合肥网站设计制作百度搜索指数查询
目录
RAG的工作流程
python实现RAG
1.引入相关库及相关准备工作
函数
1. 加载并读取文档
2. 文档分割
3. embedding
4. 向集合中添加文档
5. 用户输入内容
6. 查询集合中的文档
7. 构建Prompt并生成答案
主流程
附录
函数解释
1. open() 函数语法
2.client.embeddings.create()
3.collection.query()
完整代码
RAG的工作流程
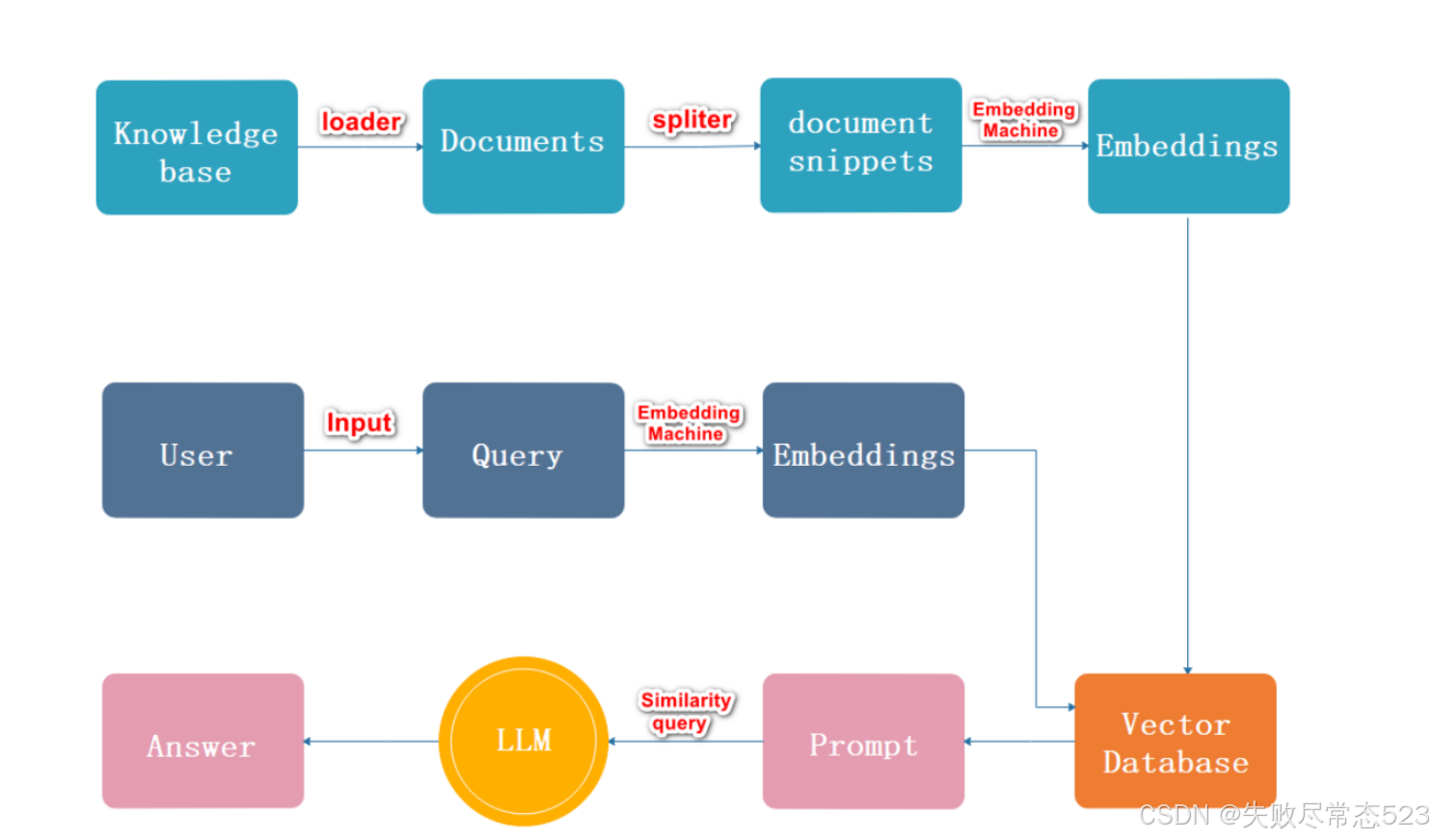
流程描述
加载,读取文档
文档分割
文档向量化
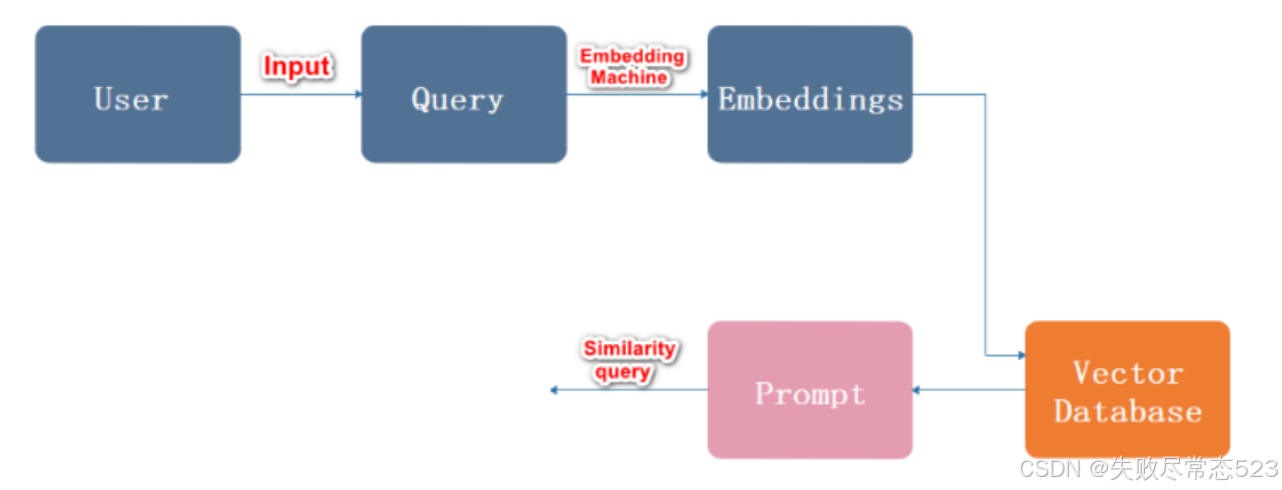
用户输入内容
内容向量化
文本向量中匹配出与问句向量相似的 top_k 个
匹配出的文本作为上下文和问题一起添加到 prompt 中
提交给 LLM 生成答案
Indexing过程

Retrieval过程
python实现RAG
1.引入相关库及相关准备工作
import chromadb # 导入 chromadb 库
from openai import OpenAI # 导入 OpenAI 库client = OpenAI() # 创建一个 OpenAI 客户端实例file_path = "./巴黎奥运会金牌信息.txt"# 创建一个 chroma 客户端实例
chroma_client = chromadb.Client()# 创建一个名为 "my_collection" 的集合
collection = chroma_client.create_collection(name="my_collection")函数
1. 加载并读取文档
# 1. 加载并读取文档
def load_document(filepath):with open(filepath, 'r', encoding='utf-8') as file:document = file.read()return documentdef load_document(filepath):
定义一个名为 load_document 的函数,并接收一个参数 filepath,表示要读取的文件路径。
with open(filepath, 'r', encoding='utf-8') as file:
使用 open() 函数打开 filepath 指定的文件。
'r' 表示以只读模式打开文件。
encoding='utf-8' 指定UTF-8 编码,以确保能够正确处理包含中文或其他特殊字符的文件。
with 语句用于上下文管理,可以在读取文件后自动关闭文件,防止资源泄露。
document = file.read()
2. 文档分割
# 2. 文档分割
def split_document(document):# 使用两个换行符来分割段落chunks = document.strip().split('\n\n')return chunks # 返回包含所有文本块的列表1. def split_document(document):
- 这是一个函数定义,
document是输入的文本(字符串类型)。 - 该函数的作用是按照段落分割文本。
2. document.strip()
strip()方法用于去掉字符串开头和结尾的空白字符(包括空格、换行符\n、制表符\t等)。- 这样可以避免因为文本头尾的换行符导致分割时出现空字符串。
3. .split('\n\n')
split('\n\n')按照两个连续的换行符分割文本。\n代表换行,而\n\n代表两个换行符,通常用于分隔不同的段落。- 这个方法会返回一个列表,其中每个元素是一个段落。
4. return chunks
chunks是分割后的文本块列表,返回它供后续使用。
3. embedding
# 3. embedding
def get_embedding(texts, model="text-embedding-3-large"):result = client.embeddings.create(input=texts,model=model)return [x.embedding for x in result.data]封装embedding模型。
4. 向集合中添加文档
# 4. 向集合中添加文档
def add_documents_to_collection(chunks):embeddings = get_embedding(chunks) # 获取文档块的嵌入collection.add(documents=chunks, # 文档内容embeddings=embeddings, # 文档对应的嵌入向量ids=[f"id{i+1}" for i in range(len(chunks))] # 生成文档 ID)这段代码定义了 add_documents_to_collection 函数,用于将文档(chunks)添加到一个集合(collection)中,并为每个文档计算嵌入(embedding)。这个过程通常用于向量数据库(如 FAISS、ChromaDB 或 Pinecone),以支持向量搜索、相似性检索和信息检索。
embeddings = get_embedding(chunks) # 获取文档块的嵌入
- 调用
get_embedding(chunks),为chunks中的每个文本计算嵌入(embedding)。 embeddings是一个嵌入向量列表,每个向量对应chunks里的一个文本片段。
collection.add(
collection是一个数据库或向量存储集合,可以是 ChromaDB、FAISS、Pinecone 等向量数据库对象。.add()方法用于向集合中添加数据,包括原始文档、嵌入向量和唯一 ID。
ids=[f"id{i+1}" for i in range(len(chunks))] # 生成文档 ID
ids是文档唯一标识符,用于在数据库中区分不同文档。f"id{i+1}"生成 "id1", "id2", "id3" 这样的字符串 ID。for i in range(len(chunks))依次编号,确保每个文档有唯一 ID。
示例
输入
假设 chunks 是:
chunks = ["文本片段1", "文本片段2", "文本片段3"]
执行:
add_documents_to_collection(chunks)
执行过程
1.计算 chunks 的嵌入:
embeddings = get_embedding(chunks)
假设返回:
[[0.1, 0.2, 0.3], # 文本片段1的嵌入[0.4, 0.5, 0.6], # 文本片段2的嵌入[0.7, 0.8, 0.9] # 文本片段3的嵌入
]
2.添加到 collection:
collection.add(documents=["文本片段1", "文本片段2", "文本片段3"],embeddings=[[0.1, 0.2, 0.3],[0.4, 0.5, 0.6],[0.7, 0.8, 0.9]],ids=["id1", "id2", "id3"]
)
5. 用户输入内容
def get_user_input():return input("请输入您的问题: ")6. 查询集合中的文档
# 6. 查询集合中的文档
def query_collection(query_embeddings, n_results=1):results = collection.query(query_embeddings=[query_embeddings], # 查询文本的嵌入n_results=n_results # 返回的结果数量)return results['documents']collection.query(...):对collection进行查询,基于嵌入向量 执行相似度检索。query_embeddings=[query_embeddings]:将单个查询嵌入封装在列表中,确保符合 API 要求。n_results=n_results:指定要返回的最相似的n_results个文档。
return results['documents']
results是collection.query(...)的返回结果,它应该是一个 字典,其中包含多个字段(如documents,embeddings , ids 等)。results['documents']获取查询返回的文档列表并返回。
7. 构建Prompt并生成答案
# 7. 构建Prompt并生成答案
def get_completion(prompt, model='gpt-3.5-turbo'):message = [{"role": "user", "content": prompt}]result = client.chat.completions.create(model=model,messages=message)return result.choices[0].message.content主流程
if __name__ == "__main__":# 步骤1 => 加载文档document = load_document(file_path)# 步骤2 => 文档分割chunks = split_document(document)# 步骤3 => embeddingadd_documents_to_collection(chunks) # 在分割后立即添加文档# 步骤4 => 用户输入内容user_input = get_user_input()# 步骤5 => 将用户输入的问题进行embeddinginput_embedding = get_embedding(user_input)[0] # 获取用户问题的嵌入# 步骤6 => 查询集合中的文档context_texts = query_collection(input_embedding, n_results=1) # 查询相关文档print(context_texts)# 步骤7 => 构建Prompt并生成答案prompt = f"上下文: {context_texts}\n\n问题: {user_input}\n\n请提供答案:"answer = get_completion(prompt)print(answer)附录
函数解释
1. open() 函数语法
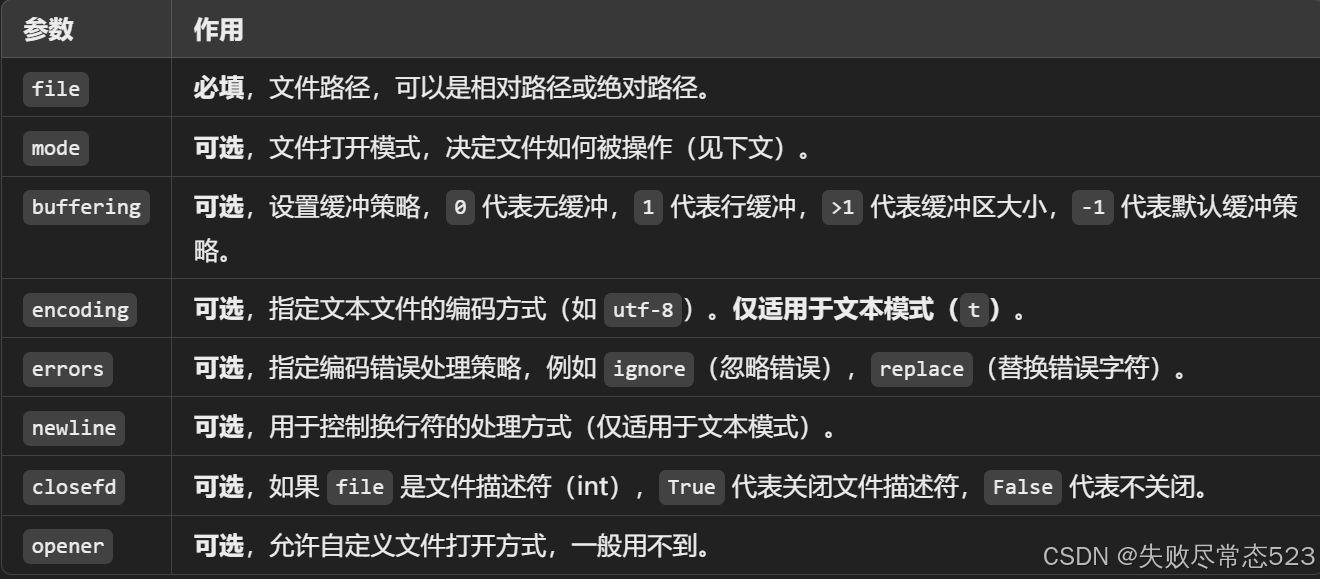
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明
常见 mode(模式)
组合模式示例:
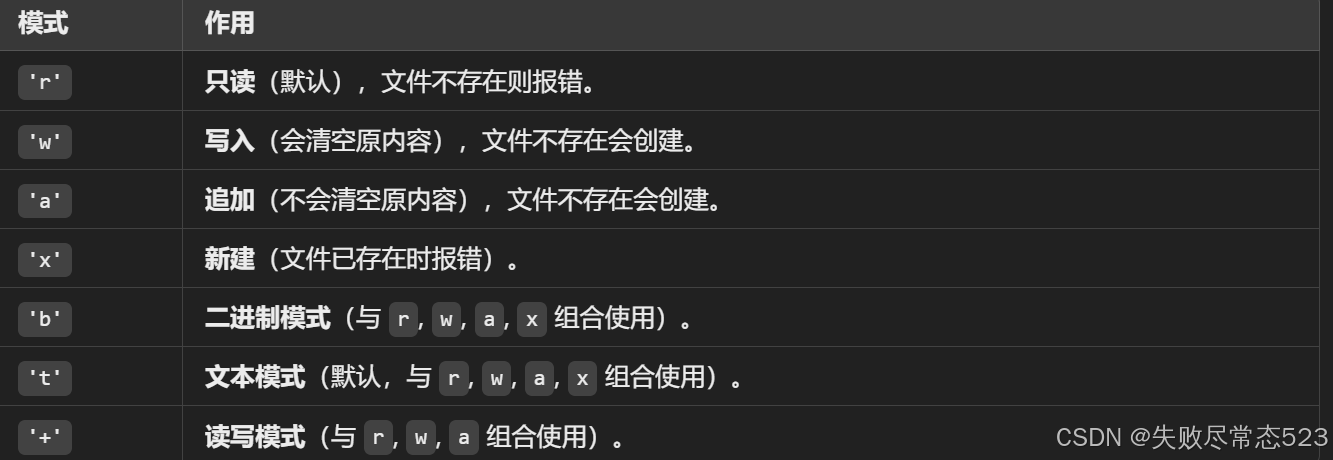
'rb':以 二进制模式 读取文件。'wt':以 文本模式 写入文件。'a+':以 读写模式 打开文件,并在文件末尾追加内容。
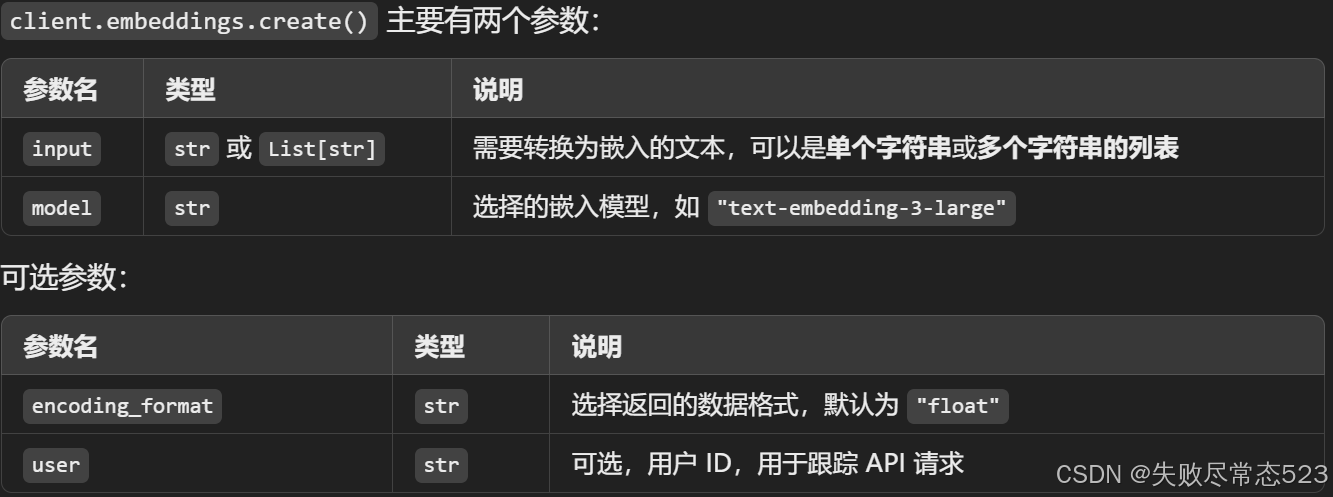
2.client.embeddings.create()
client.embeddings.create() 是 OpenAI API 提供的一个函数,用于生成文本的嵌入(embedding)向量。它将文本转换为高维数值向量,通常用于相似性计算、文本分类、搜索、推荐系统等 NLP 任务。
基本使用
import openai# 创建 OpenAI 客户端(需要提供 API Key)
client = openai.OpenAI(api_key="your-api-key")# 生成文本嵌入
response = client.embeddings.create(input=["Hello world", "How are you?"], # 输入文本,可以是单个字符串或字符串列表model="text-embedding-3-large" # 选择的嵌入模型
)
参数说明
3.collection.query()
collection.query() 是一个用于查询向量数据库的函数,主要用于 基于向量嵌入(embeddings)的相似性搜索。它通常用于检索与查询向量最接近的文档或数据点。
results = collection.query(query_embeddings=[query_vector], # 查询向量(必须是列表)n_results=3 # 需要返回的最相似的结果数量
)
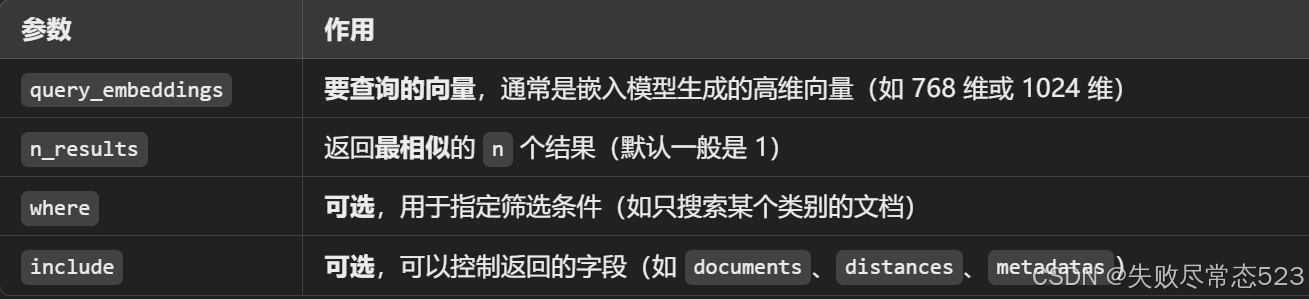
collection.query() 的返回结果
查询后的 results 变量通常是一个 字典,常见的字段包括:
{"documents": [["文档1内容"], ["文档2内容"], ["文档3内容"]],"distances": [[0.12], [0.15], [0.18]],"metadatas": [{"id": "doc1"}, {"id": "doc2"}, {"id": "doc3"}]
}

完整代码
import chromadb # 导入 chromadb 库
from openai import OpenAI # 导入 OpenAI 库
client = OpenAI() # 创建一个 OpenAI 客户端实例file_path = "./巴黎奥运会金牌信息.txt"# 创建一个 chroma 客户端实例
chroma_client = chromadb.Client()# 创建一个名为 "my_collection" 的集合
collection = chroma_client.create_collection(name="my_collection")# 1. 加载并读取文档
def load_document(filepath):with open(filepath, 'r', encoding='utf-8') as file:document = file.read()return document# 2. 文档分割
def split_document(document):# 使用两个换行符来分割段落chunks = document.strip().split('\n\n')return chunks # 返回包含所有文本块的列表# 3. embedding
def get_embedding(texts, model="text-embedding-3-large"):result = client.embeddings.create(input=texts,model=model)return [x.embedding for x in result.data]# 4. 向集合中添加文档
def add_documents_to_collection(chunks):embeddings = get_embedding(chunks) # 获取文档块的嵌入collection.add(documents=chunks, # 文档内容embeddings=embeddings, # 文档对应的嵌入向量ids=[f"id{i+1}" for i in range(len(chunks))] # 生成文档 ID)# 5. 用户输入内容
def get_user_input():return input("请输入您的问题: ")# 6. 查询集合中的文档
def query_collection(query_embeddings, n_results=1):results = collection.query(query_embeddings=[query_embeddings], # 查询文本的嵌入n_results=n_results # 返回的结果数量)return results['documents']# 7. 构建Prompt并生成答案
def get_completion(prompt, model='gpt-3.5-turbo'):message = [{"role": "user", "content": prompt}]result = client.chat.completions.create(model=model,messages=message)return result.choices[0].message.content# 主流程
if __name__ == "__main__":# 步骤1 => 加载文档document = load_document(file_path)# 步骤2 => 文档分割chunks = split_document(document)# 步骤3 => embeddingadd_documents_to_collection(chunks) # 在分割后立即添加文档# 步骤4 => 用户输入内容user_input = get_user_input()# 步骤5 => 将用户输入的问题进行embeddinginput_embedding = get_embedding(user_input)[0] # 获取用户问题的嵌入# 步骤6 => 查询集合中的文档context_texts = query_collection(input_embedding, n_results=1) # 查询相关文档print(context_texts)# 步骤7 => 构建Prompt并生成答案prompt = f"上下文: {context_texts}\n\n问题: {user_input}\n\n请提供答案:"answer = get_completion(prompt)print(answer)