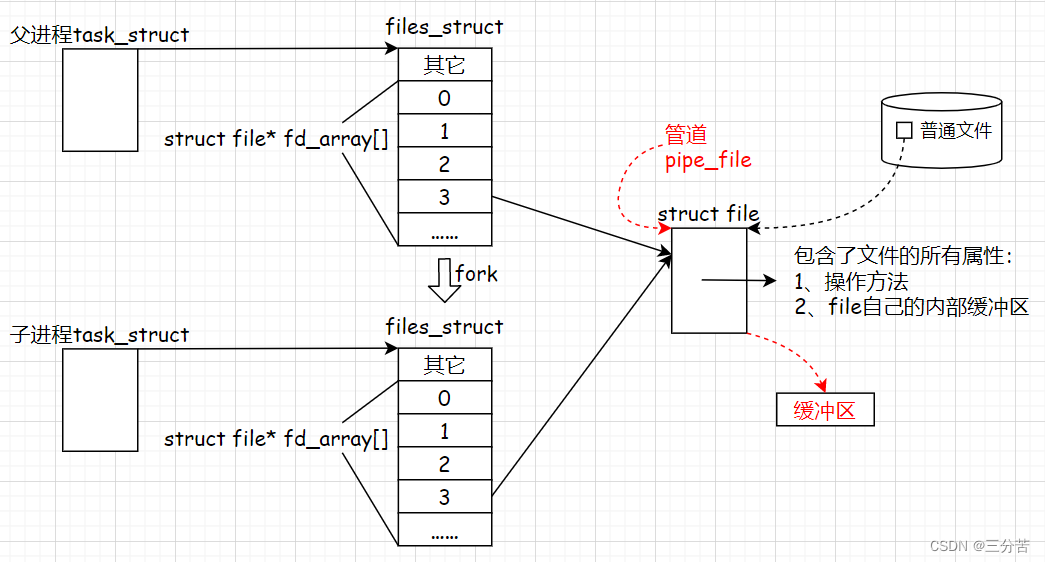
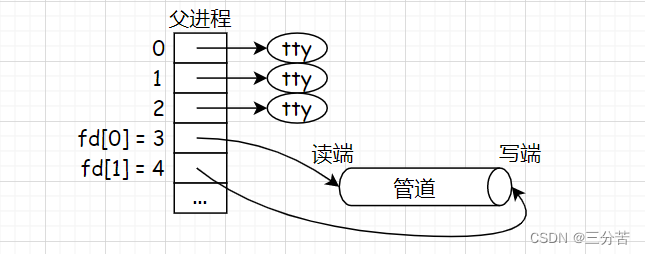
- 我们都清楚一个进程会维护一个文件指针数组,默认打开0,1,2。磁盘要把信息加载到内存上struct file这个结构体里,这里面包含了文件的所有属性,有操作方法和file自己的内部缓冲区,当打开一个文件的时候,进程给它分配文件描述符为3,并指向此struct file。
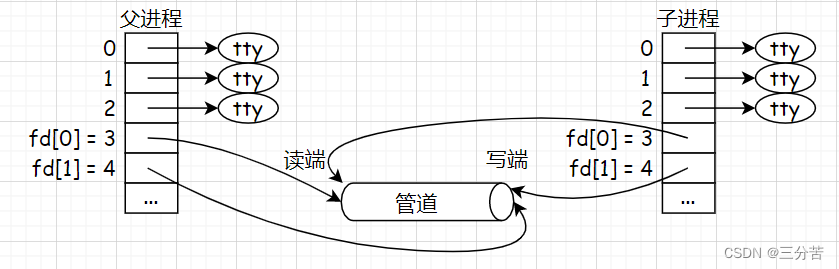
- 此时fork创建子进程,struct file文件不会被拷贝一份,因为创建进程和文件没有关系,而files_struct会被拷贝,因为它属于进程,并拷贝了文件描述符的内容,曾经父进程所打开的文件,子进程也拷贝下来了此映射关系,此时父子进程指向同一份文件,这个文件就是这俩进程的同一份资源,所以我们设计的时候,是普通文件就往磁盘上写,如果是管道文件,就直接往缓冲区写,不要往磁盘上刷新了。
pipe函数
pipe函数用于创建匿名管道,pipe的函数原型如下:
int pipe(int pipefd[2]);pipe函数的参数是一个输出型参数,数组pipefd用于返回两个指向管道读端和写端的文件描述符:
数组元素 含义 pipefd[0] 管道读端的文件描述符 pipefd[1] 管道写端的文件描述符 pipe函数调用成功时返回0,调用失败返回-1。
匿名管道使用步骤
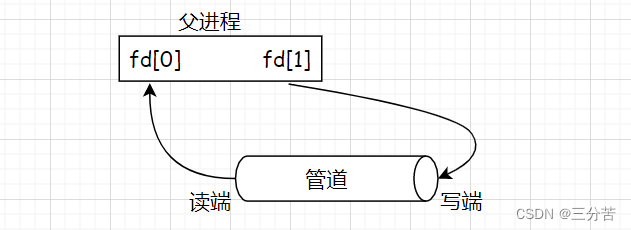
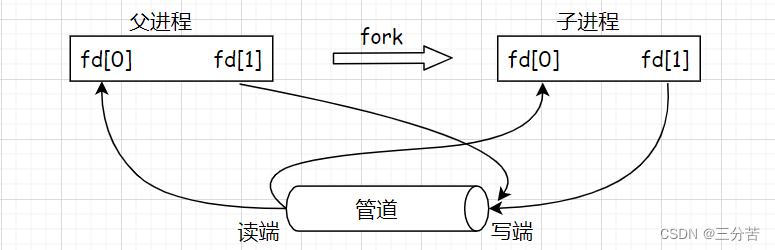
在创建匿名管道实现父子进程间通信的过程中,需要pipe函数和fork函数搭配使用,具体步骤如下:
1、父进程调用pipe函数创建管道
2、父进程fork创建子进程
3、父进程关闭写端,子进程关闭读端
注意:
- 管道只能够进行单向通信,因此当父进程创建完子进程后,需要确认父子进程谁读谁写,然后关闭相应的读写端。
- 从管道写端写入的数据会被内核缓冲,直到从管道的读端被读取。
现在站在文件描述符的角度来看看这三个步骤:
1、父进程调用pipe函数创建管道
2、父进程创建子进程
3、父进程关闭写端,子进程关闭读端
问1:为什么父进程要用两个文件描述符分别打开读端和写端
- 为了让子进程继承,让子进程不用再打开读和写了。
问2:为什么父子要关闭对应的读写端
- 管道必须是单向通信的。
问3:谁来决定父子进程关闭什么读写?
- 不是由管道本身决定的,而是由我们自己的需求决定的。
先来测试一下:
#include<iostream> #include<cstdio> #include<unistd.h> using namespace std; int main() {int pipefd[2] = { 0 };if (pipe(pipefd) != 0){cerr << "pipe error" << endl;return 1;}cout << "fd[0]: " << pipefd[0] << endl;cout << "fd[1]: " << pipefd[1] << endl;return 0; }
现在我们来实现一个管道:
#include<iostream> #include<cstdio> #include<unistd.h> #include<cstring> #include<string> #include<ctime> #include<sys/wait.h> #include<sys/types.h> using namespace std; int main() {//1、创建管道int pipefd[2] = { 0 };if (pipe(pipefd) != 0){cerr << "pipe error" << endl;return 1;}//2、创建子进程pid_t id = fork();if (id < 0){cerr << "fork error" << endl;return 2;}else if (id == 0){//child//子进程进行读取,子进程就应该关闭写端close(pipefd[1]);#define NUM 1024char buffer[NUM];while (true){cout << "时间戳:" << (uint64_t)time(nullptr) << endl;memset(buffer, 0, sizeof(buffer));ssize_t s = read(pipefd[0], buffer, sizeof(buffer) - 1);if (s > 0){//读取成功buffer[s] = '\0';cout << "子进程收到消息,内容是:" << buffer << endl;}else if (s == 0){cout << "父进程写完了,子进程我也退出啦" << endl;break;}else{//Do Nothing}}close(pipefd[0]);exit(0);}else {//parent//父进程进行写入,父进程就应该关闭读端close(pipefd[0]);const char* msg = "你好子进程,我是父进程,这次发送的信息编号是: ";int cnt = 0;while (cnt < 5){char sendBuffer[1024];sprintf(sendBuffer, "%s : %d", msg, cnt);write(pipefd[1], sendBuffer, strlen(sendBuffer));sleep(2); //这里是为了一会儿看现象明显cnt++;}close(pipefd[1]);cout << "父进程写完了" << endl;}pid_t res = waitpid(id, nullptr, 0);if (res > 0){cout << "等待子进程成功" << endl;}return 0; }
问1:当父进程关闭管道的写端,子进程是怎么知道父进程关了的?并且后面还把数据读完就关了呢?
- 父进程创建了子进程之后,在文件对应的属性中有引用计数,表示有多少个指针指向改进程,因此如果引用计数为1,说明该进程只要一个人在用,因此只要这个人读完就代表文件结束了。
问2:父进程是每隔2秒sleep一次,那为什么子进程没有进行sleep,但读取节奏却和父进程一样呢?
- 因为当父进程没有写入数据的时候,子进程在等待。所以,当父进程写入之后,子进程才能read(会返回)到数据,子进程打印读取数据要以父进程的节奏为主。
因此,父进程和子进程在读写的时候,是有一定的顺序性的。
- 管道内部,没有数据的时候,reader就必须阻塞等待(将当前进程的take_struct放入等待队列中),等待管道有数据;如果数据被写满,writer就必须阻塞等待,等待管道中有空间。不过呢,在父子进程各自printf的时候(向显示器写入【显示器也是文件】),并没有什么顺序,因为缺乏访问控制。而管道内部是有顺序的,因为它自带访问控制机制,同步和互斥机制。
再来实现一个进程控制,让父进程通过管道控制子进程,让子进程去做事情:
#include <iostream> #include <cstdio> #include <unistd.h> #include <cstring> #include <string> #include <vector> #include <unordered_map> #include <ctime> #include <cstdlib> #include <sys/wait.h> #include <sys/types.h> #include <cassert> using namespace std;typedef void (*functor)(); vector<functor> functors; // 方法集合// for debug unordered_map<uint32_t, string> info; void f1() {cout << "这是一个处理日志的任务,执行的进程 ID [" << getpid() << "]"<< "执行时间是[" << time(nullptr) << "]" << endl; } void f2() {cout << "这是一个备份数据的任务,执行的进程 ID [" << getpid() << "]"<< "执行时间是[" << time(nullptr) << "]" << endl; } void f3() {cout << "这是一个处理网络连接的任务,执行的进程 ID [" << getpid() << "]"<< "执行时间是[" << time(nullptr) << "]" << endl; }void loadFunctor() {info.insert({functors.size(), "处理日志的任务"});functors.push_back(f1);info.insert({functors.size(), "备份数据的任务"});functors.push_back(f2);info.insert({functors.size(), "处理网络连接的任务"});functors.push_back(f3); }int main() {// 0、加载任务列表loadFunctor();// 1、创建管道int pipefd[2] = {0};if (pipe(pipefd) != 0){cerr << "pipe error" << endl;return 1;}// 2、创建子进程pid_t id = fork();if (id < 0){cerr << " fork error " << endl;return 2;}else if (id == 0){// 3、关闭不需要的文件fd// child —— readclose(pipefd[1]);// 4、业务处理while (true){uint32_t operatorType = 0;//如果有数据,就读取,如果没有数据,就阻塞等待,等待任务的到来ssize_t s = read(pipefd[0], &operatorType, sizeof(uint32_t));if (s == 0){cout << "我要退出啦,我是给人打工的,老板都走了. . ." << endl;break;}assert(s == sizeof(uint32_t));//assert断言,编译有效 debug模式//release 模式,断言就没有了//一旦断言没有了,s变量就是只被定义了,没有被使用。release模式中,可能会有warning(void)s;if (operatorType < functors.size()){functors[operatorType]();}else{cerr << "bug? operatorType = " << operatorType << endl;;}}close(pipefd[0]);exit(0);}else{srand((long long)time(nullptr));// 3、关闭不需要的文件fd// parent —— writeclose(pipefd[0]);// 4、指派任务int num = functors.size();int cnt = 10;while (cnt--){// 5、形成任务码uint32_t commandCode = rand() % num;cout << "父进程指派任务完成,任务是:" << info[commandCode] << "任务的编号是:" << cnt << endl;// 向指定的进程下达任务的操作write(pipefd[1], &commandCode, sizeof(uint32_t));sleep(1);}close(pipefd[1]);pid_t res = waitpid(id, nullptr, 0);if (res)cout << "wait success" << endl;}return 0; }
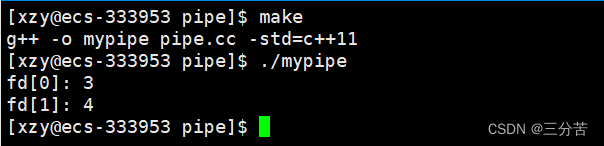
上述操作实现了让父进程去控制一个进程,那么如何让父进程控制一批进程呢?
- 假设现在想让父进程控制3个进程,那么我可以创建三个管道,让每一个进程都和父进程建立管道,父进程向指派进程1,那就往进程1的管道去写,向指派进程2,就往进程2的管道去写……。此时我的主进程就相当于分配业务的进程,这些子进程就相当于是执行业务的进程。我们基于上述的策略其实就是利用的进程池。
代码如下:
#include <iostream> #include <cstdio> #include <unistd.h> #include <cstring> #include <string> #include <vector> #include <unordered_map> #include <ctime> #include <cstdlib> #include <sys/wait.h> #include <sys/types.h> #include <cassert> using namespace std;typedef void (*functor)(); vector<functor> functors; // 方法集合// for debug unordered_map<uint32_t, string> info; void f1() {cout << "这是一个处理日志的任务,执行的进程 ID [" << getpid() << "]"<< "执行时间是[" << time(nullptr) << "]\n" << endl; } void f2() {cout << "这是一个备份数据的任务,执行的进程 ID [" << getpid() << "]"<< "执行时间是[" << time(nullptr) << "]\n" << endl; } void f3() {cout << "这是一个处理网络连接的任务,执行的进程 ID [" << getpid() << "]"<< "执行时间是[" << time(nullptr) << "]\n" << endl; }void loadFunctor() {info.insert({functors.size(), "处理日志的任务"});functors.push_back(f1);info.insert({functors.size(), "备份数据的任务"});functors.push_back(f2);info.insert({functors.size(), "处理网络连接的任务"});functors.push_back(f3); }//int32_t: 进程pid,int32_t: 该进程对应的管道写端fd typedef pair<int32_t, int32_t> elem; int processNum = 5;//设置子进程的个数为5void work(int blockFd) {cout << "进程[" << getpid() << "]" << "开始工作" << endl;//子进程核心工作的代码while (true){//a.阻塞等待 b.获取任务信息uint32_t operatorCode = 0;ssize_t s = read(blockFd, &operatorCode, sizeof(uint32_t));if (s == 0) break;assert(s == sizeof(uint32_t));(void)s;//c.处理任务if (operatorCode < functors.size()){functors[operatorCode]();}}cout << "进程[" << getpid() << "]" << "结束工作" << endl; }//pair的结构:[子进程的pid,子进程的管道fd] void blanceSendTask(const vector<elem>& processFds) {srand((long long)time(nullptr));while (true){sleep(1);//选择一个进程,选择进程是随机的,这里没有压着一个进程给任务//较为均匀的将任务给所有的子进程 —— 负载均衡uint32_t pick = rand() % processFds.size();//选择一个任务uint32_t task = rand() % functors.size();//把任务给一个指定的进程write(processFds[pick].second, &task, sizeof(task));//打印对应的提示信息cout << "父进程指派任务->" << info[task] << "给进程: " << processFds[pick].first << "编号: " << pick << endl;} } int main() { loadFunctor();vector<elem> assignMap;//创建processNum个进程for (int i = 0; i < processNum; i++){//定义保存管道fd的对象int pipefd[2] = { 0 };//创建管道pipe(pipefd);//创建子进程pid_t id = fork();if (id == 0){//子进程读取, r -> pipefd[0]close(pipefd[1]);//子进程执行work(pipefd[0]);close(pipefd[0]);exit(0);}//父进程做的事情, w -> pipefd[1]close(pipefd[0]);elem e(id, pipefd[1]);assignMap.push_back(e);}cout << "create all process success!" << endl;//父进程,派发任务blanceSendTask(assignMap);//回收资源for (int i = 0; i < processNum; i++){if (waitpid(assignMap[i].first, nullptr, 0) > 0) {cout << "wait for: pid=" << assignMap[i].first << "wait success!"<< "nummber: " << i << endl;}close(assignMap[i].second);}return 0; }我们写一个如下的监控脚本来辅助观察现象:
[xzy@ecs-333953 pipe]$ while :; do ps ajx | head -1 && ps ajx | grep mypipe |grep -v grep ; sleep 1; done
问:我曾经在命令行中写的 | 管道是什么意思呢?
- 看如下的测试:
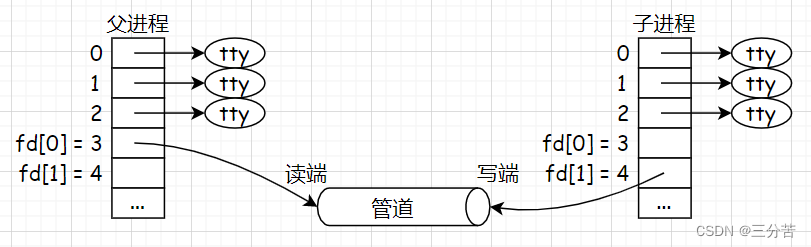
- 如上我通过 | 链接形成了10000和2000这俩进程,并写了一段监控脚本。通过观察可以看到,这俩进程的PID各不相同,但是PPID是相同的,所以这俩进程是兄弟关系。此时这俩进程指向的读端和写端是相同的,因此可以让父进程不再进行操作,就从父子通信转换成了兄弟通信,就相当于两个子进程共享了一个管道。综上,命令行中的 | 就是一种匿名管道。




2.3、管道的读写规则
1、当没有数据可读时
- O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止。
- O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
2、当管道满的时候
- O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
- O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
3、如果所有管道写端对应的文件描述符被关闭,则read返回0
4、如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
5、当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
6、当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
2.4、管道的特点
1、管道只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信;常用于父子间通信,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道。
2、管道只能单向通信(内核的实现所决定),是半双工的一种特殊情况
在数据通信中,数据在线路上的传送方式可以分为以下三种:
- 单工通信(Simplex Communication):单工模式的数据传输是单向的。通信双方中,一方固定为发送端,另一方固定为接收端。
- 半双工通信(Half Duplex):半双工数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。
- 全双工通信(Full Duplex):全双工通信允许数据在两个方向上同时传输,它的能力相当于两个单工通信方式的结合。全双工可以同时(瞬时)进行信号的双向传输。
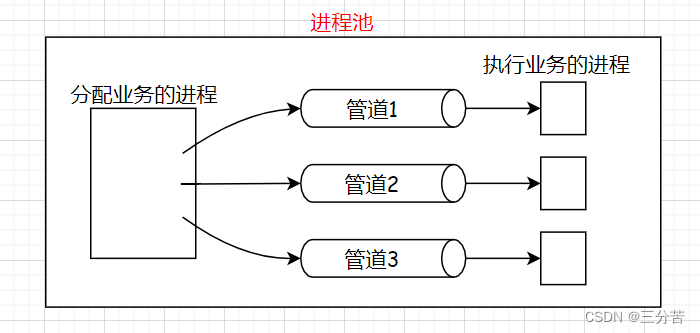
管道是半双工的,数据只能向一个方向流动,需要双方通信时,要建立起两个管道:
3、管道自带同步互斥机制(pipe满,writer等;pipe空,reader等) —— 自带访问控制
我们将一次只允许一个进程使用的资源,称为临界资源。管道在同一时刻只允许一个进程对其进行写入或是读取操作,因此管道也就是一种临界资源。临界资源是需要被保护的,若是我们不对管道这种临界资源进行任何保护机制,那么就可能出现同一时刻有多个进程对同一管道进行操作的情况,进而导致同时读写、交叉读写以及读取到的数据不一致等问题。为了避免这些问题,内核会对管道操作进行同步与互斥:
- 同步: 两个或两个以上的进程在运行过程中协同步调,按预定的先后次序运行。比如,A任务的运行依赖于B任务产生的数据。
- 互斥: 一个公共资源同一时刻只能被一个进程使用,多个进程不能同时使用公共资源。
实际上,同步是一种更为复杂的互斥,而互斥是一种特殊的同步。对于管道的场景来说,互斥就是两个进程不可以同时对管道进行操作,它们会相互排斥,必须等一个进程操作完毕,另一个才能操作,而同步也是指这两个不能同时对管道进行操作,但这两个进程必须要按照某种次序来对管道进行操作。也就是说,互斥具有唯一性和排它性,但互斥并不限制任务的运行顺序,而同步的任务之间则有明确的顺序关系。
4、管道的生命周期随进程
- 管道本质上是通过文件进行通信的,也就是说管道依赖于文件系统,那么当所有打开该文件的进程都退出后,该文件也就会被释放掉,所以说管道的生命周期随进程。
5、管道是面向字节流的 —— 先写的字符,一定是先被读取的,没有格式边界,需要用户来定义区分内容的边界
2.5、命名管道
命名管道的原理
匿名管道只能用于具有共同祖先的进程(具有亲缘关系的进程)之间的通信,通常,一个管道由一个进程创建,然后该进程调用fork,此后父子进程之间就可应用该管道。如果要实现两个毫不相关进程之间的通信,可以使用命名管道来做到。命名管道就是一种特殊类型的文件,两个进程通过命名管道的文件名打开同一个管道文件,此时这两个进程也就看到了同一份资源,进而就可以进行通信了。
注意:
- 普通文件是很难做到通信的,即便做到通信也无法解决一些安全问题。
- 命名管道和匿名管道一样,都是内存文件,只不过命名管道在磁盘有一个简单的映像,但这个映像的大小永远为0,因为命名管道和匿名管道都不会将通信数据刷新到磁盘当中。
使用命令创建命名管道
我们可以使用mkfifo命令创建一个命名管道
使用如下:
如上可以看到,创建出来的文件类型是p,代表该文件是命名管道文件。
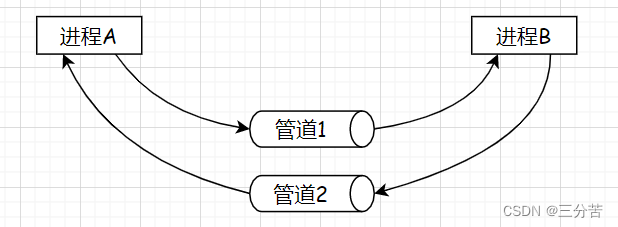
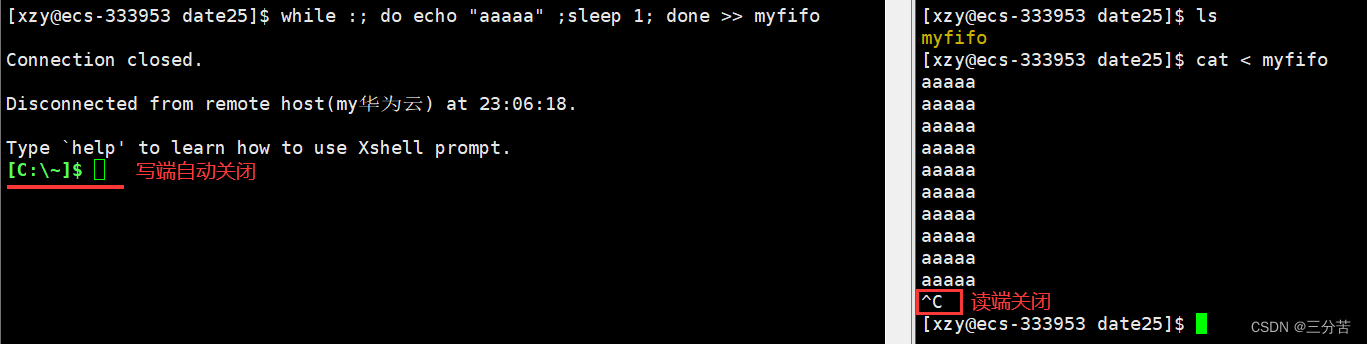
- 使用这个命名管道文件,就能实现两个进程之间的通信了。我们在一个进程(进程A)中用shell脚本每秒向命名管道写入一个字符串,在另一个进程(进程B)当中用cat命令从命名管道当中进行读取。现象就是当进程A启动后,进程B会每秒从命名管道中读取一个字符串打印到显示器上。这就证明了这两个毫不相关的进程可以通过命名管道进行数据传输,即通信。
之前我们说过,当管道的读端进程退出后,写端进程再向管道写入数据就没有意义了,此时写端进程会被操作系统杀掉,在这里就可以很好的得到验证:当我们终止掉读端进程后,因为写端执行的循环脚本是由命令行解释器bash执行的,所以此时bash就会被操作系统杀掉,我们的云服务器也就退出了。


mkfifo创建命名管道
在程序中创建命名管道使用mkfifo函数,mkfifo函数的函数原型如下:
int mkfifo(const char *pathname, mode_t mode);mkfifo的第一个参数pathname,表示要创建的命名管道文件。
- 若pathname以路径的方式给出,则将命名管道文件创建在pathname路径下。
- 若pathname以文件名的方式给出,则将命名管道文件默认创建在当前路径下。(注意当前路径的含义)
mkfifo的第二个参数mode,表示创建命名管道文件的默认权限。
mkfifo函数的返回值:
- 命名管道创建成功,返回0。
- 命名管道创建失败,返回-1。
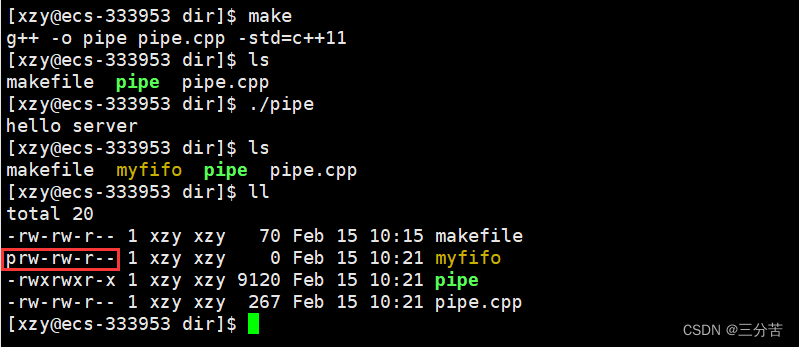
#include<iostream> using namespace std; #include<sys/types.h> #include<sys/stat.h> #define FILE_NAME "myfifo" int main() {if (mkfifo(FILE_NAME, 0666) < 0){cerr << "mkfifo error" << endl;return 1;}//create successcout << "hello world" << endl; }例如,上述将mode设置为0666,但命名管道创建出来的权限如下:
实际上创建出来文件的权限值还会受到umask(文件默认掩码)的影响,实际创建出来文件的权限为:mode&(~umask)。umask的默认值一般为0002,当我们设置mode值为0666时实际创建出来文件的权限为0664。若想创建出来命名管道文件的权限值不受umask的影响,则需要在创建文件前使用
umask函数将文件默认掩码设置为0。umask(0); //将文件默认掩码设置为0
用命名管道实现server & client间的通信
实现服务端(server)和客户端(client)之间的通信之前,我们需要先让服务端运行起来,让服务端运行后创建一个命名管道文件,然后再以读的方式打开该命名管道文件,之后服务端就可以从该命名管道当中读取客户端发来的通信信息了。
- 注意:如果一个进程已经把文件创建好了,那么另一个进程不需要创建这个文件了,直接用就可以了
server服务端代码如下:
//读取 #include"comm.h" using namespace std; int main() {umask(0);//将文件默认掩码设置为0if (mkfifo(IPC_PATH, 0600) != 0){cerr << "mkfifo error" << endl;return 1;}int pipefd = open(IPC_PATH, O_RDONLY);//以读的方式打开命名管道文件if (pipefd < 0){cerr << "open fifo error" << endl;return 2;}//正常的通信过程#define NUM 1024char buffer[NUM];while (true){ssize_t s = read(pipefd, buffer, sizeof(buffer) - 1);if (s > 0){buffer[s] = '\0';//手动设置'\0',便于输出cout << "客户端->服务器# " << buffer << endl;//输出客户端发来的信息}else if (s == 0){cout << "客户退出啦,我也退出啦" << endl;break;}else{//do nothingcout << "read: " << strerror(errno) << endl;break;}}close(pipefd);cout << "服务端退出啦" << endl;unlink(IPC_PATH);//通信完毕后,自动帮我们删除管道文件return 0; }
- 接着再将客户端也运行起来,此时我们从客户端写入的信息被客户端写入到命名管道当中,服务端再从命名管道当中将信息读取出来打印在服务端的显示器上,该现象说明服务端是能够通过命名管道获取到客户端发来的信息的,换句话说,此时这两个进程之间是能够通信的。
client客户端代码如下:
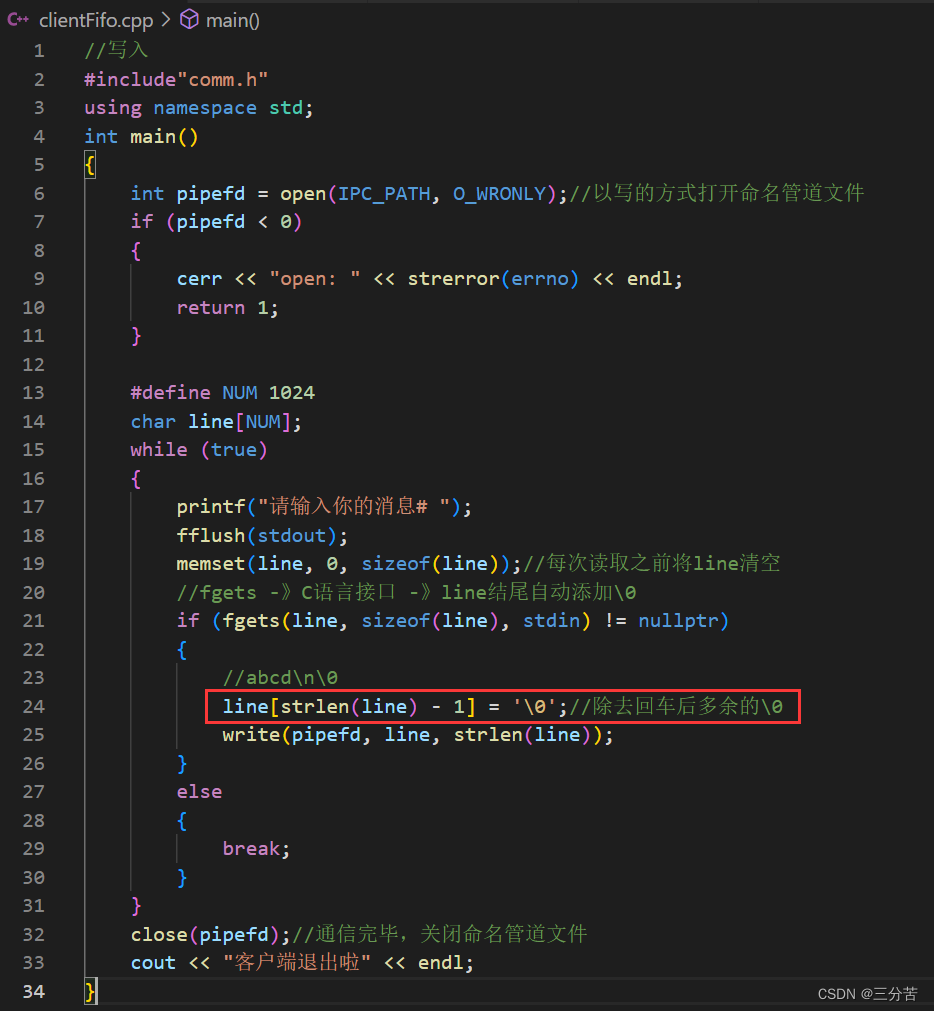
//写入 #include"comm.h" using namespace std; int main() {int pipefd = open(IPC_PATH, O_WRONLY);//以写的方式打开命名管道文件if (pipefd < 0){cerr << "open: " << strerror(errno) << endl;return 1;}#define NUM 1024char line[NUM];while (true){printf("请输入你的消息# ");fflush(stdout);memset(line, 0, sizeof(line));//每次读取之前将line清空//fgets -》C语言接口 -》line结尾自动添加\0if (fgets(line, sizeof(line), stdin) != nullptr){//abcd\n\0line[strlen(line) - 1] = '\0';//除去回车后多余的\0write(pipefd, line, strlen(line));}else {break;}}close(pipefd);//通信完毕,关闭命名管道文件cout << "客户端退出啦" << endl; }
- 对于如何让客户端和服务端使用同一个命名管道文件,这里我们可以让客户端和服务端包含同一个头文件,该头文件当中提供这个共用的命名管道文件的文件名,这样客户端和服务端就可以通过这个文件名,打开同一个命名管道文件,进而进行通信了。
comm.h头文件代码如下:
#pragma once #include<iostream> #include<string> #include<sys/types.h> #include<sys/stat.h> #include<fcntl.h> #include<unistd.h> #include<cstring> #include<cerrno> #include<cstdio>#define IPC_PATH "./.fifo"makefile文件代码如下:
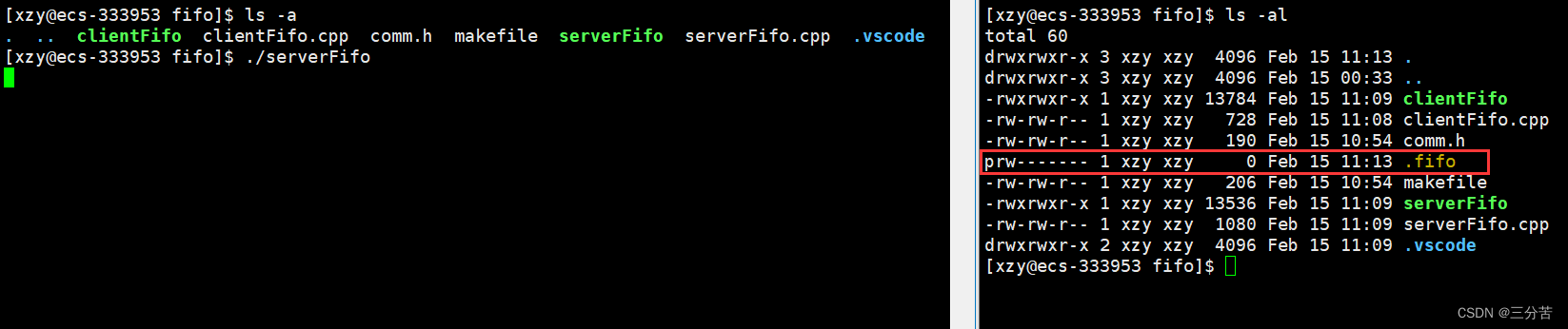
.PHONY:all all: clientFifo serverFifo clientFifo:clientFifo.cppg++ -Wall -o $@ $^ -std=c++11 serverFifo:serverFifo.cppg++ -Wall -o $@ $^ -std=c++11 .PHONY:clean clean:rm -f clientFifo serverFifo .fifo此时我运行创建好的serverFifo可执行程序,可以看到创建好的.pipe管道文件:
此时再运行clientFifo可执行程序,并观察俩进程的pid和ppid的关系:
此时发现,进程serverFifo和进程clientFifo的pid和ppid完全没有关系,现在对这俩毫无关系的进程之间进行通信:
这里我们可以看到服务器端多了个空行,这是因为我们在输入完后会按回车键,就相当于多传输了一个\n,因此我们可以这样处理:
现在就显示正常了:

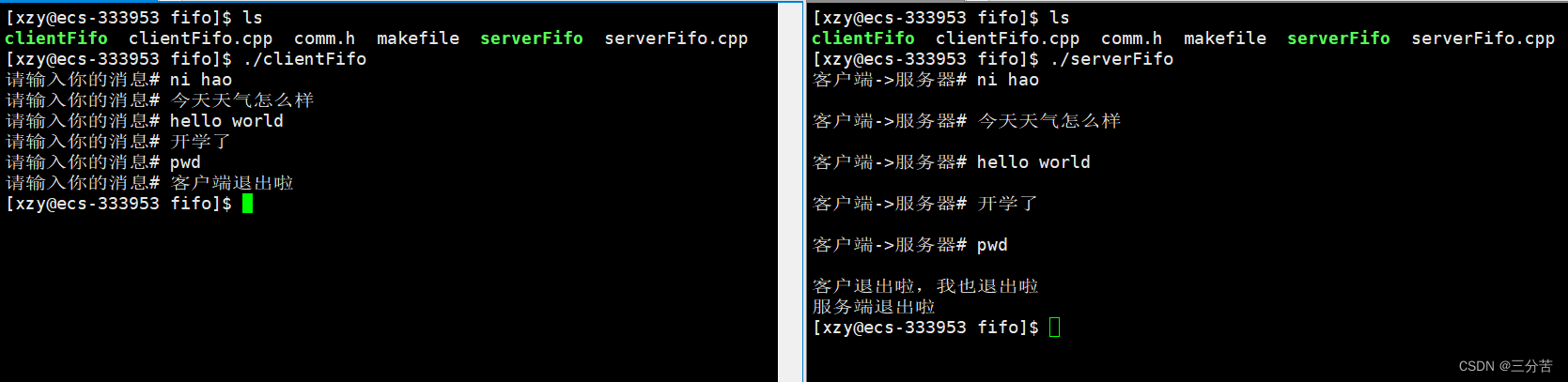

2.6、匿名管道和命名管道的区别
- 匿名管道:子进程继承父进程。由pipe函数创建并打开。
- 命名管道:通过一个fifo文件(有路径,具有唯一性),通过路径找到同一个资源。由mkfifo函数创建,由open函数打开。
- FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在于它们创建与打开的方式不同,一旦这些工作完成之后,它们具有相同的语义。
3、system V共享内存
3.1、共享内存的原理
共享内存让不同进程看到同一份资源的方式就是,通过一种接口在物理内存当中申请一块内存空间,然后通过此接口将这块内存空间分别与各个进程各自的页表之间建立映射,再在虚拟地址空间当中开辟空间并将虚拟地址填充到各自页表的对应位置,使得虚拟地址和物理地址之间建立起对应关系,至此这些进程便看到了同一份物理内存,这块物理内存就叫做共享内存。
注意:
这里所说的开辟物理空间、建立映射等操作都是调用系统接口完成的,也就是说这些动作都由操作系统来完成。所以操作系统需要提供具有如下功能的接口:
- 创建共享内存 —— 删除共享内存(OS内部帮我们做)
- 关联共享内存 —— 去关联共享内存(进程做,实际也是OS做)
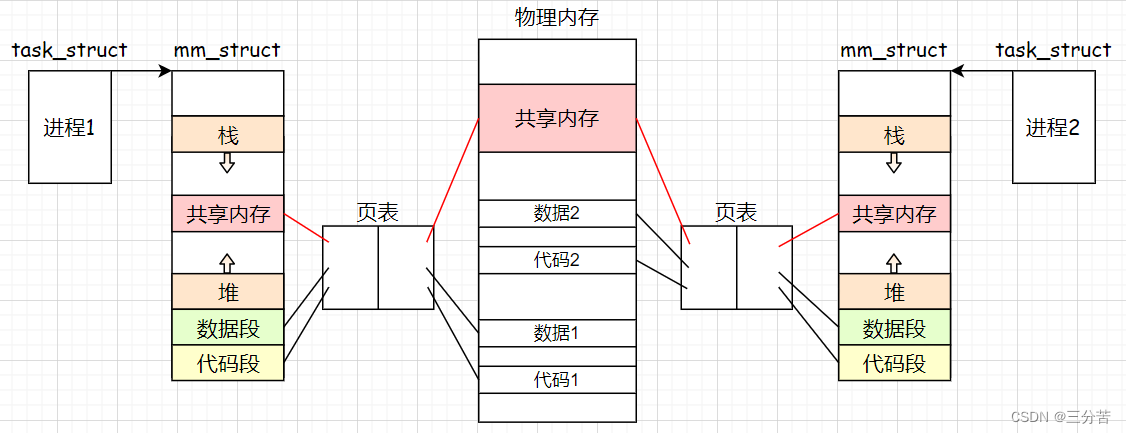
3.2、共享内存的数据结构
在系统当中可能会有大量的进程在进行通信,因此系统当中就可能存在大量的共享内存,那么操作系统必然要对其进行管理,所以共享内存除了在内存当中真正开辟空间之外,系统一定还要为共享内存维护相关的内核数据结构。共享内存的数据结构如下:
struct shmid_ds {struct ipc_perm shm_perm; /* operation perms */int shm_segsz; /* size of segment (bytes) */__kernel_time_t shm_atime; /* last attach time */__kernel_time_t shm_dtime; /* last detach time */__kernel_time_t shm_ctime; /* last change time */__kernel_ipc_pid_t shm_cpid; /* pid of creator */__kernel_ipc_pid_t shm_lpid; /* pid of last operator */unsigned short shm_nattch; /* no. of current attaches */unsigned short shm_unused; /* compatibility */void* shm_unused2; /* ditto - used by DIPC */void* shm_unused3; /* unused */ };
3.3、共享内存函数
shmget创建共享内存
创建共享内存我们需要使用shmget函数,shmget函数的原型如下:
#include <sys/ipc.h> #include <sys/shm.h> int shmget(key_t key, size_t size, int shmflg);shmget函数的参数说明:
- key:表示待创建共享内存在系统中的唯一标识
- size:表示带创建共享内存的大小(建议设置为页[4KB]的整数倍)
- shmflg:表示创建共享内存的方式
shmget函数的返回值说明:
- shmget调用成功,返回一个有效的共享内存标识符(用户层标识符)
- shmget调用失败,返回-1
着重强调size:
- 上面说到size要设置为页(4KB)的整数倍,我们假设有4GB的空间,约等于2^20次方个页,对于这么多页,操作系统需要把共享内存上的这么多页管理起来,依旧是先描述,再组织,OS内部用数组的方式将页保存了起来(struct page mem[2^20])。
着重强调shmflg:
- 当创建共享内存的时候,OS需要在物理内存中申请如上的物理页(struct page……)。在申请的时候可能会面临如下的问题:此共享内存该由谁创建呢?如果你创建好了,那我该怎么办?如果底层存在,我该怎么办?针对上述问题,就由shmget函数的第三个参数shmflg来解决:
shmflg有两个常见的选项(IPC_CREAT和IPC_EXCL)
组合方式 作用 IPC_CREAT 如果内核中不存在键值与key相等的共享内存,则新建一个共享内存并返回该共享内存的句柄;
如果存在这样的共享内存,则直接返回该共享内存的句柄。
IPC_CREAT |
IPC_EXCL
IPC_CREAT不能单独使用,必须和IPC_CREAT配合,如果不存在键值与key相等的共享内存,则新建一个共享内存并返回该共享内存的句柄;
如果存在这样的共享内存,则出错返回。
换句话说:
- 使用组合IPC_CREAT,一定会获得一个共享内存的句柄,但无法确认该共享内存是否是新建的共享内存。
- 使用组合IPC_CREAT | IPC_EXCL,只有shmget函数调用成功时才会获得共享内存的句柄,并且该共享内存一定是新建的共享内存。
着重强调key:
- 共享内存是存在内核中的,内核会给我们维护共享内存的结构。共享内存需要被管理,依旧是先描述,再组织。于是乎就和我们上文谈到的共享内存的数据结构串联起来了,此结构就是struct shmid_ds[ ],里面维护了各种属性:
struct shmid_ds {struct ipc_perm shm_perm; /* operation perms */int shm_segsz; /* size of segment (bytes) */__kernel_time_t shm_atime; /* last attach time */__kernel_time_t shm_dtime; /* last detach time */__kernel_time_t shm_ctime; /* last change time */__kernel_ipc_pid_t shm_cpid; /* pid of creator */__kernel_ipc_pid_t shm_lpid; /* pid of last operator */unsigned short shm_nattch; /* no. of current attaches */unsigned short shm_unused; /* compatibility */void* shm_unused2; /* ditto - used by DIPC */void* shm_unused3; /* unused */ };
- 可以看到上面共享内存数据结构的第一个成员是shm_perm,shm_perm是一个ipc_perm类型的结构体变量,每个共享内存的key值存储在shm_perm这个结构体变量当中,其中ipc_perm结构体的定义如下:
struct ipc_perm {key_t __key; /* Key supplied to shmget(2) */uid_t uid; /* Effective UID of owner */gid_t gid; /* Effective GID of owner */uid_t cuid; /* Effective UID of creator */gid_t cgid; /* Effective GID of creator */unsigned short mode; /* Permissions + SHM_DEST and SHM_LOCKED flags */unsigned short __seq; /* Sequence number */ };
- ipc_perm结构体的第一个成员key就是标识共享内存唯一性的方法,这个key一般由用户提供。综上,我们是否知道共享内存存在与否就取决于这个key方法。
问:为什么此key值得由用户提供呢?
- 假设通信的进程为client和server进程,如果key值由用户提供,那么server就可以提供一个key值让操作系统帮他创建一个进程,并约定好让client也使用同样的key值,访问此共享内存。进程间通信的前提是让不同的进程看到同一份资源。综上:共享内存在内核中,想让不同的进程看到同一份共享内存,做法就是让他们拥有同一个key即可。
那么我们如何能拥有与之前不同的key值呢,这就需要用到 ftok 函数来获取key值。ftok函数的原型如下:
#include <sys/types.h> #include <sys/ipc.h> key_t ftok(const char* pathname, int proj_id);ftok函数的作用就是,将一个已存在的路径名pathname和一个整数标识符proj_id转换成一个key值,称为IPC键值,在使用shmget函数获取共享内存时,这个key值会被填充进维护共享内存的数据结构当中。需要注意的是,pathname所指定的文件必须存在且可存取。
注意:
- 使用ftok函数生成key值可能会产生冲突,此时可以对传入ftok函数的参数进行修改。
- 需要进行通信的各个进程,在使用ftok函数获取key值时,都需要采用同样的路径名和和整数标识符,进而生成同一种key值,然后才能找到同一个共享资源。
至此我们就可以使用ftok和shmget函数创建一块共享内存了,创建后我们可以将共享内存的key值和句柄进行打印,以便观察,代码如下:
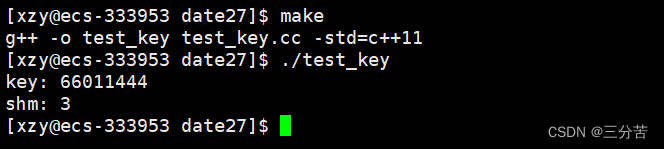
#include <iostream> #include <sys/types.h> #include <sys/ipc.h> #include <sys/shm.h> #include <unistd.h> using namespace std;#define PATH_NAME "/home/xzy/dir/date27" //路径名 #define PROJ_ID 0x6666 //整数标识符 #define SIZE 4096 //共享内存的大小int main() {key_t key = ftok(PATH_NAME, PROJ_ID); //获取key值if (key < 0) {perror("ftok");return 1;}int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL); //创建新的共享内存if (shm < 0) {perror("shmget");return 2;}printf("key: %x\n", key); //打印key值printf("shm: %d\n", shm); //打印句柄return 0; }
来看如下的一个测试代码:
头文件Comm.hpp:
#pragma once #include<iostream> #include<sys/types.h> #include<sys/ipc.h> #include<sys/shm.h> #include<cstdlib> #include<cstring> #include<cerrno> using namespace std;#define PATH_NAME "/home/xzy/dir/date26" //路径名 #define PROJ_ID 0x14 //整数标识符 #define MEM_SIZE 4096//共享内存的大小//创建key值 key_t CreateKey() {key_t key = ftok(PATH_NAME, PROJ_ID);if (key < 0){cerr << "ftok:" << strerror(errno) << endl;exit(1);}return key; }Log.hpp:
#pragma once #include<iostream> #include<ctime>std::ostream &Log() {std::cout << "Fot Debug | " << " timestamp: " << (uint64_t)time(nullptr) << " | ";return std::cout; }创建共享内存:IpcShmSer.cc
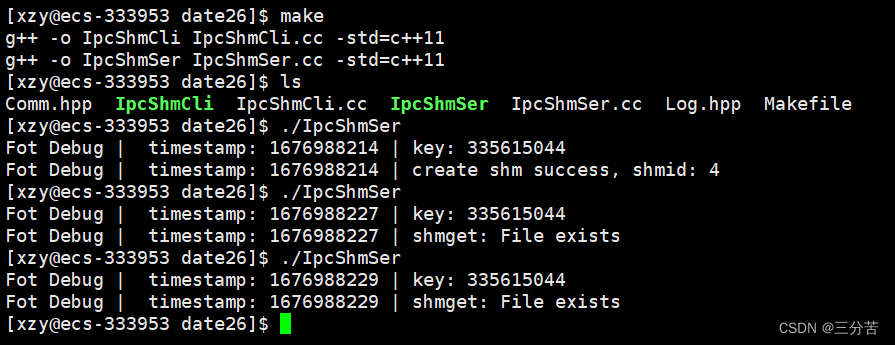
#include "Comm.hpp" #include "Log.hpp" // 充当创建共享内存的角色//我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; int main() {key_t key = CreateKey();Log() << "key: " << key << endl;int shmid = shmget(key, MEM_SIZE, flags);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}Log() << "create shm success, shmid: " << shmid << endl;return 0; }使用共享内存:IpcShmCli.cc
#include"Comm.hpp" #include"Log.hpp" //充当使用共享内存的角色 int main() {key_t key = CreateKey();Log() << "key: " << key << endl;return 0; }结果如下:
当我们运行完毕创建全新的共享内存的代码后(进程退出了),但是在第二(n)次的时候,该代码无法运行,告诉我们file存在(共享内存是存在的)。因此system V下的共享内存,其生命周期是随内核的(管道的生命周期是随进程的)。共享内存如果不显示删除,只能通过OS重启来解决。具体删除的方法见下文。
shmctl释放共享内存
此时我们若是要将创建的共享内存释放,有两个方法,一就是使用命令释放共享内存,二就是在进程通信完毕后调用释放共享内存的函数进行释放。
法一:使用命令释放共享内存
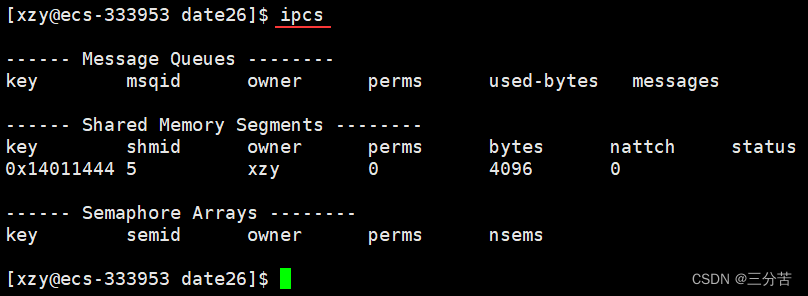
在Linux中,我们可以使用 ipcs 命令查看有关进程间通信设施的信息。
单独使用 ipcs 命令时,会默认列出消息队列,共享内存以及信号量相关的信息,若指向查看他们之间某一个的相关信息,可以选择携带以下选项:
- -q:列出消息队列相关信息。
- -m:列出共享内存相关信息。
- -s:列出信号量相关信息。
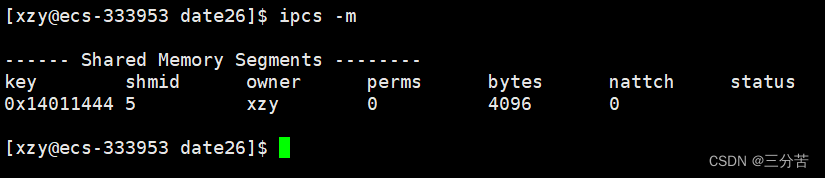
例如,携带-m选项查看共享内存相关信息:
此时,根据
ipcs命令的查看结果和我们的输出结果可以确认,共享内存已经创建成功了。ipcs命令输出的每列信息的含义如下:
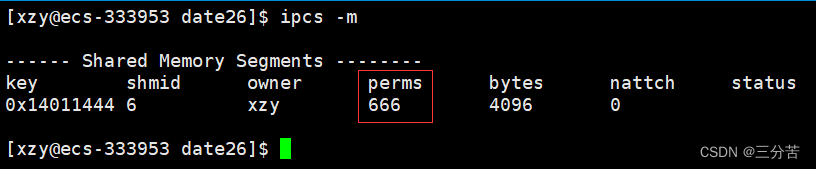
标题 含义 key 系统区别各个共享内存的唯一标识 shmid 共享内存的用户层id(句柄) owner 共享内存的拥有者 perms 共享内存的权限 bytes 共享内存的大小 nattch 关联共享内存的进程数 status 共享内存的状态 在共享内存列表中的perms代表的是该共享内存的权限,这个是可以修改的:
int shmid = shmget(key, MEM_SIZE, flags | 0666);再创建时,| 0666就更改权限为666了:
- 注意: key是在内核层面上保证共享内存唯一性的方式,而shmid是在用户层面上保证共享内存的唯一性,key和shmid之间的关系类似于fd和FILE*之间的的关系。
如果我们想要显示的删除,就使用ipcrm -m shmid:
[xzy@ecs-333953 date26]$ ipcrm -m 6
如上,已经将原来的共享内存删除了,并且创建了一个新的共享内存。
法二:使用系统接口shmctl删除共享内存
控制共享内存我们需要使用shmctl函数,shmctl函数的函数原型如下:
#include <sys/ipc.h> #include <sys/shm.h> int shmctl(int shmid, int cmd, struct shmid_ds *buf);shmctl函数的参数说明:
- shmid:表示所控制共享内存的用户级标识符
- cmd:表示具体的控制动作
- buf:用于获取或设置所控制共享内存的数据结构
shmctl函数的返回值说明:
- shmctl调用成功,返回0
- shmctl调用失败,返回-1
其中,作为shmctl函数的第二个参数cmd传入的常用的选项有以下三个:
选项 作用 IPC_STAT 获取共享内存的当前关联值,此时参数buf作为输出型参数 IPC_SET
在进程有足够权限的前提下,将共享内存的当前关联值设置为buf所指的数据结构中的值 IPC_RMID 删除共享内存段 这里修改IpcShmSer.cc文件的代码,使其在创建共享内存之后自动删除:
#include "Comm.hpp" #include "Log.hpp" // 充当创建共享内存的角色//我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; int main() {key_t key = CreateKey();Log() << "key: " << key << endl;Log() << "create share memory begin" << endl;sleep(5);int shmid = shmget(key, MEM_SIZE, flags | 0666);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}Log() << "create shm success, shmid: " << shmid << endl;//用它sleep(5);//删它shmctl(shmid, IPC_RMID, nullptr);Log() << "delete shm : " << shmid << "success" << endl;sleep(5);return 0; }
我们也可以使用如下的监控脚本时刻观察共享内存的资源分配情况,这里就不做演示了。
[xzy@ecs-333953 date26]$ while :; do ipcs -m; sleep 1; echo "——————————————————————————————————————————————————————————————";done实现了共享内存的创建和删除,下面就来演示如何使用共享内存,见下文的shmat和shmdt。
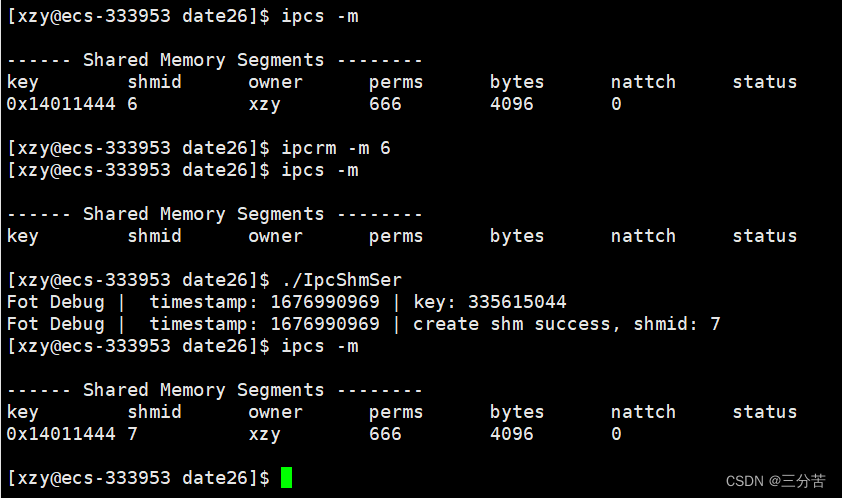

shmat关联共享内存
将共享内存连接到进程地址空间我们需要用shmat函数,shmat函数的原型如下:
#include <sys/types.h> #include <sys/shm.h> void *shmat(int shmid, const void *shmaddr, int shmflg);shmat函数的参数说明:
- shmid:表示待关联共享内存的用户级标识符
- shmaddr:指定共享内存映射到进程地址空间的某一地址,通常设置为NULL,表示让内核自己决定一个合适的地址位置
- shmflg:表示关联共享内存时设置的某些属性
shmat函数的返回值说明:
- shmat调用成功,返回共享内存映射到进程地址空间中的起始地址
- shmat调用失败,返回(void*)-1
其中,作为shmat函数的第三个参数shmflg传入的常用的选项有以下三个:
选项 作用 SHM_RDONLY 关联共享内存后只进行读取操作 SHM_RND 若shmaddr不为NULL,则关联地址自动向下调整为SHMLBA的整数倍。公式:shmaddr-(shmaddr%SHMLBA) 0 默认为读写权限 这时我们可以尝试使用shmat函数对共享内存进行关联(IpcShmSer.cc文件):
#include "Comm.hpp" #include "Log.hpp" // 充当创建共享内存的角色//我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; int main() {key_t key = CreateKey();Log() << "key: " << key << endl;Log() << "create share memory begin" << endl;int shmid = shmget(key, MEM_SIZE, flags | 0666);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}Log() << "create shm success, shmid: " << shmid << endl;sleep(2);//用它//1、将共享内存和自己的进程产生关联attchchar* str = (char*)shmat(shmid, nullptr, 0);Log() << "attach shm : " << shmid << " success" << endl;sleep(2);//删它shmctl(shmid, IPC_RMID, nullptr);Log() << "delete shm : " << shmid << "success" << endl;sleep(2);return 0; }注意:如果使用shmget函数创建共享内存时,并没有对创建的共享内存设置权限,创建出来的共享内存的默认权限为0,即什么权限都没有,那么server进程没有权限关联该共享内存。我们应该在使用shmget函数创建共享内存时,在其第三个参数处设置共享内存创建后的权限,权限的设置规则与设置文件权限的规则相同。这个上文已经讲过:
int shmid = shmget(key, MEM_SIZE, flags | 0666);
运行程序后,即可发现关联该共享内存的进程数由0变成了1,即关联成功。如果想要去关联则需要用到下文讲到的shmdt函数。
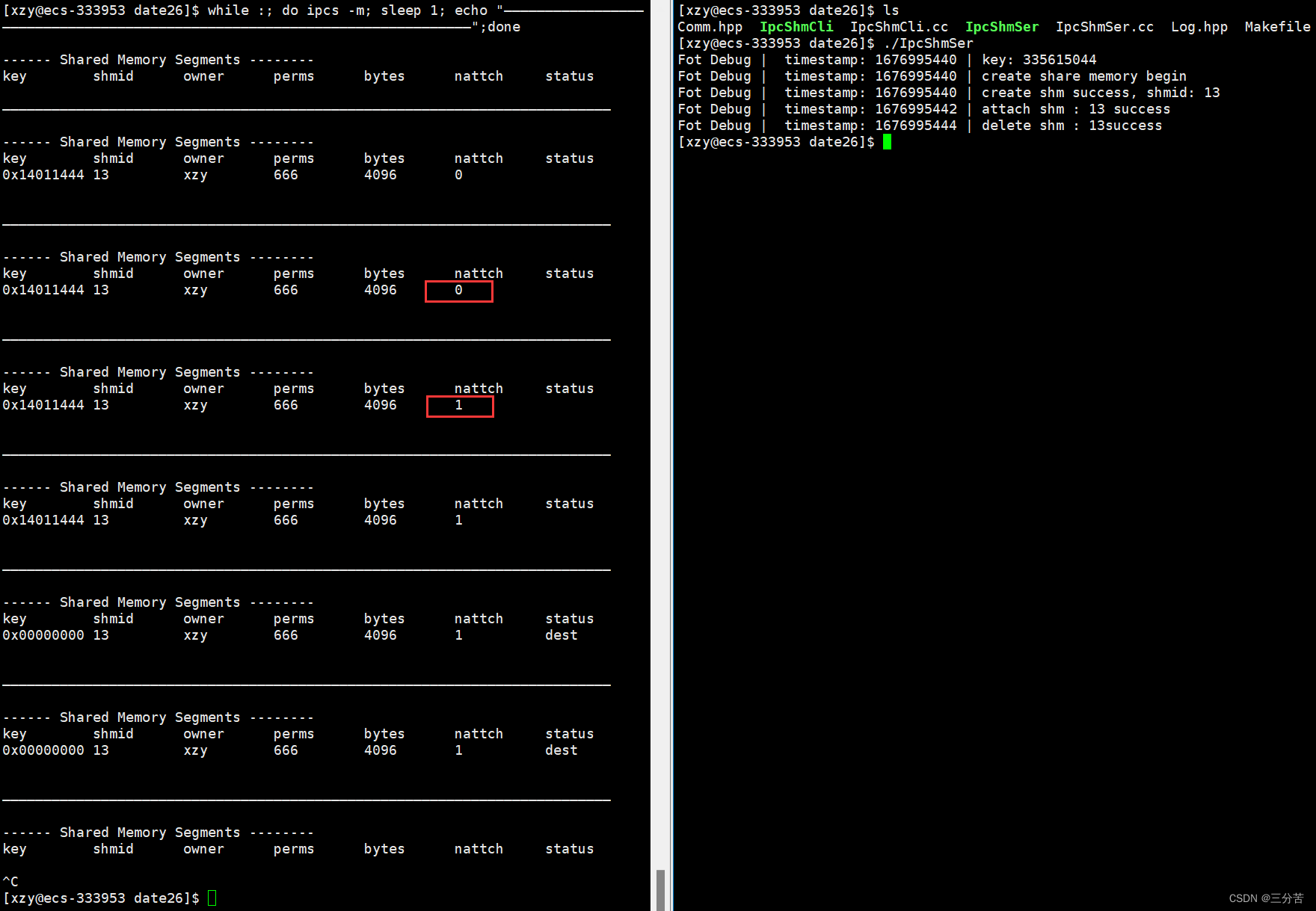
shmdt去关联共享内存
取消共享内存与进程地址空间之间的关联我们需要用shmdt函数,shmdt函数的函数原型如下:
#include <sys/types.h> #include <sys/shm.h> int shmdt(const void *shmaddr);shmdt函数的参数说明:
- shmaddr:待去关联共享内存的起始地址,即调用shmat函数时得到的起始地址(shmat函数的返回值)
shmdt函数的返回值说明:
- shmdt调用成功,返回0
- shmdt调用失败,返回-1
现在我们就能够取消共享内存与进程之间的关联了:
#include "Comm.hpp" #include "Log.hpp" // 充当创建共享内存的角色//我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; int main() {key_t key = CreateKey();Log() << "key: " << key << endl;Log() << "create share memory begin" << endl;int shmid = shmget(key, MEM_SIZE, flags | 0666);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}Log() << "create shm success, shmid: " << shmid << endl;sleep(2);//1、将共享内存和自己的进程产生关联attchchar* str = (char*)shmat(shmid, nullptr, 0);Log() << "attach shm : " << shmid << " success" << endl;sleep(2);//用它//2、去关联shmdt(str);Log() << "detach shm : " << shmid << " success" << endl;sleep(2);//删它shmctl(shmid, IPC_RMID, nullptr);Log() << "delete shm : " << shmid << "success" << endl;sleep(2);return 0; }我们使用如下的监控脚本时刻观察共享内存的资源分配情况:
[xzy@ecs-333953 date26]$ while :; do ipcs -m; sleep 1; echo "——————————————————————————————————————————————————————————————";done
运行程序,通过监控即可发现该共享内存的关联数由1变为0的过程,即取消了共享内存与该进程之间的关联。
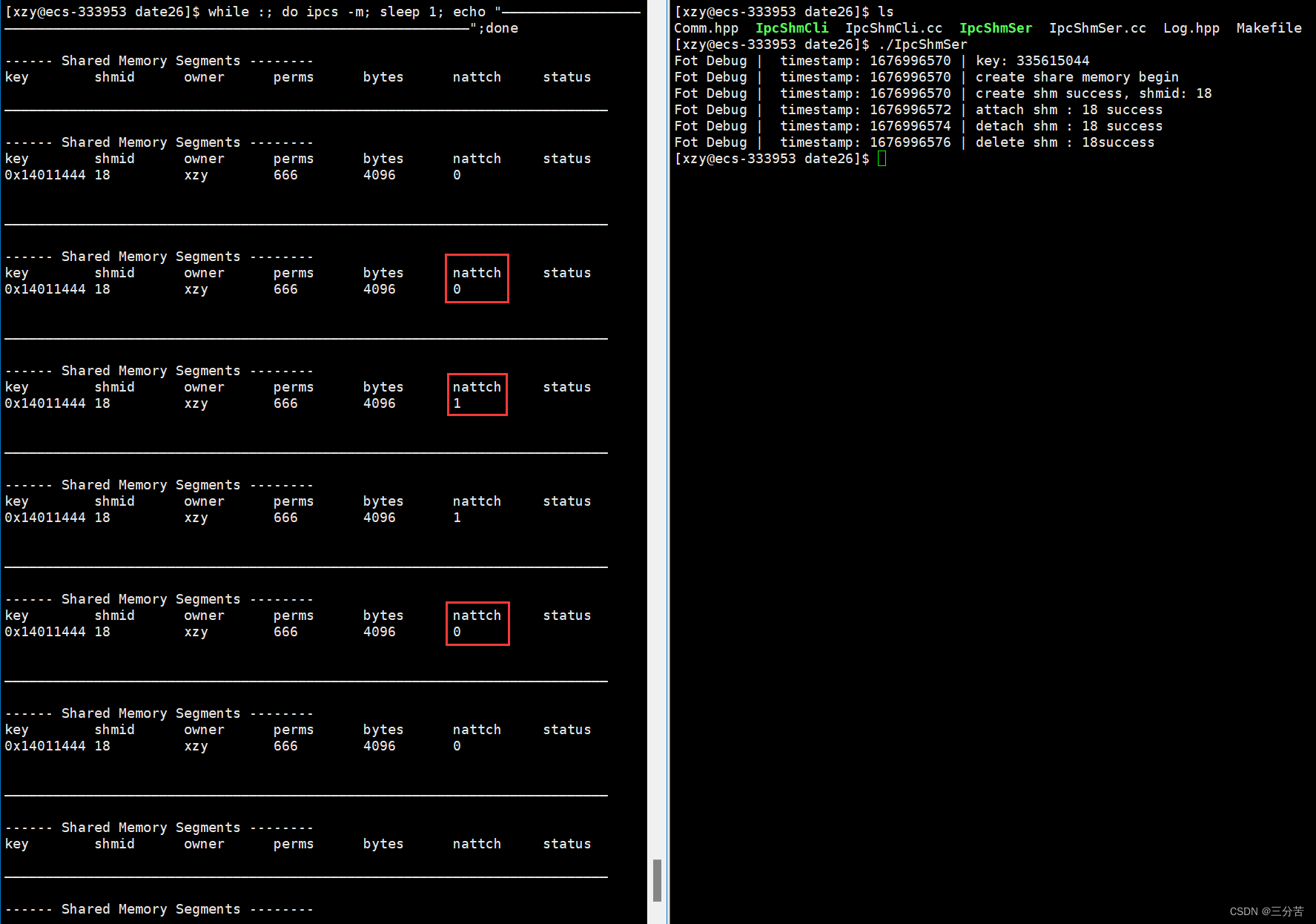
3.4、用共享内存实现serve&client通信
知道了共享内存的创建、关联、去关联以及释放后,实际上前面都是对server做的调整,准备工作做好后,下面只需要对client进行处理使用共享内存即可。总体代码如下:
Comm.hpp:
#pragma once #include<iostream> #include<sys/types.h> #include<sys/ipc.h> #include<sys/shm.h> #include<unistd.h> #include<cstdlib> #include<cstring> #include<cerrno> using namespace std;#define PATH_NAME "/home/xzy/dir/date26" //路径名 #define PROJ_ID 0x14 //整数标识符 #define MEM_SIZE 4096//共享内存的大小//创建key值 key_t CreateKey() {key_t key = ftok(PATH_NAME, PROJ_ID);if (key < 0){cerr << "ftok:" << strerror(errno) << endl;exit(1);}return key; }Log.hpp:
#pragma once #include<iostream> #include<ctime>std::ostream &Log() {std::cout << "Fot Debug | " << " timestamp: " << (uint64_t)time(nullptr) << " | ";return std::cout; }IpcServer.cc:
#include "Comm.hpp" #include "Log.hpp" // 充当创建共享内存的角色//我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; int main() {key_t key = CreateKey();Log() << "key: " << key << endl;Log() << "create share memory begin" << endl;int shmid = shmget(key, MEM_SIZE, flags | 0666);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}Log() << "create shm success, shmid: " << shmid << endl;sleep(2);//1、将共享内存和自己的进程产生关联attchchar* str = (char*)shmat(shmid, nullptr, 0);Log() << "attach shm : " << shmid << " success" << endl;sleep(2);//用它//2、去关联shmdt(str);Log() << "detach shm : " << shmid << " success" << endl;sleep(2);//删它shmctl(shmid, IPC_RMID, nullptr);Log() << "delete shm : " << shmid << "success" << endl;sleep(2);return 0; }IpcShmCli.cc:
#include"Comm.hpp" #include"Log.hpp" //充当使用共享内存的角色 int main() {//创建相同的key值key_t key = CreateKey();Log() << "key: " << key << endl;//获取共享内存int shmid = shmget(key, MEM_SIZE, IPC_CREAT);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}//挂接char* str = (char*)shmat(shmid, nullptr, 0);//使用sleep(2);//去关联shmdt(str);//不需要做删除操作return 0; }测试结果如下:
- 结果如上,挂接数先因为Ser挂接由0变成1,再因为Cli挂接,由1变成2,然后再依次去关联,最后变成0。
现在我们来真正让两个进程进行通信:
- IpcShmCli.cc:
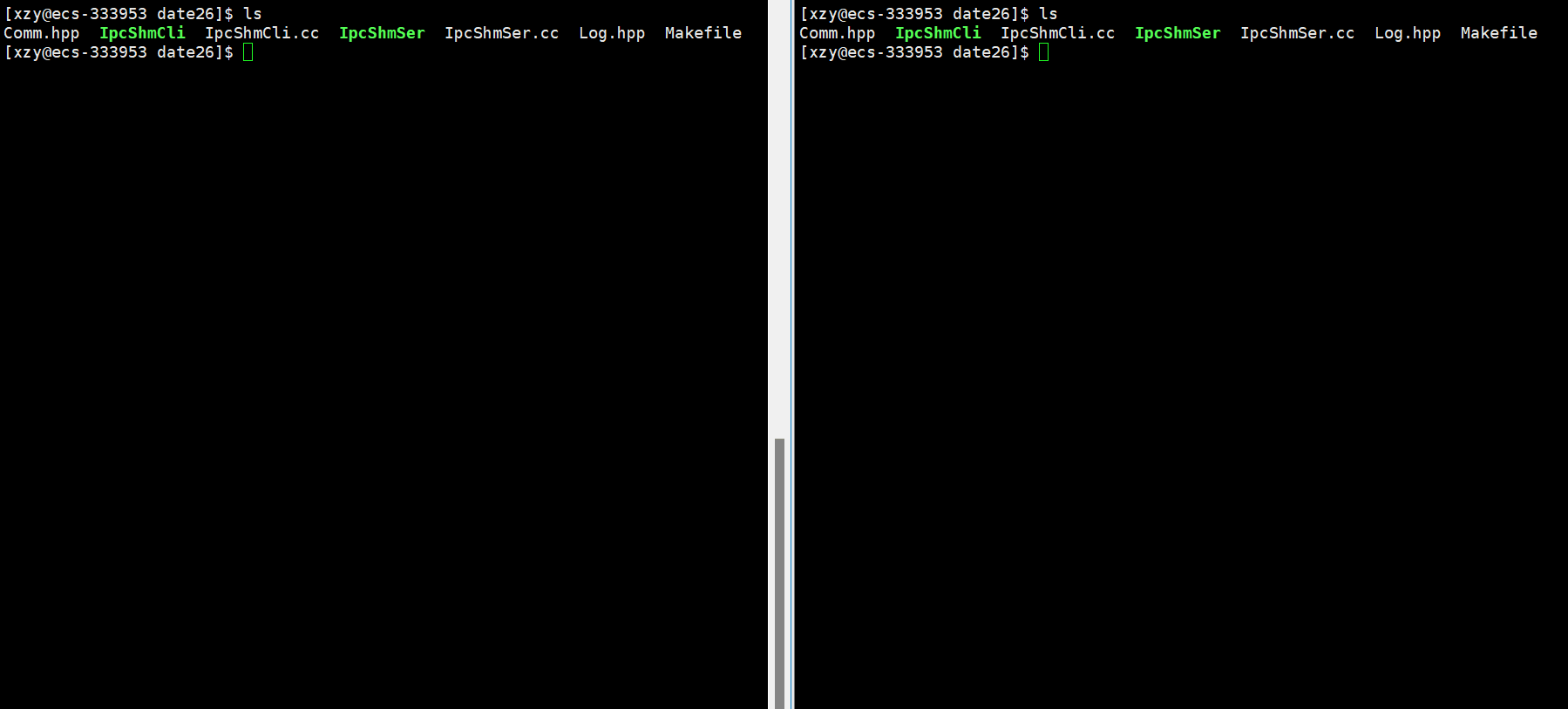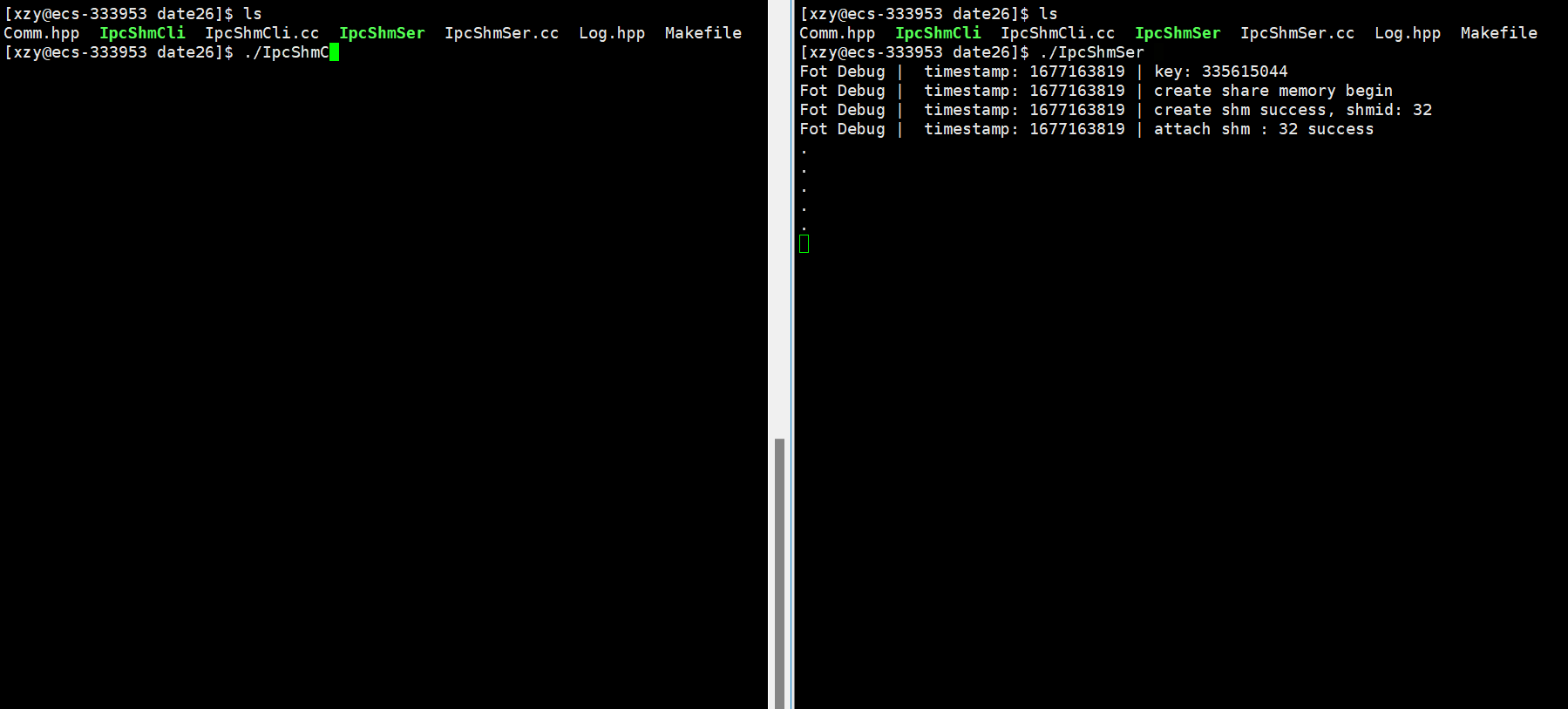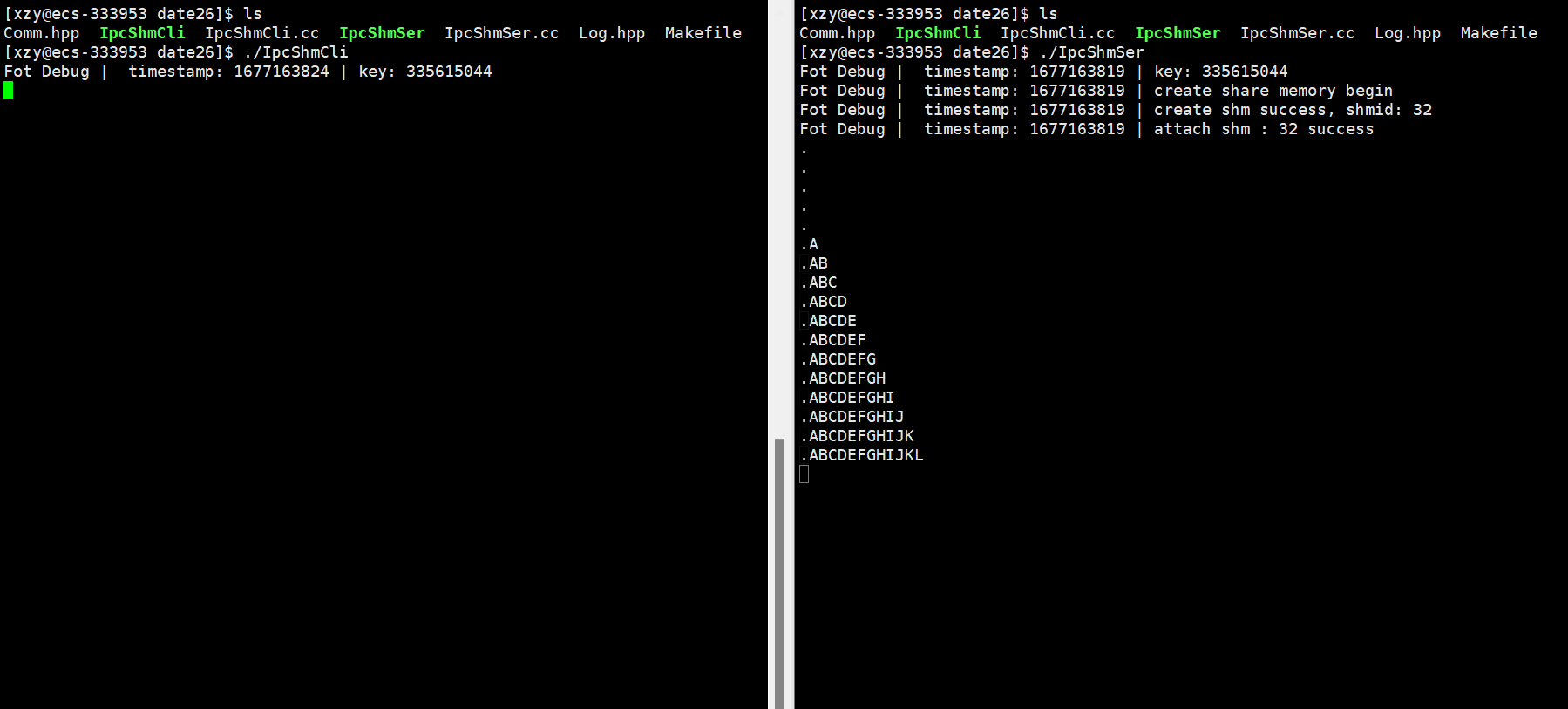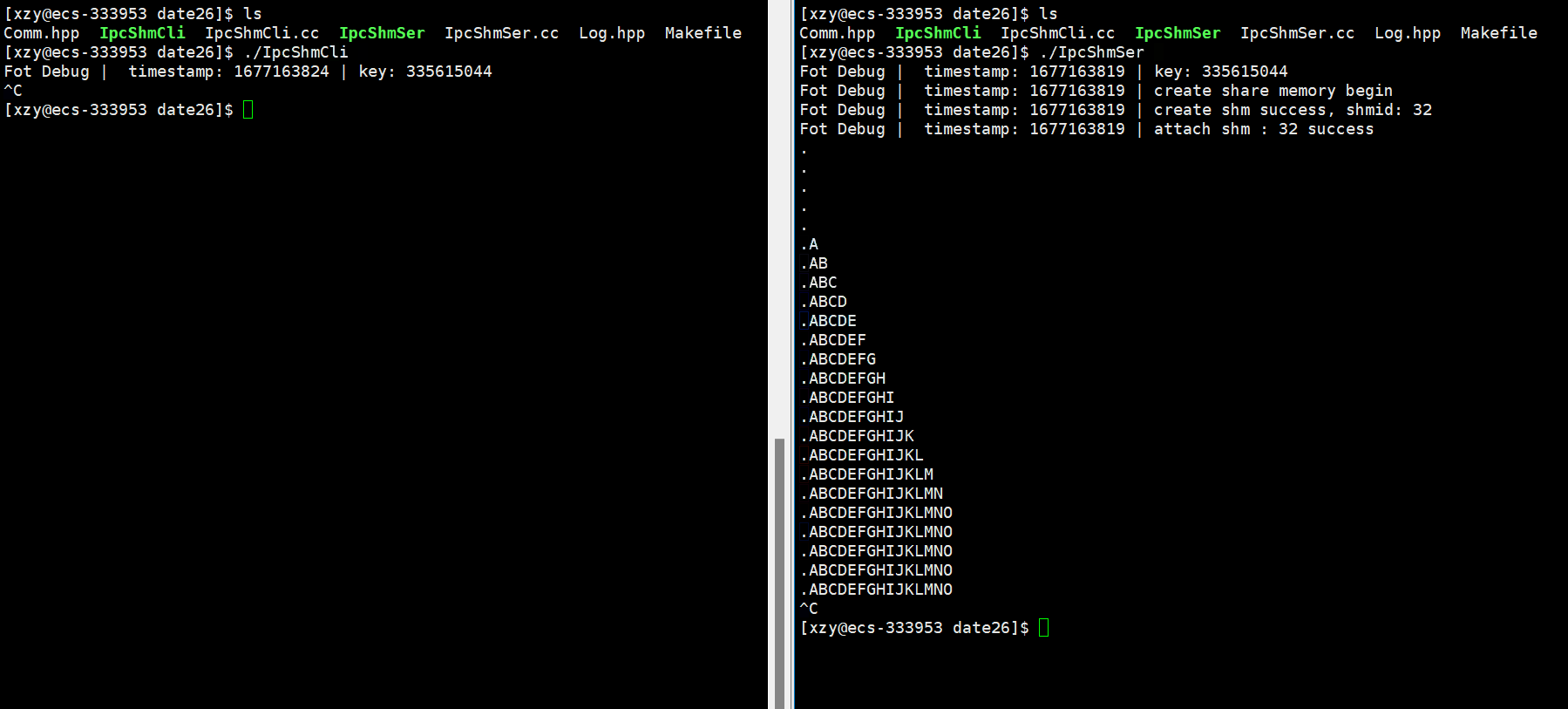
#include"Comm.hpp" #include"Log.hpp" //充当使用共享内存的角色 int main() {//创建相同的key值key_t key = CreateKey();Log() << "key: " << key << endl;//获取共享内存int shmid = shmget(key, MEM_SIZE, IPC_CREAT);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}//挂接char* str = (char*)shmat(shmid, nullptr, 0);//使用// sleep(2);//让client进程给server进程发消息int cnt = 0;while (cnt <= 26){str[cnt] = 'A' + cnt;++cnt;str[cnt] = '\0';sleep(1);}//去关联shmdt(str);//不需要做删除操作return 0; }
- IpcShmSer.cc:
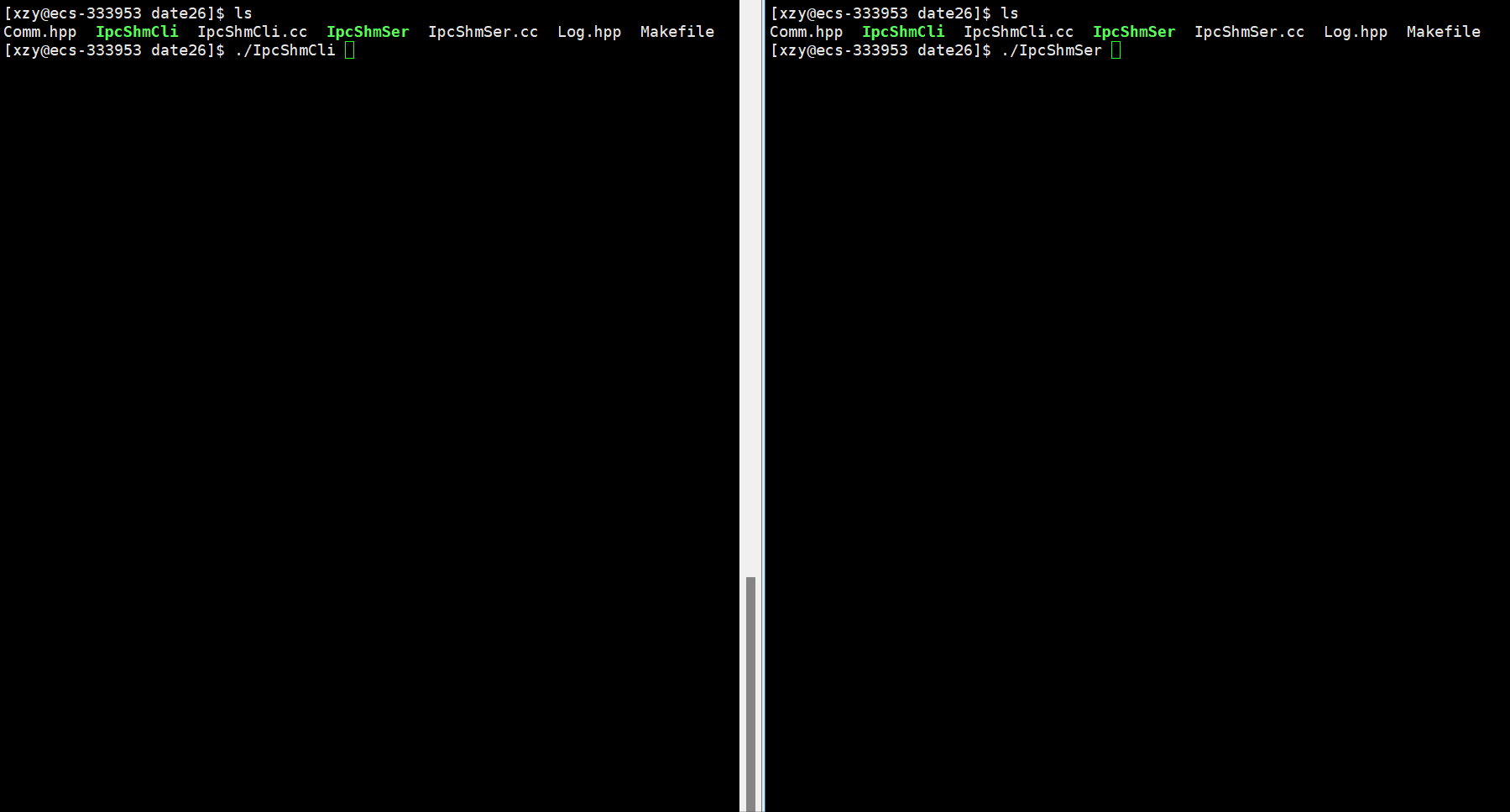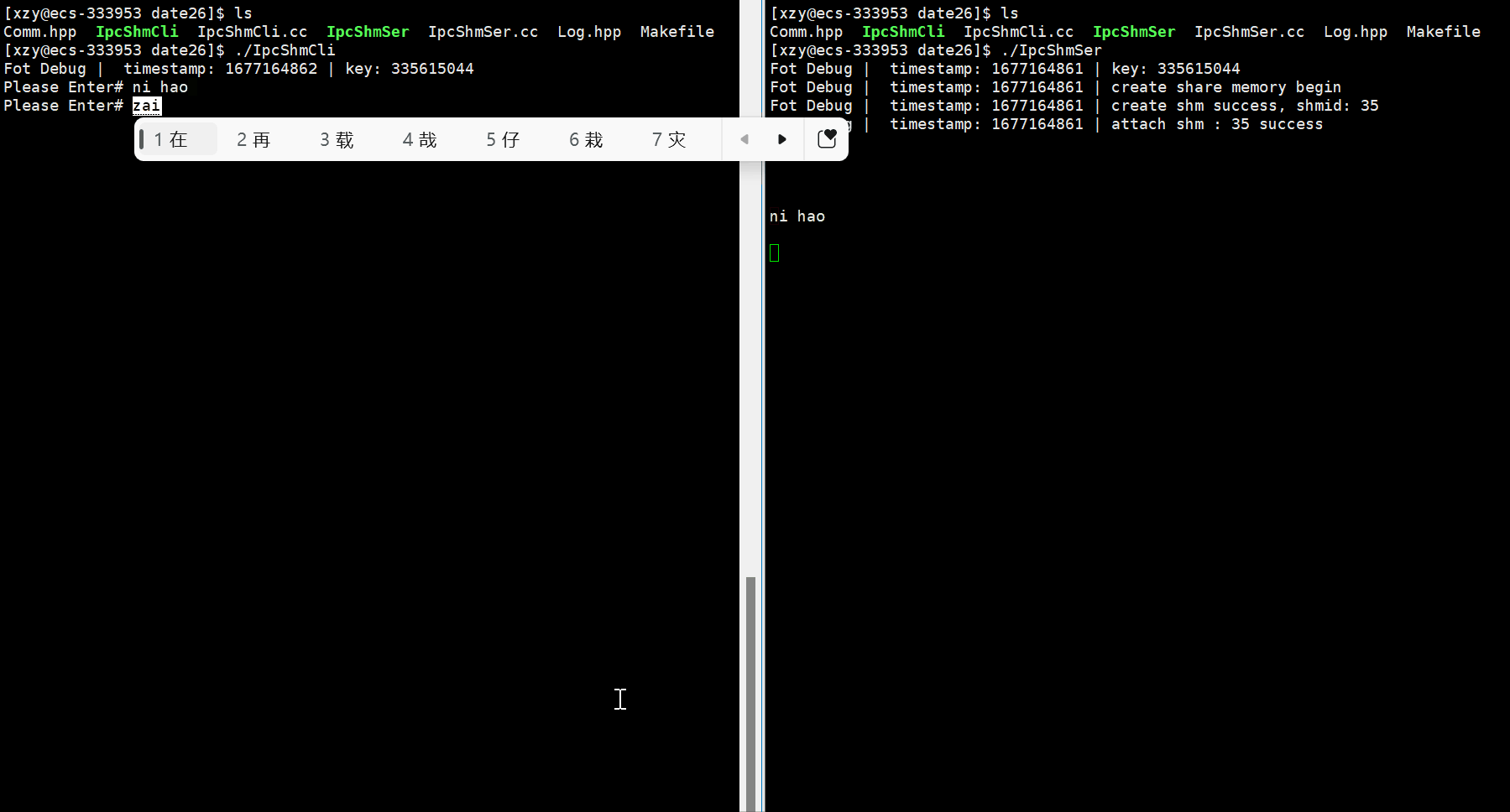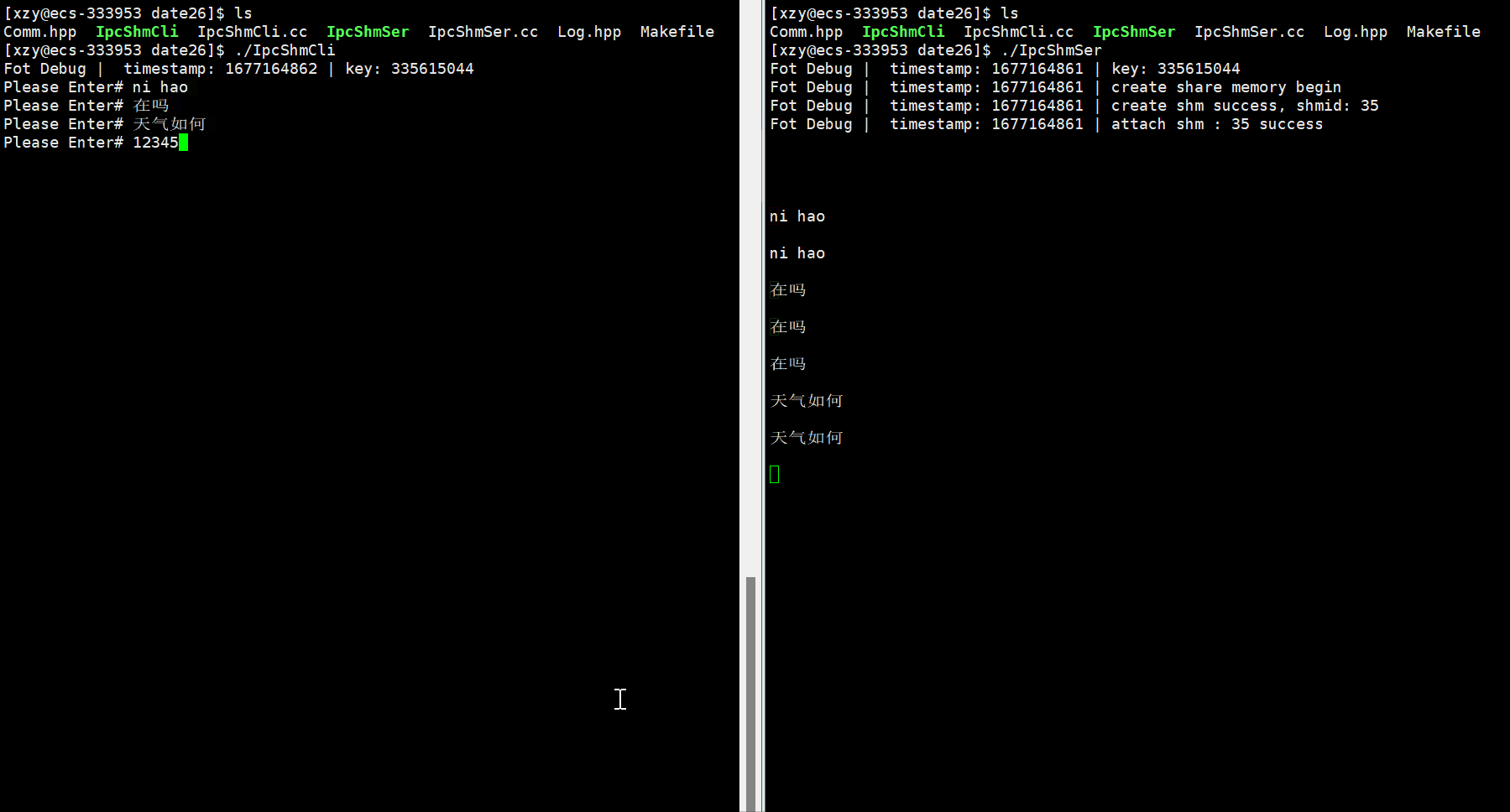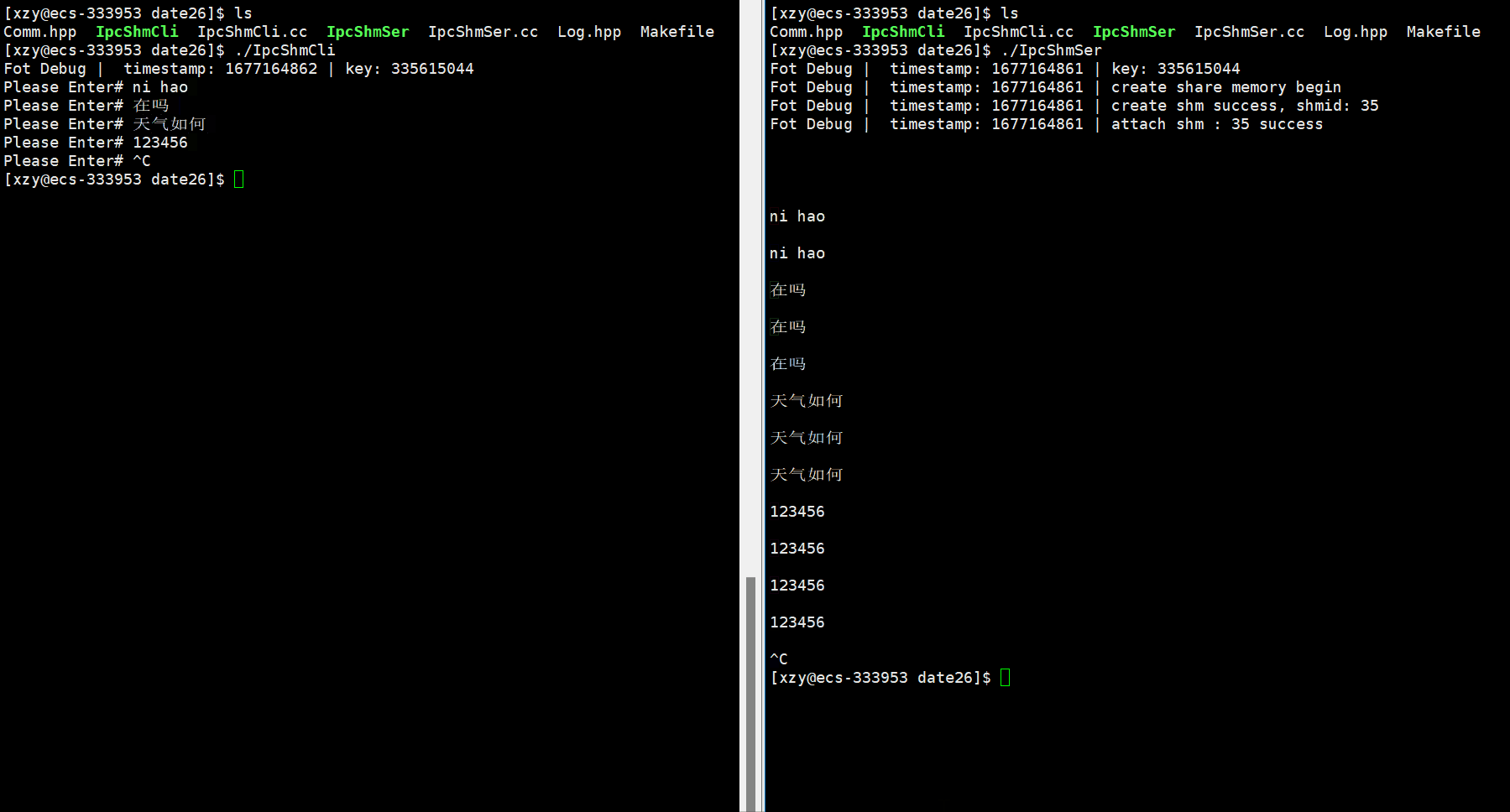
#include "Comm.hpp" #include "Log.hpp" // 充当创建共享内存的角色//我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; int main() {key_t key = CreateKey();Log() << "key: " << key << endl;Log() << "create share memory begin" << endl;int shmid = shmget(key, MEM_SIZE, flags | 0666);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}Log() << "create shm success, shmid: " << shmid << endl;// sleep(2);//1、将共享内存和自己的进程产生关联attchchar* str = (char*)shmat(shmid, nullptr, 0);Log() << "attach shm : " << shmid << " success" << endl;// sleep(2);//用它while (true){printf("%s\n", str);sleep(1);}//2、去关联shmdt(str);Log() << "detach shm : " << shmid << " success" << endl;// sleep(2);//删它shmctl(shmid, IPC_RMID, nullptr);Log() << "delete shm : " << shmid << "success" << endl;// sleep(2);return 0; }如上我实现了client进程给server进程,但是我client进程中并没有使用系统调用向共享内存中写入,像之前学习的管道创建好后,想要用它必须要用write,read等系统接口,而使用共享内存竟然没有使用任何的系统接口。解释如下:
- 我们把共享内存实际上是映射到了我们进程地址空间的用户空间了(堆->栈之间)。堆栈都是属于用户的,因此对每一个进程而言,挂接到自己的上下文中的共享内存,是属于自己的空间,类似于堆空间或者栈空间,是可以被用户直接使用的(不需要调用系统接口)。
测试结果如下:
当一开始只运行服务端IpcShmSer可执行程序时,会发现无论IpcShmCli是否像挂接的地址空间中写入了消息,IpcShmSer是一直在刷新的,只不过共享内存是空的一开始,随后我们运行客户端IpcShmCli可执行程序,此时客户端往共享内存中写入数据,我服务端就能立马看到了。
- 因此,共享内存,因为它自身的特性,它没有任何访问控制!共享内存被双方直接看到,属于双方的用户空间,可以直接通信,但是不安全。也因此,共享内存是所有进程间通信中,速度最快的!
现在对IpcShmCli.cc文件再次进行修改:
#include"Comm.hpp" #include"Log.hpp" #include<cstdio> //充当使用共享内存的角色 int main() {//创建相同的key值key_t key = CreateKey();Log() << "key: " << key << endl;//获取共享内存int shmid = shmget(key, MEM_SIZE, IPC_CREAT);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}//挂接char* str = (char*)shmat(shmid, nullptr, 0);//使用//让client进程给server进程发消息while (true){printf("Please Enter# ");fflush(stdout);ssize_t s = read(0, str, MEM_SIZE);if (s > 0){str[s] = '\0';}}//去关联shmdt(str);//不需要做删除操作return 0; }
- 这里就可以我们自己再IpcShmCli'中输入,在IpcShmSer中得到通信的结果。
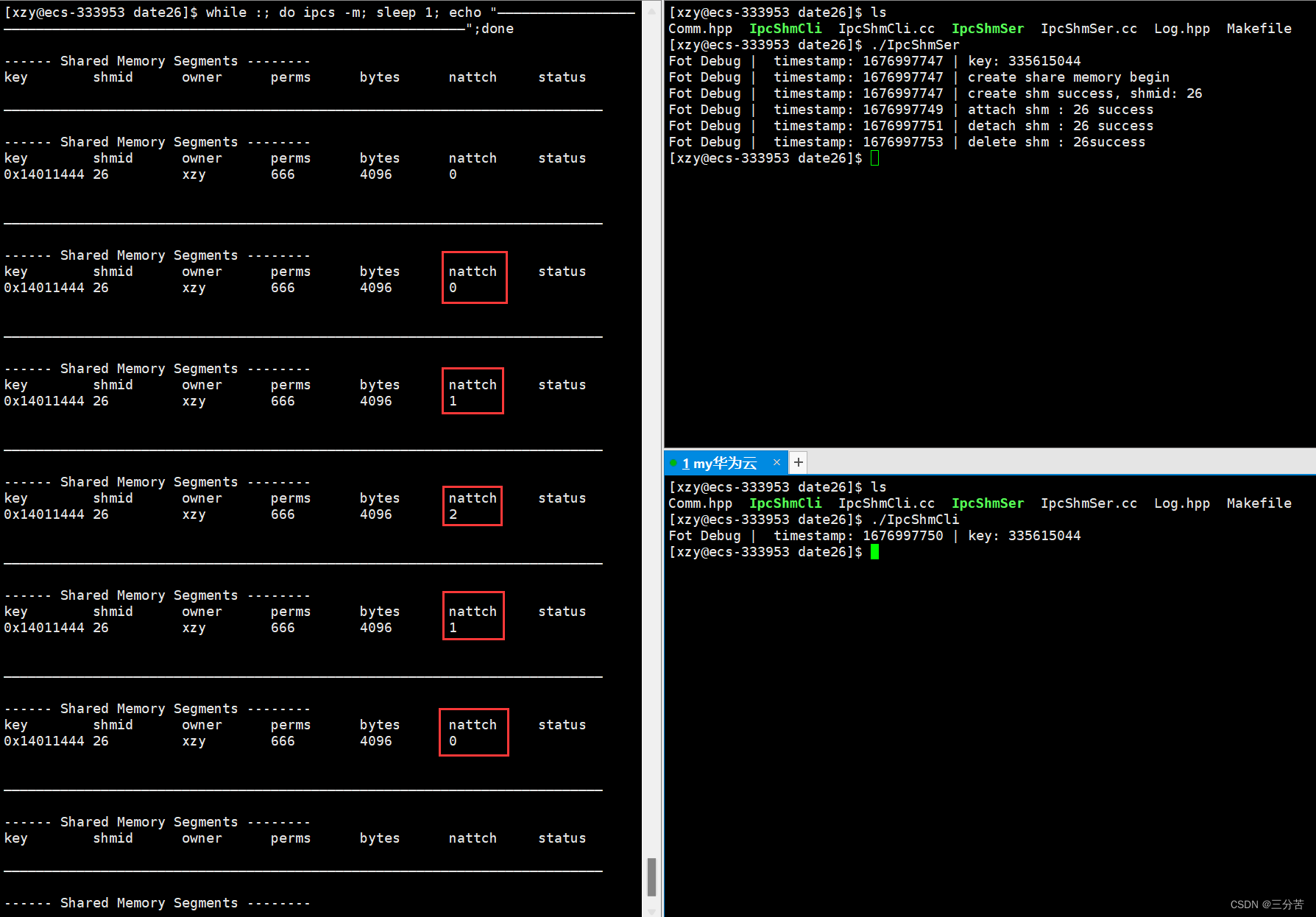
下面我们再用命名管道对共享内存做访问控制:
Comm.hpp:
#pragma once #include <iostream> #include <sys/types.h> #include <sys/stat.h> #include <sys/ipc.h> #include <sys/shm.h> #include <unistd.h> #include <fcntl.h> #include <cstdlib> #include <cstring> #include <cerrno> #include <cassert> #include "Log.hpp" using namespace std;#define PATH_NAME "/home/xzy/dir/date26" // 路径名 #define PROJ_ID 0x14 // 整数标识符 #define MEM_SIZE 4096 // 共享内存的大小#define FIFO_FILE ".fifo"// 创建key值 key_t CreateKey() {key_t key = ftok(PATH_NAME, PROJ_ID);if (key < 0){cerr << "ftok:" << strerror(errno) << endl;exit(1);}return key; }// 创建命名管道 void CreateFifo() {umask(0);if (mkfifo(FIFO_FILE, 0666) < 0){// 创建失败Log() << strerror(errno) << endl;exit(2);} }#define READER O_RDONLY #define WRITER O_WRONLY // 读 && 写 int Open(const string &filename, int flags) {return open(filename.c_str(), flags); }int Wait(int fd) {uint32_t values = 0;ssize_t s = read(fd, &values, sizeof(values));return s; }int Signal(int fd) {uint32_t cmd = 1;write(fd, &cmd, sizeof(cmd)); }int Close(int fd, const string &filename) {close(fd);unlink(filename.c_str()); }IpcShmSer.cc:
#include "Comm.hpp" #include "Log.hpp" // 充当创建共享内存的角色//我想创建全新的共享内存 const int flags = IPC_CREAT | IPC_EXCL; int main() {CreateFifo();int fd = Open(FIFO_FILE, READER);assert(fd >= 0);key_t key = CreateKey();Log() << "key: " << key << endl;Log() << "create share memory begin" << endl;int shmid = shmget(key, MEM_SIZE, flags | 0666);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}Log() << "create shm success, shmid: " << shmid << endl;// sleep(2);//1、将共享内存和自己的进程产生关联attchchar* str = (char*)shmat(shmid, nullptr, 0);Log() << "attach shm : " << shmid << " success" << endl;// sleep(2);//用它while (true){//让读端进行等待if (Wait(fd) <= 0) break;printf("%s\n", str);sleep(1);}//2、去关联shmdt(str);Log() << "detach shm : " << shmid << " success" << endl;// sleep(2);//删它shmctl(shmid, IPC_RMID, nullptr);Log() << "delete shm : " << shmid << "success" << endl;Close(fd, FIFO_FILE);// sleep(2);return 0; }IpcShmCli.cc:
#include"Comm.hpp" #include"Log.hpp" #include<cstdio> //充当使用共享内存的角色 int main() {int fd = Open(FIFO_FILE, WRITER);//创建相同的key值key_t key = CreateKey();Log() << "key: " << key << endl;//获取共享内存int shmid = shmget(key, MEM_SIZE, IPC_CREAT);if (shmid < 0){Log() << "shmget: " << strerror(errno) << endl;return 2;}//挂接char* str = (char*)shmat(shmid, nullptr, 0);//使用// sleep(2);//让client进程给server进程发消息while (true){printf("Please Enter# ");fflush(stdout);ssize_t s = read(0, str, MEM_SIZE);if (s > 0){str[s] = '\0';}Signal(fd);}//去关联shmdt(str);//不需要做删除操作return 0; }把上述代码再复盘一下:
- 上述我给共享内存加上了命名管道,当共享内存没有数据时,Server服务端就一直在阻塞等待,直至有数据时再读,而不是像之前那样一直读。这就是基于共享内存 + 管道的一个访问控制的效果。
3.5、共享内存与管道进行对比
当共享内存创建好后就不再需要调用系统接口进行通信了,而管道创建好后仍需要read、write等系统接口进行通信。实际上,共享内存是所有进程间通信方式中最快的一种通信方式。
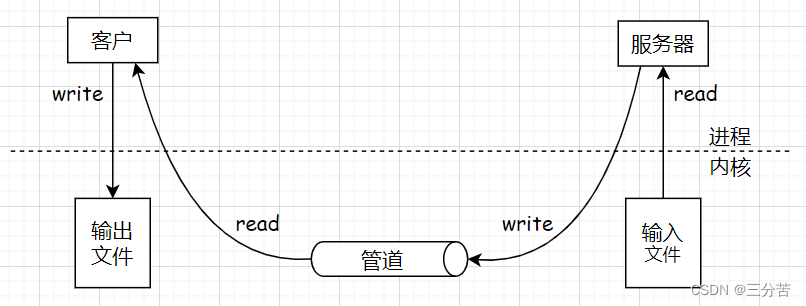
我们先来看看管道通信:
从这张图可以看出,使用管道通信的方式,将一个文件从一个进程传输到另一个进程需要进行四次拷贝操作:
- 服务端将信息从输入文件复制到服务端的临时缓冲区中
- 将服务端临时缓冲区的信息复制到管道中
- 客户端将信息从管道复制到客户端的缓冲区中
- 将客户端临时缓冲区的信息复制到输出文件中
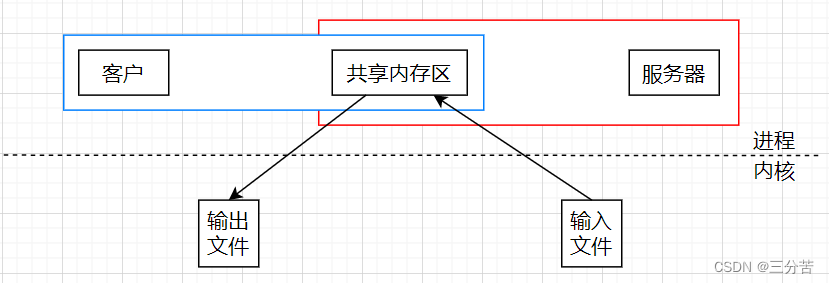
再来看看共享内存通信:
从这张图可以看出,使用共享内存进行通信,将一个文件从一个进程传输到另一个进程只需要进行两次拷贝操作:
- 从输入文件到共享内存。
- 从共享内存到输出文件。
所以共享内存是所有进程间通信方式中最快的一种通信方式,因为该通信方式需要进行的拷贝次数最少。但是共享内存也是有缺点的,我们知道管道是自带同步与互斥机制的,但是共享内存并没有提供任何的保护机制,包括同步与互斥。
4、system V IPC联系
临界资源、临界区、原子性、互斥
临界资源:
- 被多个进程能够同时看到的资源,叫做临界资源(管道,共享内存中的资源都属于临界资源)
- 如果没有对临界资源进行任何保护,对于临界资源的访问,双方进程在进行访问的时候,就会都是乱序的,可能会因为读写交叉而导致各种乱码、废弃数据、访问控制方面的问题。
临界区:
- 对多个进程而言,访问临界资源的代码,叫做临界区。(在之前写的进程代码中,只有一部分代码会访问临界资源,这部分代码就叫做临界区)
原子性:
- 我们把一件事情,要么没做,要么做完了,称之为原子性
互斥:
- 任何时刻,只允许一个进程,访问临界资源,我们称之为互斥
信号量
一、信号量相关函数:
信号量集的创建(semget):
int semget(key_t key, int nsems, int semflg);说明一下:
- 创建信号量集也需要使用ftok函数生成一个key值,这个key值作为semget函数的第一个参数。
- semget函数的第二个参数nsems,表示创建信号量的个数。
- semget函数的第三个参数,与创建共享内存时使用的shmget函数的第三个参数相同。
- 信号量集创建成功时,semget函数返回的一个有效的信号量集标识符(用户层标识符)。
信号量集的删除(semctl):
int semctl(int semid, int semnum, int cmd, ...);信号量集的操作(semop):
int semop(int semid, struct sembuf *sops, unsigned nsops);二、信号量的概念:
先看如下的场景:
- 假设一个电影院只有100个位置,那么它只能卖100张电影票。电影院是可以被多个人进出的,所以它即临界资源。通常情况下,我只要买到了票,那么电影院中的一个位置必然是我的。买票其实就是对放映厅中特定的座位的一种预定机制。为了防止电影票多卖出去导致座位不够,我们是定义一个cnt变量,初始化100,当有人买票的时候,那么就--cnt,并返回一个编号(票号),直至cnt <= 0。
上述放映厅就是一个临界资源,当此放映厅只允许一个人看电影,那么就只有一张电影票,这里体现的就是互斥特性。
- 当此放映厅有100个座位时,每个人都是一个进程,只要我们坐在不同的位置,且都可以访问此临界资源,此情况下我们只需要保证不能有多余的人进来以及保证大家访问的是不同的资源(由上层业务决定)即可。我们同样可以定义一个cnt变量,初始化100,当有人买票且cnt <= 0时,就wait等待,cnt > 0时,就cnt--,当有人离场时,cnt++。
上述的cnt就类似于信号量,信号量本质就是一个计数器。当信号量为1的时候,表现的就是互斥特性,我们称之为二元信号量。我们把常规的信号量称之为多元信号量。临界资源每被占一块,信号量就--,信号量的大小就等于临界资源的大小。
- 而多个人看电影,首先需要买票,本质就是对信号量(int cnt = 100)进行抢占申请。类似的,任何进程想要访问临界资源,必须先申请信号量。如果申请成功,就一定能访问临界资源中的一部分资源。
- 每一个人,必须先申请cnt --》 每一个人必须先看到这个计数器。类似的,每一个进程,要先申请信号量 --》 每一个进程都必须先看到这个信号量。在这种情况下,计数器和信号量本身也是一个临界资源。
注意:不考虑其它因素,cnt--是会存在很多的中间状态,“单纯的计数器它不是原子性的”,见下文:
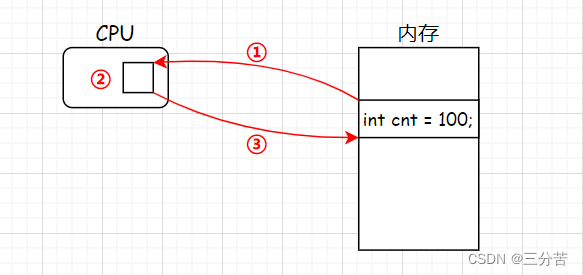
问:如何理解cnt--?
- 在计算机里头,只有cpu才有计算能力,我们定义的整型变量cnt是在内存中的,要计算的时候(cnt--),首先要把cnt变量读到cpu里头,然后cpu内部做--,计算后再把结果写回我的内存中。图示如下:
- 但是cnt--是会存在多个中间状态的,因为当执行完图示的第①,②步后,正准备写回时(cnt=99),进程切换了,上下文的数据被保存起来了,此时假设另一个进程来了,同样是在cpu加载数据,我们假设这里计算时有个while循环(一直--),最终计算后的结果是50,并将结果返回到内存中,当此进程退出后,原进程被切回来了,此时把之前村的数据(cnt=99)要写回内存了,那么原先计算的数据50又被覆盖成99了,此时就出现了因为多执行流交叉的问题导致变量的值出现不一致的问题。为了保证不会出现此问题,必须保证计数器是原子性的。
总结:为了保证计数器执行前后不会被中断,不会因为执行流切换而导致变量的值出现不一致的问题,信号量必须是具有原子性的。信号量是一个计数器,这个计数器对应的操作是原子的。
信号量对应的操作是PV操作:
- semop-1:申请资源(P)
- semop+1:释放资源(V)
共享内存不做访问控制,可以通过信号量进行对资源保护。
IPC资源
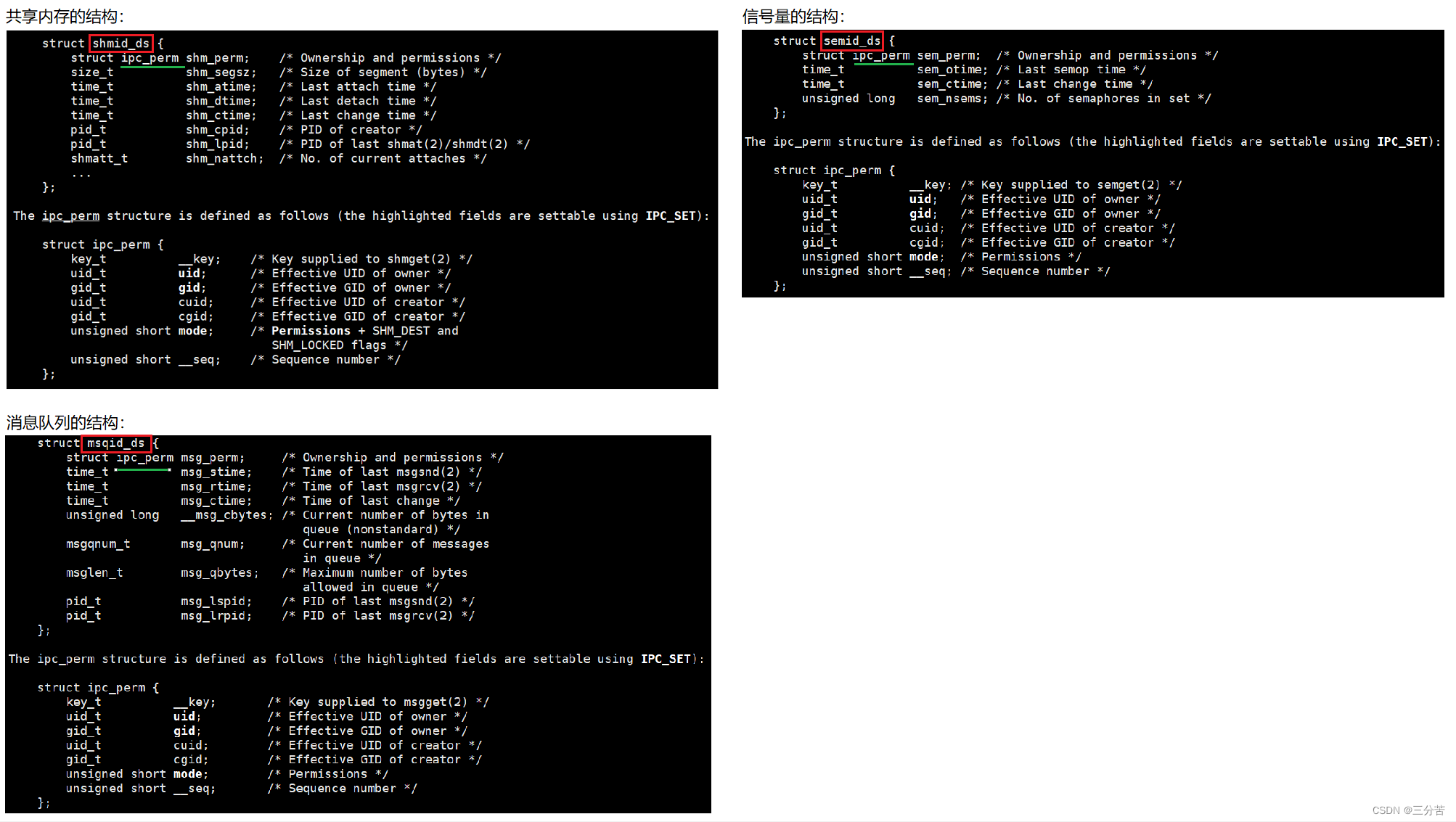
其实我们所有的IPC资源在内核中是通过数组来管理的,名为ipc_perm,来看如下共享内存、信号量、消息队列的结构:
如上三个对应的结构体的第一个字段都是ipc_perm,它们三个对于此的资源都是一样的,所以每一种IPC资源描述结构体第一个都是一样的,都是struct ipc_perm,为下列结构:
struct ipc_perm {//key//权限…… };操作系统需要把这些字段管理起来,其内部有一个ipc_ids这样的结构,里面有一个*entries这样的柔性数组,其指向ipc_id_ary这样的结构,它是一个指针数组(struct ipc_perm* ipc_id_ar[n]),它的所有元素最终都指向这个ipc_perm结构,而ipc_perm就是每种资源的第一个字段。所以当我想申请一块共享内存的时候,OS帮我创建此shmid_ds结构对象,并用前面的指针数组ipc_id_ary的0号指针指向此shmid_ds结构对象的第一个元素struct ipc_perm,以此类推……
上述使用ipc_id_ary指针数组的好处是便于访问资源,当下标0指向共享内存的第一个字段时,为了访问该共享内存结构体的剩下元素,我们可以使用强转,((struct id_ds*)ipc_id_ar[0] )-> 访问其它元素,上述能这么做的原因是结构体的第一个元素的地址,在数字上和结构体整体的地址大小是一样的。上述做法我们就可以用统一的规则,在内核中管理不同种类的IPC资源啦!!!有点像C++的多态技术的切片。