邯郸企业网站建设价格网址查询ip地址
这里写目录标题
- 学习原因
- MySQL中explain的使用和用法解释
- explain的使用
- explain 运行结果的意义
- 文字展示
- 表格展示
- 参考资料:
- 结束语
学习原因
在对sql的优化过程中使用了explain对指定的sql进行查看它的运行效果,以便找出sql的性能特点并进行优化
MySQL中explain的使用和用法解释
explain的使用
explain的使用时可以直接在要运行的sql语句前加上explain
例如: explain select * from user;
而在navicat这类工具中工具栏中就有按钮可直接点击 从而实现给指定的sql语句添加上explain操作
explain 运行结果的意义
运行excplain的结果如下图所示:
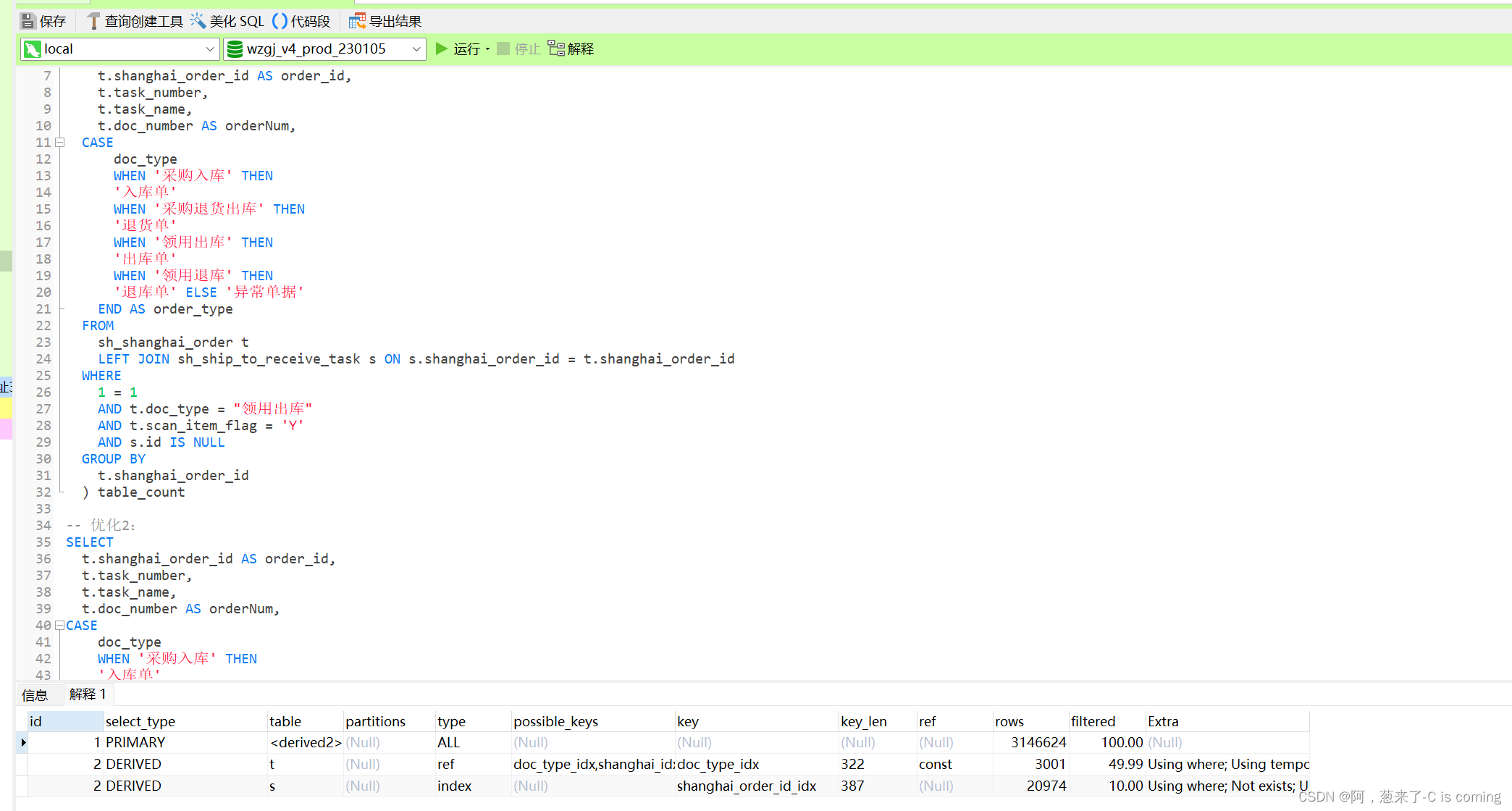
运行explain后各列的意义:
文字展示
-
id :select 识别符。这是select的查询序列号
-
select_type :select的类型:
- SIMPLE:简单的SELECT(不使用UNION或子查询)
- PRIMARY:最外面的SELECT
- UNION:UNION中的第二个或后面的SELECT语句
- DEPENDENT UNION:UNION中的第二个或后面的SELECT语句,取决于外面的查询
- UNION RESULT:UNION 的结果
- SUBQUERY:子查询中的第一个SELECT
- DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外面的查询
- DERIVED:导出表的SELECT(FROM子句的子查询)
-
table :显示这一行的的数据是关于哪张表的
-
type : (重要) 该列显示了连接使用的何种类型,从最好到最差的连接类型为
- const :如果将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量。至于如何转化以及何时转化,这个取决于优化器。
- ref_eq:使用了索引,且该结果集只有一个,说明使用了主键和唯一值索引
- ref :查找条件列使用了索引而且不为主键和unique。意思就是虽然使用了索引,但该索引列的值并不唯一,有重复
- range :指的是有范围的索引扫描,相对于index的全索引扫描,它有范围限制,因此要优于index。
- index :有索引的全表扫描
- ALL:全表扫描,无索引,无任何优化,单纯的全表扫描
-
possible_keys :显示可能应用在这张表中的索引,如果为空,没有可能的索引
-
key :实际使用的索引,如果为NULL,则没有使用索引,如果在查询想要强制使用或忽略possible_keys列中的索引,在查询中使用force index、ignore index(通常在表名之后使用 … from <table_name> force <index> …)
-
key_len :显示MySQL在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些字段
-
ref :显示在key记录的索引中,表查询值所用到的列或常量,常见的又:const(常量),字段名(例:id)
-
row :该列是MySQL估计要读取并检测的行数,注意这个不是结果集里的行数
-
Extra :显示额外信息,常见的值有:Using index;Using where; Using where Using index;NULL。
-
Using index:查询的列被索引覆盖,并且where筛选条件是索引的前导列,是性能高的表现。一般是使用了覆盖索引(索引包含查询的所有字段),对于innodb来说,如果是辅助索引性能会有不少的提升。
-
Using where:查询的列未被索引覆盖,where筛选条件非索引的前导列。
-
Using where Using index:查询的列被索引覆盖,并且where筛选条件是索引列之一,但不是索引的前导列,意味着无法直接通过索引查找来查询到符合条件的数据。
-
NULL:查询的列未被索引覆盖,并且where筛选条件是索引的前导列,意味着用到了索引,但是部分字段未被索引覆盖,必须通过回表来实现,不是纯粹的用到了索引,也不是完全没有用到索引。
-
Using index condition:与Using where类似,查询的列不完全被索引覆盖,where条件中是一个前导列的查询的范围。
-
Using temporary:MySQL需要创建一张临时表来处理查询,出现这种情况一般是要进行优化的。
-
Using filesort:MySQL会对结果使用一个外部索引排序,而不是按索引次序从表里读取行,此时MySQL会根据连接类型浏览符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息,这种情况下一般也是要考虑使用索引来优化查询。
-
表格展示
| 列名 | 含义 |
|---|---|
| id | SELECT识别符。这是SELECT的查询序列号 |
| select_type | SELECT 类型,可以为以下任意一种:
|
| table | 输出的行所引用的表 |
| type | 连接类型。下面给出的各种类型,按照从最佳到最坏排序:
|
| possible_keys | 指出MySQL能使用哪个索引在该表中找到行 |
| key | 显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。 |
| key_len | 显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。 |
| ref | 显示使用哪个列或常数与key一起从表中选择行。 |
| rows | 显示MySQL认为它执行查询时必须检查的行数。多行之间的数据相乘可以估算要处理的行数。 |
| filtered | 显示了通过条件过滤出的行数的百分比估计值。 |
| Extra | 该列包含MySQL解决查询的详细信息:
|
参考资料:
https://blog.csdn.net/seven_north/article/details/89370974
结束语
若我的教程能给你提供帮助,点赞,评论,收藏将会给我提供更新的动力。
蟹蟹!ヾ(≧▽≦*)o