北京网站seo推广如何进入网站
目录:
- RNN 问题
- RNN 时序链问题
- RNN 词组预测的例子
- RNN简洁实现
一 RNN 问题
RNN 主要有两个问题,梯度弥散和梯度爆炸
1.1 损失函数
梯度
其中:
则
1.1 梯度爆炸(Gradient Exploding)
上面矩阵进行连乘后k,可能会出现里面参数会变得极大

解决方案:
梯度剪裁:对W.grad进行约束

def print_current_grad(model):for w in model.parameters():print(w.grad.norm())loss.criterion(output, y)
model.zero_grad()
loss.backward()
print_current_grad(model)
torch.nn.utils.clip_grad_norm_(p,10)
print_current_grad(model)
optimizer.step()
1.2 梯度弥散(Gradient vanishing)
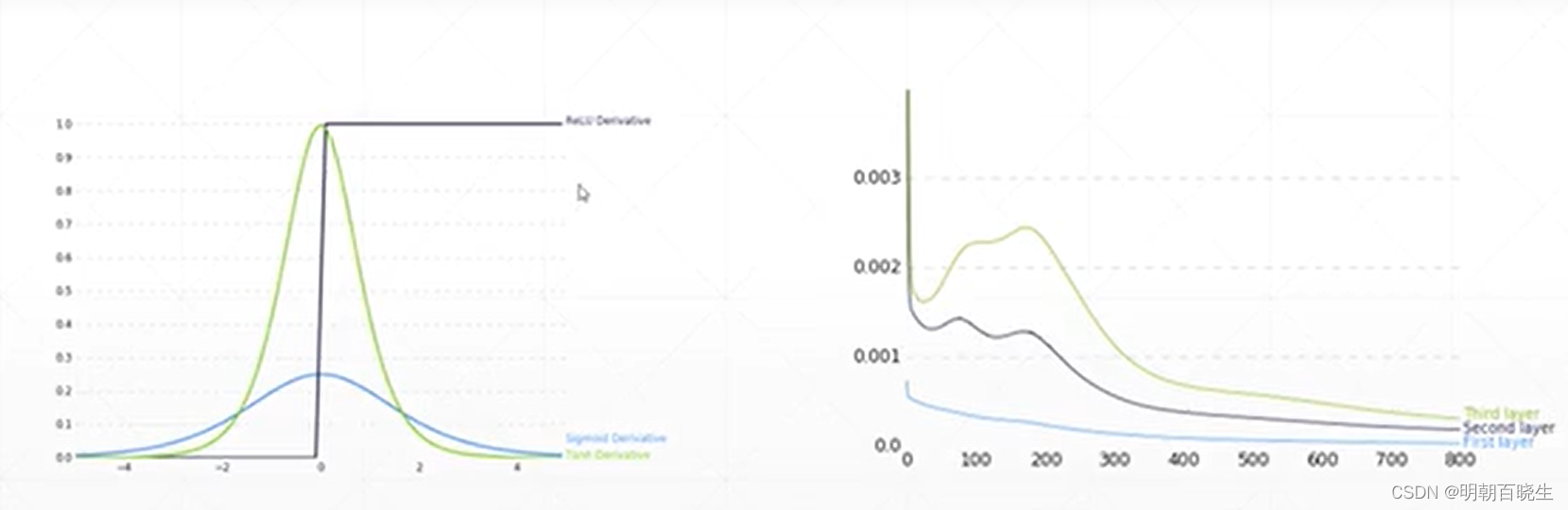
是由于时序链过程,导致梯度为0,前面的层参数无法更新。
解决方案 :
LSTM.
二 RNN 时序链问题
# -*- coding: utf-8 -*-
"""
Created on Mon Jul 24 15:12:49 2023@author: chengxf2
"""import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
import matplotlib.pyplot as plt # 导入作图相关的包'''生成训练的数据集
return x: 当前时刻的输入值[batch_size=1, time_step=num_time_steps-1, feature=1]y: 当前时刻的标签值[batch_size=1, time_step=num_time_steps-1, feature=1]
'''
def sampleData():#生成一个[0-3]之间的数据start = np.random.randint(3,size=1)[0]num_time_steps =20#时序链长度为num_time_stepstime_steps= np.linspace(start, start+10,num_time_steps)data = np.sin(time_steps)data = data.reshape(num_time_steps,1)#[batch, seq, dimension]x= torch.tensor(data[:-1]).float().view(1,num_time_steps-1,1)y= torch.tensor(data[1:]).float().view(1, num_time_steps-1,1)return x,y,time_steps'''网络模型args:input_size – 输入x的特征数量。hidden_size – 隐藏层的特征数量。num_layers – RNN的层数。nonlinearity – 指定非线性函数使用tanh还是relu。默认是tanh。bias – 默认是Truebatch_first – 如果True的话,那么输入Tensor的shape应该是[batch_size, time_step, feature],输出也是这样。默认是Falsedropout – 如果值非零,那么除了最后一层外,其它层的输出都会套上一个dropout层。bidirectional – 如果True,将会变成一个双向RNN,默认为False。
'''
class Net(nn.Module):def __init__(self,input_dim = 1, hidden_dim =10, out_dim = 1):super(Net, self).__init__()self.rnn= nn.RNN(input_size = input_dim, hidden_size = hidden_dim,num_layers = 1,batch_first = True)self.linear= nn.Linear(in_features= hidden_dim, out_features=out_dim)#前向传播函数def forward(self,x,hidden_prev):# 给定一个h_state初始状态,(batch_size=1,layer=1,hidden_dim=10)# 给定一个序列x.shape:[batch_size, time_step, feature]hidden_dim =10#print("\n x.shape",x.shape)out,hidden_prev= self.rnn(x,hidden_prev)out = out.view(-1,hidden_dim) #[1,seq,h]=>[1*seq,h]out = self.linear(out)#[seq,h]=>[seq,1]out = out.unsqueeze(dim=0) #[seq,1] 指定的维度上面添加一个维度[batch=1,seq,1]return out, hidden_prevdef main():model = Net()criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(),lr=1e-3)hidden_dim =10#初始值hidden_prv = torch.zeros(1,1,hidden_dim)for iter in range(5000):x,y,time_steps =sampleData() #[batch=1,seq=99,dim=1]output, hidden_prev =model(x,hidden_prv)hidden_prev = hidden_prev.detach()loss = criterion(output, y)model.zero_grad()loss.backward()optimizer.step()if iter %100 ==0:print("Iter:{} loss{}".format(iter, loss.item()))# 对最后一次的结果作图查看网络的预测效果plt.plot(time_steps[0:-1], y.flatten(), 'r-')plt.plot(time_steps[0:-1], output.data.numpy().flatten(), 'b-')
main()三 RNN 词组预测的例子
这是参考李沐写得一个实现nn.RNN功能的例子
,一般很少用,都是直接用nn.RNN.
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 26 14:17:49 2023@author: chengxf2
"""import math
import torch
from torch import nn
from torch.nn import functional as F
import numpy
import d2lzh_pytorch as d2l#生成随机变量
def normal(shape,device):return torch.randn(size=shape, device=device)*0.01#模型需要更新的权重系数
def get_params(vocab_size=27, num_hiddens=10, device='cuda:0'):num_inputs = num_outputs = vocab_sizeW_xh = normal((num_inputs,num_hiddens),device)W_hh = normal((num_hiddens,num_hiddens),device)b_xh = torch.zeros(num_hiddens,device=device)b_hh = torch.zeros(num_hiddens,device=device)W_hq = normal((num_hiddens,num_outputs),device)b_q = torch.zeros(num_outputs, device= device)params = [W_xh,W_hh, b_xh,b_hh, W_hq,b_q]for param in params:param.requires_grad_(True)return params#初始的隐藏值 hidden ,tuple
def init_rnn_state(batch_size, hidden_size, device):h_init= torch.zeros((batch_size,hidden_size),device=device)return (h_init,)#RNN 函数定义了如何在时间序列上更新隐藏状态和输出
def rnn(X, h_init, params):W_xh,W_hh, b_xh,b_hh, W_hq,b_q = paramshidden, = h_initoutputs =[]for x_t in X:z_t = torch.mm(x_t, W_xh)+b_xh+ torch.mm(x_t,W_hh)+b_hhhidden =torch.tanh(z_t)out = torch.mm(hidden,W_hq)+b_qoutputs.append(out)#[batch_size*T, dimension]return torch.cat(outputs, dim=0),(hidden,)#根据给定的词,预测后面num_preds 个词
def predict_ch8(prefix, num_preds, net, vocab, device):#生成初始状态state = net.begin_state(batch_size=1, device=device)#把第一个词拿出来outputs = [vocab[prefix[0]]]get_input = lambda: torch.tensor([outputs[-1]],device=device,(1,1))for y in prefix[1:]:_,state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds):y, state = net(get_input(), state)outputs, (int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idex_to_toke[i] for i in output])#梯度剪裁def grad_clipping(net, theta):if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad_]else:params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad**2)) for p in params)if norm > theta:for param in params:param.grad[:]*=theta/normclass RNNModel:#从零开始实现RNN 网络模型#def __init__(self, vocab_size, hidden_size, device, get_params, init_rnn_state,forward_fn):forward_fnself.vocab_size = vocab_size, self.num_hiddens = hidden_sizeself.params = get_params(vocab_size, hidden_size, device)self.init_state = init_rnn_state(batch_size, hidden_size, device)self.forwad_fn = forward_fn#X.shape [batch_size,num_steps] def __call__(self, X, state):X = F.one_hot(X.T, self.vocab_size).type(torch.float32)#[num_steps, batch_size]return self.forwad_fn(X, state, self.params)def begin_state(self, batch_size, device):return self.init_state(batch_size, self.num_hiddens, device)# 训练模型def train_epoch_ch8(net, train_iter, loss, updater, device,)state, timer = None, d21.Timer()metric = d21.Accumulator(2)for X,Y in train_iter:if state is None or use_random_iter:state = net.beign_state(bacth_size=X.shape[0])elseif isinstance(net, nn.Module) and not isinstance(o, t)state.detach_()elsefor s in state:s.detach_()y = Y.T.reshape(-1)X,y = X.to(device),y.to(device)y_hat,state=net(X,state)l = loss(y_hat,y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()elsel.backward()grad_clipping(net, 1)updater(batch_size=1)metric.add(1&y.numel(),y.numel())return math.exp(metric[0]/metric[1]))def train(net, train_iter,vocab, lr,num_epochs, device, use_random_iter=False):loss = nn.CrossEntropyLoss()animator = d21.animator(xlabel='epoch',ylabel='preplexity',legend=['train'],xlim=[10,num_epochs])if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(),lr)else:updater = lambda batch_size: d21.sgd(net.parameters,batch_size,lr)predict = lambda prefix: predict_ch8(prefix, num_preds=50, net, vocab, device)for epoch in range(num_epochs):ppl, spped = train_epoch_ch8(net, train_iter, updater(),use_random_iter())if (epoch+1)%10 ==0:print(predict('time traverller'))animator.add(epoch+1, [ppl])print(f'困惑度{ppl:lf},{speed:1f} 标记/秒')print(predict('time traveller'))print(predict('traveller'))def main():num_hiddens =512num_epochs, ,lr = 500,1vocab_size = len(vocab)#[批量大小,时间步数]batch_size, num_steps = 32, 10train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)F.one_hot(torch.tensor([0,2]), len(vocab))X= torch.arange(10).reshape((2,5))Y = F.one_hot(X.T,28).shape #[step, batch_num]model = RNNModel(vocab_size, num_hiddens, dl2.try_gpu(), get_params, init_rnn_state, rnn) train_ch8(model, train_iter, vocab,lr,num_epochs,dl2.try_gpu())if __name__ == "__main__":main()四 RNN简洁实现
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 28 10:11:33 2023@author: chengxf2
"""import torch
from torch import nn
from torch.nn import functional as Fclass SimpleRNN(nn.Module):def __init__(self,batch_size, input_size, hidden_size,out_size):super(SimpleRNN,self).__init__()self.batch_size,self.num_hiddens = batch_size,hidden_sizeself.rnn_layer = nn.RNN(input_size,hidden_size)self.linear = nn.Linear(hidden_size, out_size)def forward(self, X,state):'''Parameters----------X : [seq,batch, feature]state : [layer, batch, feature]-------#output:(layer, batch_size, hidden_size)state_new : []'''hidden, hidden_new = self.rnn_layer(X, state)hidden = hidden.view(-1, hidden.shape[-1])output = self.linear(hidden)return output ,hiddendef init_hidden_state(self):'''初始化隐藏状态'''state = torch.zeros((1,self.batch_size, self.num_hiddens))return statedef main():seq_len = 3 #时序链长度batch_size =5 #批量大小input_size = 27hidden_size = 10out_size = 9X = torch.rand(size=(seq_len,batch_size,input_size))model = SimpleRNN(batch_size,input_size, hidden_size,out_size)init_state = model.init_hidden_state()output, hidden = model.forward(X, init_state)print("\n 输出值:",output.shape)print("\n 时刻的隐藏状态")print(hidden.shape)if __name__ == "__main__":main()pytorch入门10--循环神经网络(RNN)_rnn代码pytorch_微扬嘴角的博客-CSDN博客
【PyTorch】深度学习实践之 RNN基础篇——实现RNN_pytorch实现rnn_zoetu的博客-CSDN博客
RNN 的基本原理+pytorch代码_rnn代码_黄某某很聪明的博客-CSDN博客
55 循环神经网络 RNN 的实现【动手学深度学习v2】_哔哩哔哩_bilibili
《动手学深度学习》环境搭建全程详细教程 window用户_https://zh.d21.ai/d21-zh-1.1.zip_溶~月的博客-CSDN博客
ModuleNotFoundError: No module named ‘d2l’_卡拉比丘流形的博客-CSDN博客