西安营销型网站建设动力无限怎么找到当地的微信推广
消费者
消费者与消费组
消费者Consumer负责定于kafka中的主题Topic,并且从订阅的主题上拉取消息。与其他消息中间件不同的在于它有一个消费组。每个消费者对应一个消费组,当消息发布到主题后,只会被投递给订阅它的消费组的一个消费者。
- 如果有某个主题有4个分区,P0,P1,P2,P3.有两个消费组A和B订阅了这个主题,A消费组有4个消费者,B消费组有2个消费者,那么A消费组中的4个消费者每一个都只会分配到一个分区,而B消费组中的2个消费者会分配到两个分区。
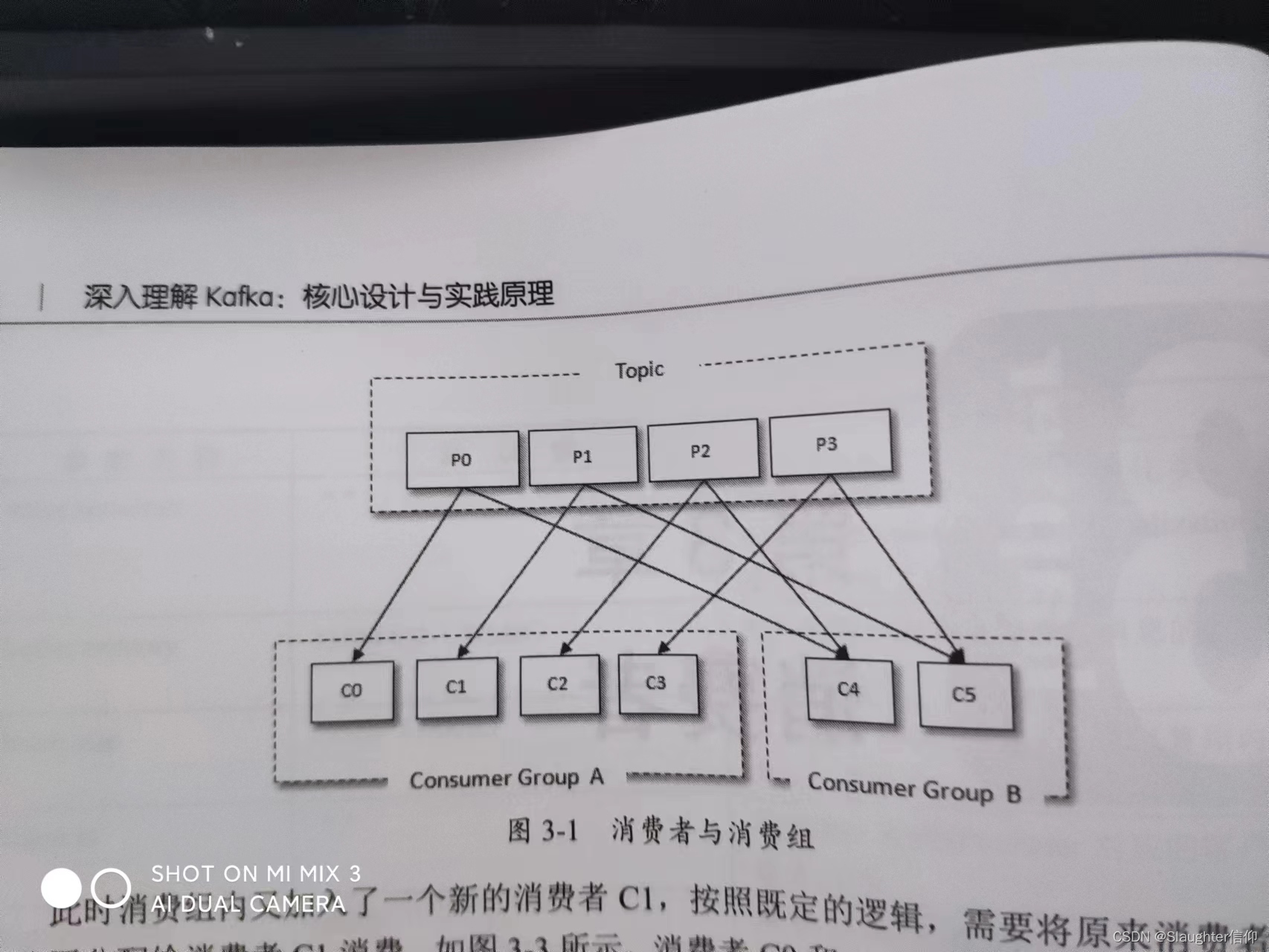
- 如果所有消费者都属于一个消费者,那么所有的消息默认会均匀分配给每一个消费者。
- 如果所有的消费者都隶属于不同的消费组,那么所有的消息都会被广播给所有的消费者。
PS:再均衡动作:解释一下名词,指的是当一个主题中有6个分区时,有一个消费组,这个消费组中只有一个消费者,那么主题中的6个分区的消息都会由同一个消费者来消费,当有一个新的消费者加入这个消费组之后,6个主题中会有3个分配个新的消费者,依次类推,这个动作被称为再均衡动作
必要参数说明
kafka消费者客户端有个4个必填参数
- bootstrapp.service:该参数的释义和生产者客户端的相同,用来指定链接kafka集群所需要的broker地址清单。
- group.id:消费者隶属的消费组名称,默认为""
- key.deserializer和value.deserializer与生产者相同。
其他重要参数 - fetch.min.bytes:配置消费者在一次的poll中拉取的最小数据量 默认 1b
- fetch.max.bytes:配置消费者在一次的poll中拉取的最大数据量默认50MB.
- fetch.max.wait.ms :参数用于指定 Kafka 的等待时间,默认值为 500 )
- exclude.internal.topics:Kafka 中有两个内部的主题:一consumer_offsets tr ansaction state o exclude.internal.topics用来指定 Kafka 中的内部主题是否可以向消费者公开,默认值为 true 。如果设置 true ,那么只能使用 subscribe( Collection)的方式而不能使用subscribe(Pattern)的方式来订阅内部主题,设置为false 则没有这个限制。
- receive.buffer.bytes:这个参数用来设置 Socket 接收消息缓冲区的大小,默认值为 65536 (B) 如果设置为 -1,则使用操作系统的默认值。
- send.buffer.bytes:,这个参数用来设置 Socket 发送消息缓冲区的大小默认值为 13 1072 (B) ’
- request.timeout.ms: 这个参数用来配置 Consumer 等待请求响应的最长时间,默认值为 30000 ms )。
- metadata.max.age.ms: 这个参数用来配置元数据的过期时间,默认值为 300000 ms ),即5分钟。如果元数据在此参数所限定的时间范围内没有进行更新,则会被强制更新,即使没有任何分区变化或有新的broker 加入。
- reconnect.backoff.ms 这个参数用来配置尝试重新连接指定主机之前的等待时间(也称为退避时间〉,避免频繁地连接主机,默认值为 50 ms )。
订阅主题与分区
订阅主题通过subscribe()方法来订阅一个主题,可以是集合订阅多个主题,也可以是正则。
public void subscribe(Collection<String> topics,ConsumerRebalanceListenergy listener);
public void subscribe(Collection<String> topics);
public void subscribe(Pattern pattern ,ConsumerRebalanceListenergy listener);
public void subscribe(Pattern pattern);
-
如果前后调用两次 subscribe方法 那么以后一次的为准。
PS:ConsumerRebalanceListenergy listener 是用来设置相应的再均衡监听器 -
这里还可以通过assign()方法来指定主题中特定的分区来定义。
public void assign(Collection<TopicPartition> partition);
- 其中 partition是分区的集合。
- TopicPartition类有两种属性 topic和partition,分别代表分区所属的主题和自己的分区偏移量也就是编号。
- 通过partitionsFor(String topic)方法可以查询主题有多少个分区
取消订阅
- unsubscribe()方法取消订阅主题
- subscribe(new ArrayList<>());
- assign(new ArrayList<>());
以上都可
反序列化
对应生产者的序列化器相反,用来把序列化的内容反序列化,至于序列化与反序列化请自行百度,基础概念不与重复。
消息消费
Kafka中消费方式采取的拉去式消费:消息的消费一般分为两种:拉取式和推送式。
- kefka中的消息消费是一个不断轮询的过程。需要重复的效用poll方法。
public ConsumerRecords<K,V> poll(final Duration timeout);
- 其中timeOut 是用来限制poll方法的阻塞时间的
其中 Duration 也有Long的方法,Long的timeOut是毫秒值,Duration 可以通过ofMillis、ofSeconds、ofMinutes
、ofHours等方法来指定不同时间类型。
ConsumerRecords类中还会提供一个方便开发人员用来对消息进行处理的:count()等 如有兴趣自定查看。
位移提交
offset偏移量也叫位移,消费者可以通过offset来指定消费分区中的某个消息所在的位置。
- 每次调用poll方法返回的是未被消费的消息集,偏移量不仅要保存在内存中也要做持久化保存,否则消费者重启之后就无法知晓之前的消费位移,如果有新的消费者加入,那么必然会有再均衡动作,那么新加入的消费者也无法知晓之前的消费位移
- 在旧消费者客户端中消费者偏移量存储在zk中,新版本存放在kafka的主题_consumer_offsets中,这个把偏移量存储起来的动作就时提交。
控制或关闭消费
KafkaConsumer提供了对消费速度进行控制的方法。使用pause()方法resume()方法来分别实现暂停某些分区在拉取操作时返回数据给客户端和恢复某些分区想客户端返回数据的操作。
指定位置消费
对应消费位移,主要用在消费者重启之后出发了再均衡动作之后指定偏移量消费分区内消息。
消费者拦截器
对应生产者消费器,主要在消费到消息或提交消费位移的时候进行一些定制化操作。