引言
- 这里翻译了HiFi-GAN这篇论文的具体内容,具体链接。
- 这篇文章还是学到了很多东西,从整体上说,学到了生成对抗网络的构建思路,包括生成器和鉴定器。细化到具体实现的细节,如何 实现对于特定周期的数据处理?在细化,膨胀卷积是如何实现的?这些通过文章,仅仅是了解大概的实现原理,但是对于代码的实现细节并不是很了解。如果要加深印象,还是要结合代码来具体看一下实现的细节。
- 本文主要围绕具体的代码实现细节展开,对于相关原理,只会简单引用和讲解。因为官方代码使用的是pytorch,所以是通过pytorch展开的。
- 当前这篇主要介绍鉴别器的具体实现,在HiFi-GAN中,鉴别器分是由周期鉴别器和尺度鉴别器构成,当前这篇将就两种鉴别器的原理和功能进行具体讲解。
正文
鉴别器
- 因为声音信号中的长依赖比较重要,常规的做法是通过增加鉴别器的感受野,或者增加输入数据的维度来获取这种长领域特征。在HiFi-GAN是采用了增加输入信号的范围,采用多尺度鉴定器实现MSD。另外因为声音可以通过短时傅立叶变换,拆解成不同的周期的正弦信号叠加,HiFi-GAN专门采用了多周期鉴定器见捕捉每一段信号的不同周期特征。
多周期鉴定器
- 多周期鉴定器是有专门针对不同周期信号的若干子鉴定器构成,对于多周期信号,是通过对原始的波形信号进行不同间隔进行采样,将原来的一维波形数据,变成二维信号,然后在对其进行卷积。而且每一次卷积都是专门针对某一行数据,也就是某一个间隔采样生成的数据。具体可以看如下示意图。
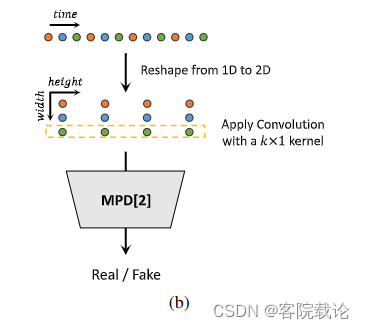
- 由于数据经过等间隔采样,每一行是某一个周期信号,然后若干行表示有若干个周期信号,然后进行宽度为1,高度为特定长度的周期T/p的二维卷积采样,具体如下。每一个颜色都是按照一定间隔进行采样之后的数据,然后整个卷积层也是按照一个周期进行生成的。
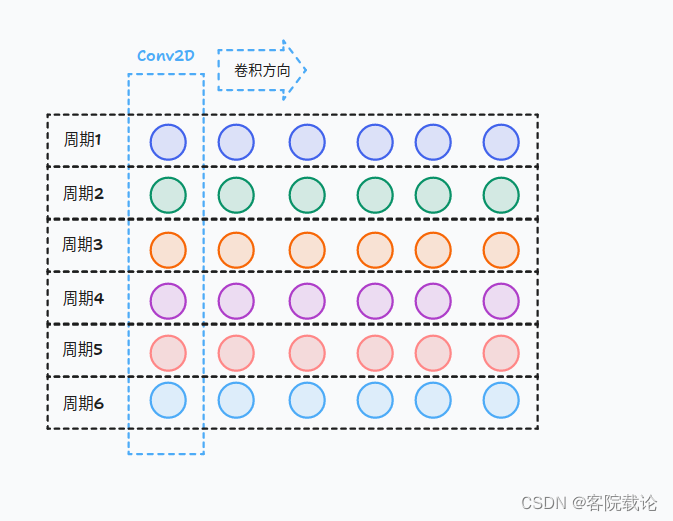
- 网络具体结构图下,鉴别输入的是真实的波形图和生成波形图,然后输出两者相似的概率值,进而衡量两者的相似程度,具体模型如下,就是若干个卷积模块的堆叠。
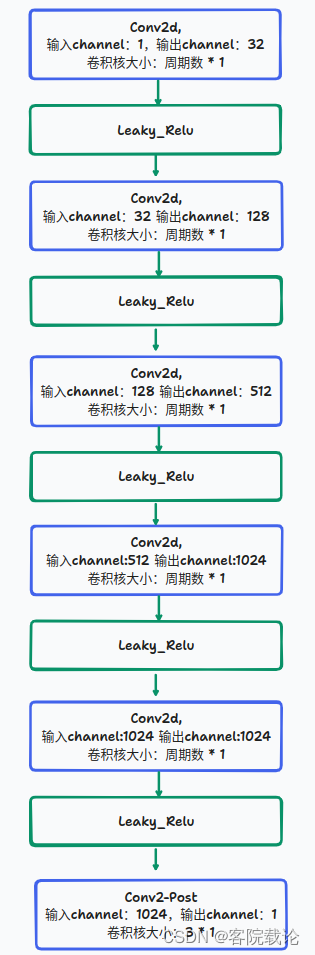
- 多周期鉴定器具体实现代码在,整个多周期鉴定器是由若干个子周期鉴定器构成,所以代码也是分成两个部分。
- 具体的单个周期鉴定器已经定义过了,然后就是最终的总的周期鉴定器的结构,就是多个不同周期的子鉴定器具的输出构成的列表
class DiscriminatorP(torch.nn.Module):def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):super(DiscriminatorP, self).__init__()self.period = period norm_f = weight_norm if use_spectral_norm == False else spectral_normself.convs = nn.ModuleList([norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(2, 0))),])self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))def forward(self, x):fmap = []b, c, t = x.shapeif t % self.period != 0:n_pad = self.period - (t % self.period)x = F.pad(x, (0, n_pad), "reflect")t = t + n_padx = x.view(b, c, t // self.period, self.period)for l in self.convs:x = l(x)x = F.leaky_relu(x, LRELU_SLOPE)fmap.append(x)x = self.conv_post(x)fmap.append(x)x = torch.flatten(x, 1, -1)return x, fmap
class MultiPeriodDiscriminator(torch.nn.Module):def __init__(self):super(MultiPeriodDiscriminator, self).__init__()self.discriminators = nn.ModuleList([DiscriminatorP(2),DiscriminatorP(3),DiscriminatorP(5),DiscriminatorP(7),DiscriminatorP(11),])def forward(self, y, y_hat):y_d_rs = [] y_d_gs = [] fmap_rs = [] fmap_gs = [] for i, d in enumerate(self.discriminators):y_d_r, fmap_r = d(y)y_d_g, fmap_g = d(y_hat)y_d_rs.append(y_d_r)fmap_rs.append(fmap_r)y_d_gs.append(y_d_g)fmap_gs.append(fmap_g)return y_d_rs, y_d_gs, fmap_rs, fmap_gs
多尺度鉴定器
- 上一节中的多周期鉴定器是将数据进行间隔采样,然后卷积处理。并没有处理连续的采样点,也就获得不了音频数据的长领域依赖。不同于生成其中使用反卷积进行的上采样,这里使用了平均池化,缩小数据的范围,然后让一个数据浓缩更多的信息 ,然后进行分别进行特征提取操作。具体见下图。
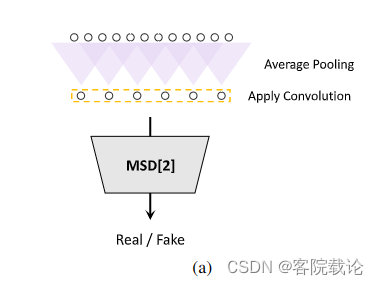
- 不同于多周期鉴定器,多尺度鉴定器中的子鉴定器是相同的,不同的是输入的信号,经过的平均池化的倍数不同,所以每一个采样点包含的信息维度就不同。具体的单个鉴定器的结构如下
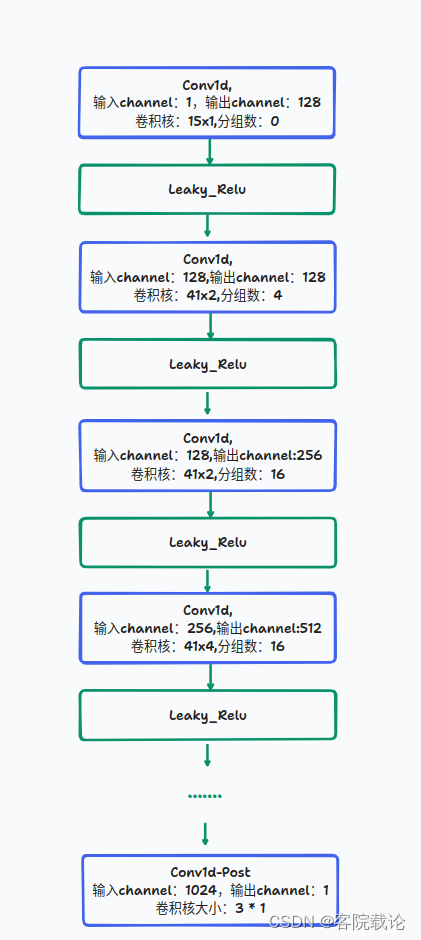
- 具体代码实现如下,首先经过平均池化层,然后再经过不同的平均特征提取层
class DiscriminatorS(torch.nn.Module):def __init__(self, use_spectral_norm=False):super(DiscriminatorS, self).__init__()norm_f = weight_norm if use_spectral_norm == False else spectral_normself.convs = nn.ModuleList([norm_f(Conv1d(1, 128, 15, 1, padding=7)),norm_f(Conv1d(128, 128, 41, 2, groups=4, padding=20)),norm_f(Conv1d(128, 256, 41, 2, groups=16, padding=20)),norm_f(Conv1d(256, 512, 41, 4, groups=16, padding=20)),norm_f(Conv1d(512, 1024, 41, 4, groups=16, padding=20)),norm_f(Conv1d(1024, 1024, 41, 1, groups=16, padding=20)),norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),])self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))def forward(self, x):fmap = []for l in self.convs:x = l(x)x = F.leaky_relu(x, LRELU_SLOPE)fmap.append(x)x = self.conv_post(x)fmap.append(x)x = torch.flatten(x, 1, -1)return x, fmapclass MultiScaleDiscriminator(torch.nn.Module):def __init__(self):super(MultiScaleDiscriminator, self).__init__()self.discriminators = nn.ModuleList([DiscriminatorS(use_spectral_norm=True),DiscriminatorS(),DiscriminatorS(),])self.meanpools = nn.ModuleList([AvgPool1d(4, 2, padding=2),AvgPool1d(4, 2, padding=2)])def forward(self, y, y_hat):y_d_rs = []y_d_gs = []fmap_rs = []fmap_gs = []for i, d in enumerate(self.discriminators):if i != 0:y = self.meanpools[i-1](y)y_hat = self.meanpools[i-1](y_hat)y_d_r, fmap_r = d(y)y_d_g, fmap_g = d(y_hat)y_d_rs.append(y_d_r)fmap_rs.append(fmap_r)y_d_gs.append(y_d_g)fmap_gs.append(fmap_g)return y_d_rs, y_d_gs, fmap_rs, fmap_gs
问题
- 对于音频信号的采样间隔合理吗?
- 音频信号确实是由不同的频率的正弦波构成,但是这些音频的频率不同,他设置的采样间隔并没有任何根据,仅仅是因为他们是质数?这种采样周期设定,不应该根据对音频信号的分析去确定吗。
- 谱归一化和常规的归一化有什么不同?
- 权重归一化:通过对每一个神经元的权重向量进行归一化,加夸模型的收敛速度,减少训练时间。
- 谱归一化:用于约束神经网络 权重的方法,主要用于生成对抗网络。通过将权重矩阵的谱范数(即权重矩阵的最大奇异值)归一化到1来实现,借此方式GAN训练过程中的模式崩溃问题。
- 总结:两者的作用不同,权重归一化是通过修改网络权重,加速收敛和改进有化。谱归一化用于约束GAN判别函数,确保满足某些数学性质。
总结
- 在上一篇博客中,已经整理过了生成器的相关代码,生成器为了获取更加全局更加细致的信息,对数据进行了上采样,使得数据尽可能在时间维度上和原始的音频信号相同。到了鉴定器,在多周期鉴定器中,针对周期的特征提取是考虑了全局信息,从全局的角度出发。然后在多尺度鉴定器中,又使用了三个池化层,然后分别保留不同尺度下特征。
- 对于GAN模型而言,最重要的还是生成器,然后鉴定器是起到了一个引导作用。鉴定器的考虑的越周到,相应的,生成器的生成的结果也就越准确。