响应式网站推广seo站
匹配行首:^(脱字符号),匹配行尾$(美元符号)
^代表一个行的开始,$代表一行的结束
例如:
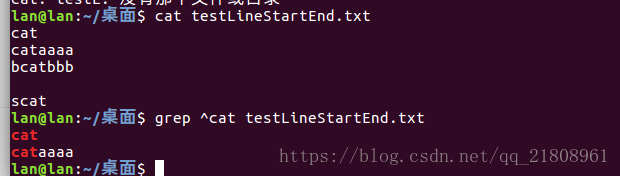
^cat只寻找行首有cat的
cataaaa--->匹配
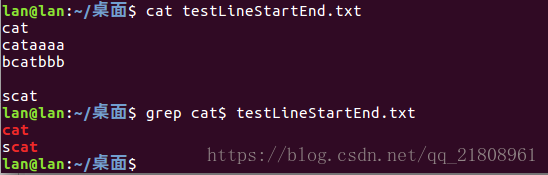
bcatbbb--->不匹配cat$只寻找行尾有cat的
scat--->匹配实例:
testLineStartEnd.txt
cat
cataaaa
bcatbbbscat匹配行首:grep ^cat testStartEnd.txt,匹结果如下:
匹配行尾:grep cat$ testStartEnd.txt,匹配结果如下:
按照单个字符来理解正则表达式
要养成按照单个字符来理解正则表达式的习惯,例如对于^cat这个正则表达式。
不正确的理解方式:^cat:匹配以cat开头的行。
正确的理解是:^cat:匹配以c作为一行的开头,然后紧接着一个a,再紧接着一个t的文本。
虽然这两种理解得到的结果并没有差异,但是按照字符来解读更易于明白遇到的正则表达式的内在逻辑。
脱字符^和美元符号$的特别之处就在于,他们匹配的是一个位置,而不是具体的文本。
实例:分析^cat$,^$,^
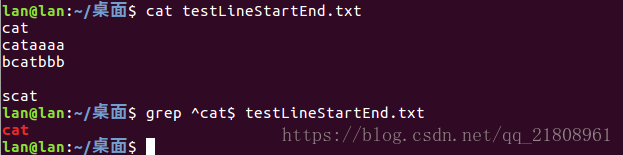
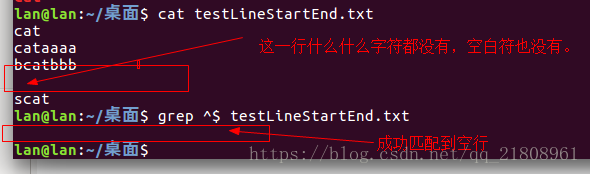
^cat$:行开头(显然每一行都有开头),然后有一个字符c,接着又一个字符a,然后是一个字符t,还有是行结束。所以也就是匹配只包含cat这三个字符的行,这行没有其他多余的单词或者空白符,或者其他字符,就只有cat^$:行开始,然后是行结束。也就是空行(没有任何其他字符,也没有任何空白符)^:匹配行开头,这是没有意义的,以为每一行都有行开头,所以是匹配所有行,空行也能匹配。
代码验证:
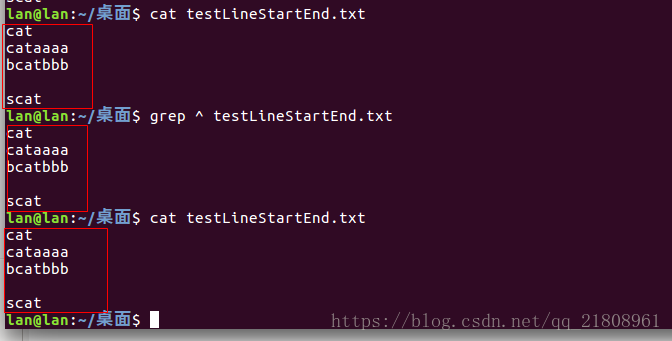
匹配包含cat这三个字符的行:grep ^cat$ testLineStartEnd.txt:
匹配空行:grep ^$ testLineStartEnd.txt
所有行都匹配:grep ^ testLineStartEnd.txt或者是grep $ testLineStartEnd.txt
字符组:[]
如果我们需要搜索的单词是grey,同时又不太确定它是否写作gray,就可使用字符组,字符组允许使用者列出在某处期望匹配的字符。例如e可以匹配字符e,a可以匹配字符a,而字符组[ea]能匹配字符a或者匹配字符e中的一个.
所以对于上面的问题,可以使用gr[ea]y来匹配。gr[ea]y的意思是:先找到一个字符g,后面跟着一个字符r,然后是一个a或者e,然后是一个字符y
应用:
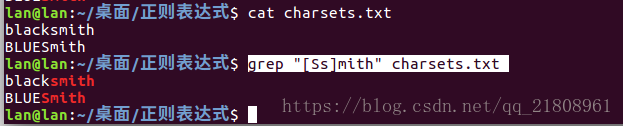
- 匹配单词首字母大小写的问题:[Ss]mith:这个表达式能匹配内嵌在其他单词里头的smith(或者是Smith)例如blacksmith这个单词。
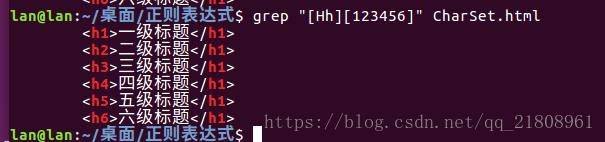
- 字符组[123456]:可以匹配1到6中的任何一个数字,[123456]可以作为<H[123456]>的一部分,用来匹配<H1>,<H2>,<H3>,<H4>,<H5>``<H6>这六个HTML标记,这样在搜索HTML代码的时候很有用。
实例1:大小写匹配:
charsets.txt:
blacksmith
BLUESmith命令:grep "[Ss]mith" charsets.txt ,匹配结果:
实例:搜索 CharSet.html中的HTML代码:
<!doctype html>
<html lang="en"><head><meta charset="UTF-8"><title>测试字符组</title>
</head><body><h1>一级标题</h1><h2>二级标题</h1><h3>三级标题</h1><h4>四级标题</h1><h5>五级标题</h1><h6>六级标题</h1></body></html>
匹配命令:grep "[Hh][123456]" CharSet.html,匹配结果如下。
字符数组元字符:-(连字符)
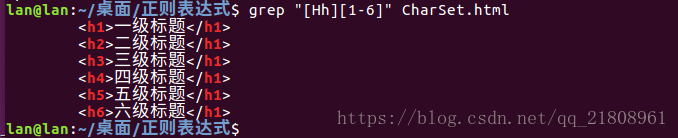
在字符数组内部,字符数组元字符- 表示一个范围。<H[1-6]>和<H[123456]>是完全一样的。
例如:[0-9]和[a-z]是用来匹配数字和小写字符的便捷写法。
在字符数组中使用多个连字符也是可以的,如[123456abcdefABCDEF]就可以简写为[1-6a-fA-F],也可以写作[a-f1-6A-F],字符数组中字符出现的顺序对结果无影响。
实例:
- 匹配十六进制数:[0-9a-fA-F]
- 匹配上面的HTML代码: 匹配命令: grep "[Hh][1-6]" CharSet.html,匹配结果如下。
还可随心所欲的把字符范围与普通文本结合起来使用,例如[0-9A-Z_!.?]能有匹配一个数字,或者一个大写字符,或者下划线,或者感叹号,或者点号,或者是问号
要注意的是在字符数组内部,只有连字符才是元字符,其他的字符(^开头除外)都表示普通字符,例如上面的点号.,就仅仅匹配点号,而不是匹配任意字符。同理上面的问号?在字符数组中也只是一个普通的字符。
还有一种情况是如果连字符出现在字符数组的开头,而不是连接两个字符,那也算是普通字符。
例如[-.?],连字符没有连接两个字符,所以这种情况下连字符是普通字符,不表示范围,根据前面说的,这里的点号,和问号也是普通字符。
排出形字符组:[^...]
用[^...]取代[...],这样就能匹配没有列出的字符,例如:[^1-6]可以匹配处理1-6之外的任何其他字符。这个字符组中的字符以^开头,表示排出的意思。
例子
现在需要从一堆英文单词中搜索出一些特殊的单词:在这些单词总,字母q后面的字母不是字母u。则这个正则表达式是:q[^u]。
实例:
word.txt
Iraq
Qantas
agree 同意
bond 使结合
build 建筑
building 建筑物
error 错误
example 例子
feather 羽毛
ferry 渡口
field 田野
furniture 家具
limit 界线
manage 管理
nationality 国籍
nearly 几乎
pence 便士
punish 处罚
rat 老鼠
salad 沙拉
search 寻找
stewardess 女管家
unconditional 无条件的
unemployment 失业
quadrangle 四边形
qaq 哭唧唧
QAQ 哭嘤嘤
valley 山谷
water 水 使用正则表达式q[^u]:
(用的是linux中)
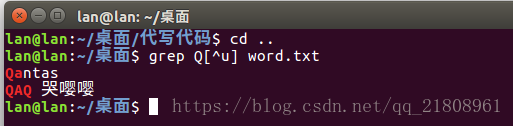
$ cat word.txt|grep q[^u]运行结果:(Ubutu系统中)

word.txt中有两个行需要注意,第一行伊拉克Iraq和澳大利亚航空公司的名字Qantas。尽管它们都在word.txt中,但是,却不在grep q[^u]的结果中。这是为什么呢。
Qantas无法匹配的原因是,正则表达使用使用的是小写q,而Qantas中的Q是大写的,如果改用Q[^u]则就能匹配Qantas。不过这样,其他只有小写q的单词又不在结果中,因为它们有没大写Q。
如果要同时匹配大小写,则可以写成[Qq][^u]。

Iraq的例子无法匹配,是因为正则表达式q[^u]要求字符q之后紧跟着一个除了u以外的字符,也就是手q后面需要有一个字符,Iraq这一行q后面直接就是行尾了(换行符)。所以在字符q之后,没能匹配到除了u以外的其他字符(就根本没有字符了)。通常来说,文本行的结尾都有一个换行符,但是grep会在使用正则表达式匹配之前把这些换行符去掉。所以字符q之后相当于没有字符。如果想要匹配到Iraq也很简单,在Iraq后面加上一个除了u以外的字符即可,空格或者其他都行。从上面Iraq的例子中可以看出:
一个字符组,即使是排出型字符组,都需要匹配一个字符
匹配任意字符:.(点号)
元字符.(通常称为点号)是用来匹配任意字符的字符组的简便写法。
如果我们需要在正则表达式中,使用一个匹配任何字符的占位符,用点号就很方便。
例如: 我们需要匹配上11/22/33,11-22-33,11.22.33我们可以使用一个包含/,-,.这三个字符的字符组来构建正则表达式:11[-/.]22[-/.]33,也可以使用11.22.33
实例:
textPoint.txt
11/22/33
11-22-33
11.22.33运行效果:
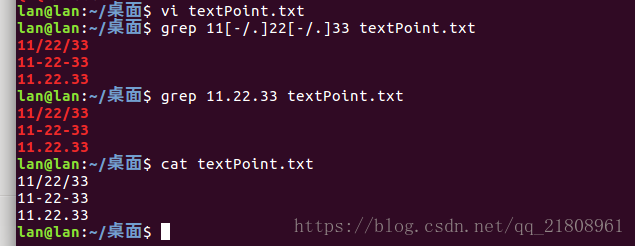
要注意的是在上面的正则表达式11[-/.]22[-/.]33中,点号并不是元字符,它就是点号的意思,不是任意字符。连字符-放在字符组中的最左边也不是元字符,不表示返回,它同样只表示连字符,没有范围的意思。如果是11[.-/]22[/-.]33则这个连字符-就表示范围,因为它不再字符组的开头,而是在字符.和字符/之间。
在上面的正则表达式11.22.33中点号是元字符,它能匹配任意字符(包括我们想要的-,.,/这三个字符。)。不过因为点号元字符可以匹配任意字符,所以也能匹配下面的这些字符:
11@22@33
www11#22$33
11a22b33c代码验证
在上面的textPoint.txt中加入上面的几行字符串,修改后的textPoint.txt如下
11/22/33
11-22-33
11.22.33
11@22@33
www11#22$33
11a22b33c输入命令进行匹配:grep 11.22.33 textPoint.txt,运行结果:
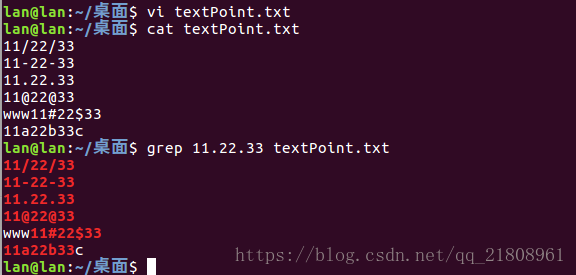
所以11[-/.]22[-/.]33这个正则表达式更加精确,不过比较难读,也比较难写,11.22.33这个正则表达式更容易理解一点。
应该选择哪种方式,取决于对需要检索的文本的了解,以及你需要达到的准确程度。一个常见的问题是,写正则表达式时,我们需要对要检索的的了解程度和检索精确性之间求得平衡。例如,我们知道针对某个文本,使用11.22.33这个正则表达式基本不可能匹配到我们不期望的结果,则使用11.22.33就是合理的。要想正确的使用正则表达式,清楚的了解目标文本是非常重要的。
多选结构:|
|是一个非常便捷的元字符,它的意思是或(or),使用或元字符,我们可以把不同的子表达式组合成一个总的表达式,而这个总的表达式又能匹配到里面任意的子表达式。例如Bob和Robert是两个表达式,但Bob|Rober就能有同时匹配Bob或Robert中任意一个。在这样的组合中子表达式被称为多选分支
回头来看gr[ae]y的例子,学了多选分支之后,它还可以写作grey|gray,或者是gr(a|e)y。后者用括号来划定多选的范围(正常情况下括号也是元字符)。
不过要注意gr[a|e]y就不符合要求,因为在字符组中|就不是元字符,就表示该字符本身(竖杠)。
而对于表达式gr(a|e)y,使用括号是必须的,如果不使用括号,则变成gra|ey,匹配的就是gra或者ey了,这不符合我们的要求。
多选结构可以包括很过字符,但是不能超越括号()的界限。
关说不练假把式,先来写个例子练练。
testOr.txt的内容
Bob
Robert
Lili
Lusi
Tom
Smith
Francis因为在linux中使用|作为管道符,所以要想使用grep支持多选的话要换成下面的写法:
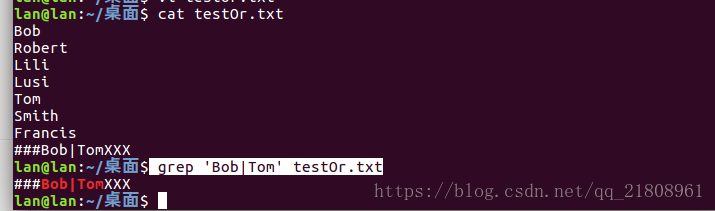
grep -E 'Bob|Tom' testOr.txt匹配结果:
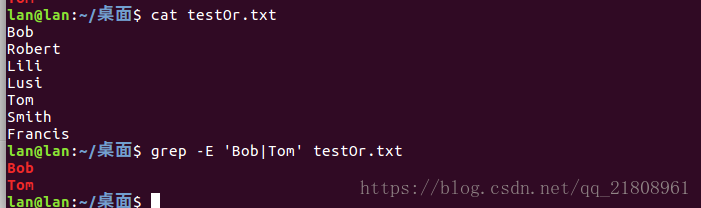
这里要说明的是,使用参数-E可以实现多选功能。如果不加入-E参数写成
grep 'Bob|Tom' testOr.txt 这样的话shell会认为是在查找"Bob|Tom"这个字符,里面的|会认为就是一个竖杠字符,而不是或元字符。
不信我们来继续写例子验证:
修改testOr.txt为:
Bob
Robert
Lili
Lusi
Tom
Smith
Francis
###Bob|TomXXX然后输入命令:
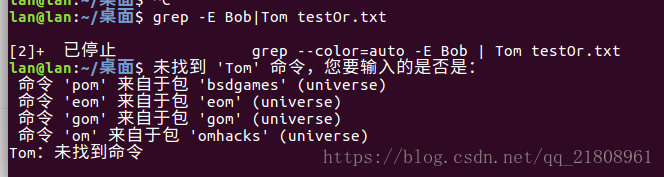
grep 'Bob|Tom' testOr.txt匹配结果:
Linux,shell中,使用grep支持多选操作除了要加上-E参数外,还要用引号把正则表达式是包裹起来。不然shell会认为|是管道符,而运行错误。
不加引号运行出现的错误结果如下:
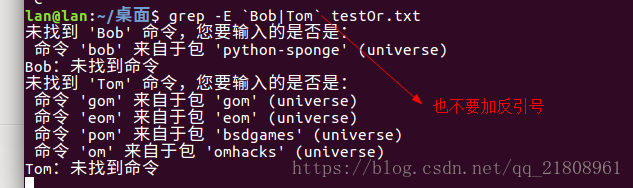
也不要加反引号,加反引号运行也错误。
下面来验证gr(a|e)y这个正则表达式。
修改testOr.txt如下,加入gray和grey这两个单词:
Bob
Robert
Lili
Lusi
Tom
Smith
Francis
###Bob|TomXXX
gray
grey分别使用正则表达式式:gr(a|e)y,gray|grey,gr[ae]y,匹配效果如下图。
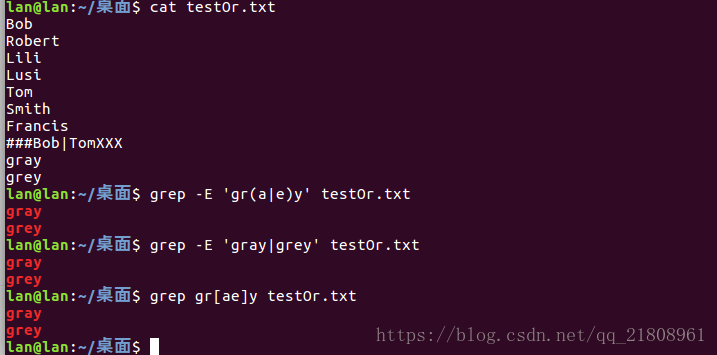
可以看到上面这三个正则表达式匹配的结果都是一样的。
另一个例子是First|1st.[Ss]treet(这里使用点号.元字符来代替空格,这样容易识别),因为First和1st都是以st结尾的,我们可以把First|1st.[Ss]treet这个正则表达式简写为(Fir|1)st.[Ss]treet。
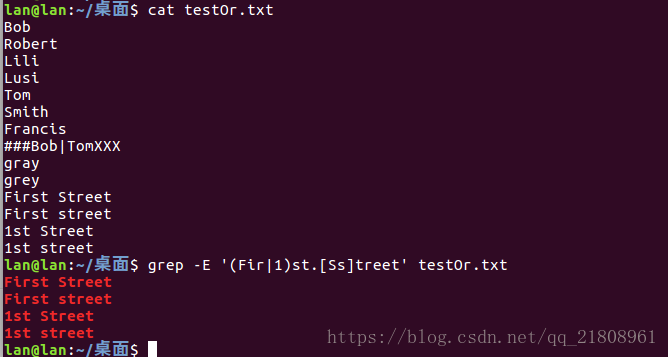
gr[ea]y和gr(e|a)y的例子可能会让人觉得多选结构与字符组没有太大的区别,其实不是这样的。
多选结构(…|…)与字符组[…]的区别
一个字符组只能匹配目标文本中的单个字符,而多选结果自身都可能是完整的正则表达式,都可以匹配任意长度的字符。
字符组基本可以算是一门独立的微型语言(例如,对于字符组中的元字符,字符组对这些元字符有自己的规定,例:点号.字字符组中就不算元字符,竖杠|在字符组中也不能算多选元字符))。而多选结构是正则表达式语言主体的一部分,这两者都是很有用的。
同时使用多选结构(...|...)和行首^,行尾$
在一个包换多选结构的表达式中使用脱字符^和美元符$要小心。比较^From|Subject|Date:.和^(From|Subject|Date):.这两个正则表达式就会发现,虽然这两个正则表达式看起来很像,但是它们匹配的结果却是大不相同的。第一个表达式由3个多选分支构成,所以第一个能匹配^From或者Subject或者Date:.。如果我们希望每一个多选分支之前都有脱字符^,之后都有:.,那应该用括号把这个几个多选分支”限制”起来:^(From|Subject|Date):.,现在三个多选分支都受到了括号的限制,所以,这个^(From|Subject|Date):.正则表达式的意思是:匹配一行的起始位置,然后匹配From,Subject或者Date中的任意一个,最后匹配:.。所以^(From|Subject|Date):.能匹配的文本是:
- 行开始,然后是字符:
F,r,o,m,然后是:. - 或者,行开始,然后是字符:
S,u,b,j,e,c,t,然后是:. - 或者,行开始,然后是字符:
D,a,t,e,然后是:.
换句话说,就是匹配Form:.或者是Subject:.或者Date:.开头的文本行。
既然要使用邮件的信息,这里也没有现成的邮件信息,我们就去导出一个邮件的信息使用。
导出邮件的的步骤如下: - 登录邮件客户端(我这里是网易闪电邮)随便找个邮件导出,我这导出一个网易的广告邮件
- 选中邮件,右键打开右键信息
- 现在可以看到该邮件的信息了,为了方便后面用正则表达式匹配,这里把该信息保存下来,选择
另存为即可
- 保存该邮件信息到本地中,命名为
emailExport.txt
- 选中邮件,右键打开右键信息
把导出的emailExport.txt拷贝到虚拟机中。然后执行命令:grep -E "^(From|Subject|Date):." emailExport.txt ,匹配效果如下。

忽略大小写
上面的E-mail header的例子很适合用来说明不区分大小写的匹配的概念。E-mail header中的字段类型通常是以大写字母开头的,例如上面的From,Subject。不过E-mail标准并没有对大小写进行严格的规定,所以DATE和date都是合法的字段类型。但是之前的正则表达式^(From|Subject|Date):.就无法处理这用有大小写的情况了。
有一种办法就是使用[Ff][Rr][Oo][Mm]来代替from们,这用就能匹配任何形式的from。但是这种方法的缺点也很明显,使用起来很不方便。
另一种方法是在使用grep进行正则匹配的时候,加上-i参数,告诉grep在匹配是忽略大小写,也就是不进行大小写匹配,这样就能忽略大小写字母的差异。
在上面的命令中加上- i参数即可忽略大小写,为了演示方便,我们把上面的From,Subject,Date,全部改成小写形式。修改后新的命令为:grep -i -E "^(from|subject|date):." emailExport.txt,两个命令对比效果如下图。

可以看到如果不指明忽略大小写,grep在匹配是会匹配全部的字符。所以grep -E "^(from|subject|date):." emailExport.txt命令将匹配不到任何信息。
需要注意的是忽略大小写的功能并不是正则表达式的一部分,不过许多工具软件都提供了忽略大小写的功能。
egrep 和grep的区别
egrep = grep -E 所以,egrep 可以使用基本的正则表达外, 还可以用扩展表达式。使用的语法及参数可参照grep指令,与grep的不同点在于解读字符串的方法。
egrep是用 扩展正则表达式(extended regular expression)语法来解读的,而grep则用基本正则表达式(basic regular expression)语法解读,extended regular expression比basic regular expression的表达更规范。
单词分界符
使用正则表达式时会遇到的有一个问题,期望匹配到的单词包含在另一个单词之中。在前面的cat,gray,Smith的例子中,曾提到这个问题。不过某些版本的egrep对单词分界符(单词开始和结束的位置)的匹配。
如果你的egrep(或者grep)支持元字符序列\<和\>,只可以使用者两个元字符序列来匹配单词的开头和结束位置。可以把这两个单词分界符想象成单词版本的^和$。就像^和$一样,单词分界符\<和\>匹配的是位置,在匹配过程中不对应任何字符。
正则表达式\<cat\>的意思是:匹配单词的开头的位置,然后匹配c,a,t这三个字符,然后匹配单词的结束位置。换句话说就是匹配cat这个单词,如果愿意这么解读的话。也可以用用\<cat来匹配以cat开头的单词,或者用cat\>来匹配以cat结尾的单词
还有就是<和>本身不是元字符,只有它们和斜杠一起使用的时候,字符序列\<和字符序列\>才有单词分界符的意义。所以把字符序列\<和字符序列\>称为元字符序列
并不是所有版本的egrep或者grep都支持单词分界符,即使支持的版本也不见得聪明到能认得出英语单词。单词的起始位置只不过是一系列字母好和数字开始的位置,而结束位置就是字母和数字结束的地方。单词的开始和结束准确的来说是字母或数字开始和结束的地方**,不过这样说显得太麻烦了。
实例:
testWordStartEnd.txt:
catStart cat2 ##cat3 cats scat2 endCat endcat
cat CAT
cat 222 333
##@@%%^&*匹配c开头的单词:egrep "\<c" testWordStartEnd.txt

匹配c开头的单词,忽略大小写:egrep -i "\<c" testWordStartEnd.txt

匹配cat开头的单词,忽略大小写: egrep -i "\<cat" testWordStartEnd.txt

匹配cat结尾的单词,忽略大小写: egrep -i "cat\>" testWordStartEnd.txt

匹配数字2开头的单词:egrep -i "\<2" testWordStartEnd.txt

实际上222这个字符串根本就不是英文单词,所以说\<和\>,实际上是匹配字母或数字的开始位置,结束位置更加精确一点。只是这样说比较拗口,说单词分界符简单一点。
结合之前字字符组使用,匹配以数字开头的字符串: egrep -i "\<[0-9]" testWordStartEnd.txt

匹配只有三个数字的单词(字符串):egrep "\<[0-9][0-9][0-9]\>" testWordStartEnd.txt

匹配只有三个字母的字符串:egrep "\<[a-zA-Z][a-zA-Z][a-zA-Z]\>" testWordStartEnd.txt

小结:至今为止学过的元字符
| 序号 | 元字符(元字符序列) | 名称 | 匹配对象 |
|---|---|---|---|
| 1 | . | 点号 | 单个任意字符 |
| 2 | [...] | 字符组 | 字符组中列出的任意一个字符 |
| 3 | [^...] | 排出型字符组 | 字符组中没有列出的一个任意的字符 |
| 4 | ^ | 脱字符 | 行的起始位置 |
| 5 | $ | 美元符 | 行的结束位置 |
| 6 | | | 竖杠(竖线) | 匹配分隔与竖线两边的任意一个表达式 |
| 7 | (...|...) | 括号 | 显示竖线的作用范围 |
| 8 | \< | 反斜杠-小于号 | 单词的起始位置(有些版本的egrep不支持) |
| 9 | >\ | 大于号-反斜杠 | 单词的结束位置(有些版本的egrep不支持) |
另外还有几点需要注意:
在字符组内部,元字符的定义规则(及它们的意义)是不一样的
- ,例如在字符组外面,点号
.是元字符,但是在字符组内部点号.则不是元字符。相反 - 连字符
-只有在字符组内部才是元字符,而且,连字符之后在两个字符中间才有范围则作用,如果连字符紧跟则中括号,则不能表示范围,如[-abc],[abc-],这两个例子中的连字符都不表示范围,只表示连字符本身,而不是元字符。 - 脱字符^在字符组外部,表示行开头,在字符组内部只有紧紧跟在字符组开始符号
[构成:[^...]才有特殊意义,两者表示排出行字符组的意思。如果脱字符^没有紧紧跟在中括号[的后面,如[…^]则就没有其他意思,这时的脱字符就表示脱字符,而不是元字符。
- ,例如在字符组外面,点号
不要混淆多选向和字符组。
- 字符组[abc]和多选项(a|b|c)固然表示同一个意思,但是这个例子中的相似性并不能推广开来。无论列出的字符有多少,字符组只能匹配一个字符,但是多选项可以匹配任意长度的文本,每个多选性可能匹配的文本都是独立的。例如:`<(1,000,000|millon|thousand*thousand)>`,不过多选项没有项字符组那样的排出功能。
排出型字符组是表示所有没有列出的字符的
字符组的简便写法,因为始终是字符组,所有排出型字符组也一定要占一个字符的位置,所以[^x]的意思不是只用当这个位置不是x才能匹配,而是匹配一个字符,这个字符不是x,这两个意思的差别是很细微的,只有当这个位置不是x才能匹配这句话,则换行符也能匹配,但是匹配一个字符,这个字符不是x这句话就不会匹配换行符,因为换行符本身在正则匹配中会被忽略掉。- 使用
-i参数可以告诉egrep在匹配是不区分大小写,egrep默认支持扩展型正则表示是,grep默认支持基本型正则表达式,使用egrep和使用grep -E效果是一样的。这是因为,gerp指令中,使用-E参数则grep使用扩展型正则表达式