梅州兴宁网站建设优化网站内容
目录
- 切片 for 循环删除切片元素
- 其他循环中删除slice元素的方法
- 方法1
- 方法2(推荐)
- 方法3
- 官方提供的方法
- 结论
- 切片 for 循环删除map元素
- goalng map delete操作不会释放底层内存
- go map原理
- 源码
- CRUD
- 查询
- 新增
- 操作注意事项
- map元素是无法取址的
- map是线程不安全的
切片 for 循环删除切片元素
在 Go 语言中,使用 for 循环删除切片元素可能会引发意外的结果,因为切片的长度在循环过程中可能会发生变化,导致索引越界或不正确的元素被删除。这是因为在删除切片元素时,删除操作会影响切片的长度和索引,从而影响后续的迭代。
以下是一个示例,演示了在循环中删除切片元素可能引发的问题:
package mainimport ("fmt"
)func main() {// 8*5 =40slice := []int{1, 2, 2, 2, 2, 4, 5}fmt.Printf("切片长度:%d,容量:%d \n", len(slice), cap(slice))for index, value := range slice {if value == 2 {slice = append(slice[:index], slice[index+1:]...)fmt.Println("删除了一次2")}fmt.Println(index, value)}fmt.Println(slice)fmt.Printf("切片长度:%d,容量:%d \n", len(slice), cap(slice))slice = slice[:cap(slice)]fmt.Println(slice)
}
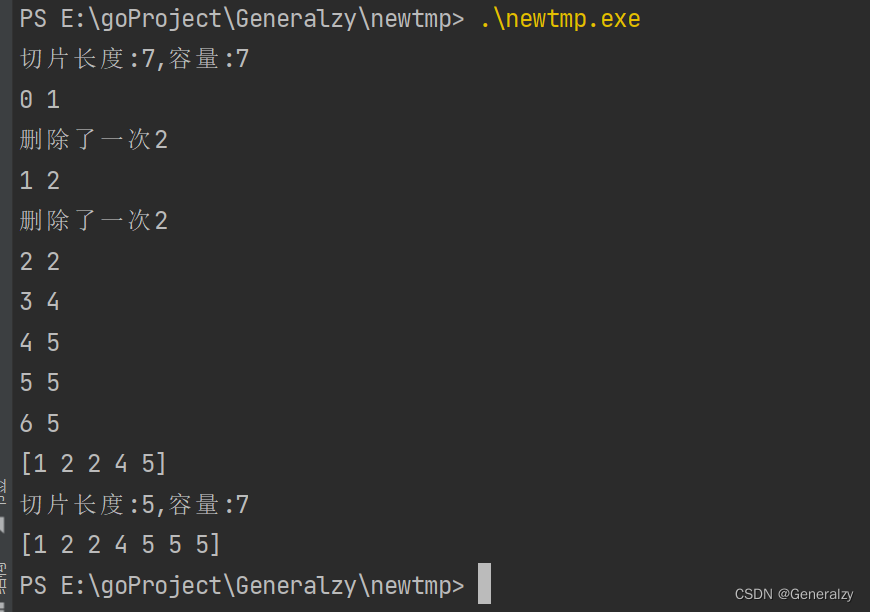
在这个示例中,删除切片 slice 中值为 2 的元素。然而,由于删除操作改变了切片的长度和索引,循环会出现问题。
接下来通过画图来解释这个现象:
-
这是开始的slice:
slice := []int{1, 2, 2, 2, 2, 4, 5} fmt.Printf("切片长度:%d,容量:%d \n", len(slice), cap(slice))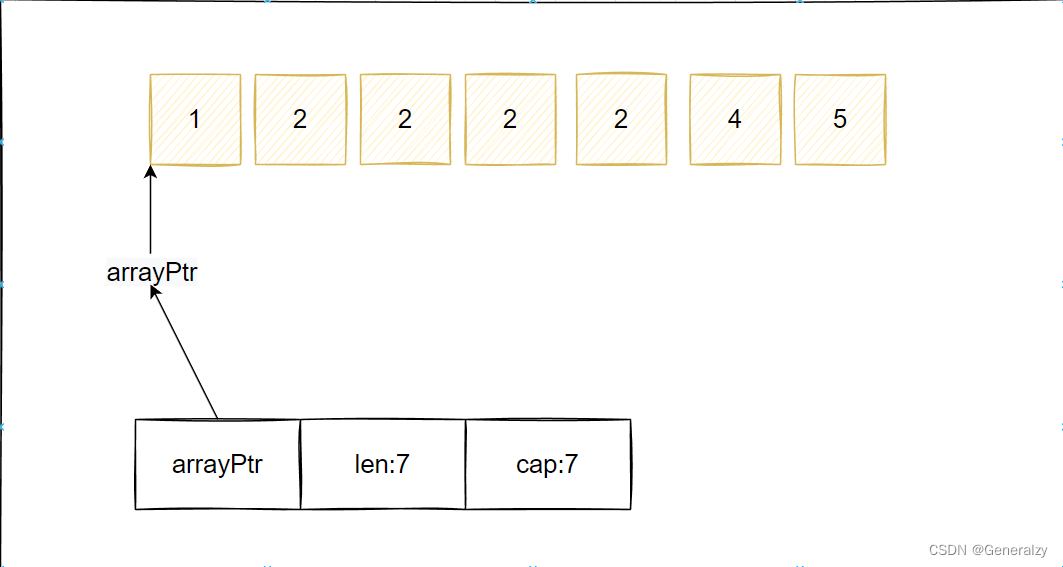
-
进入循环删除元素:
for index, value := range slice {if value == 2 {slice = append(slice[:index], slice[index+1:]...)}fmt.Println(index, value) }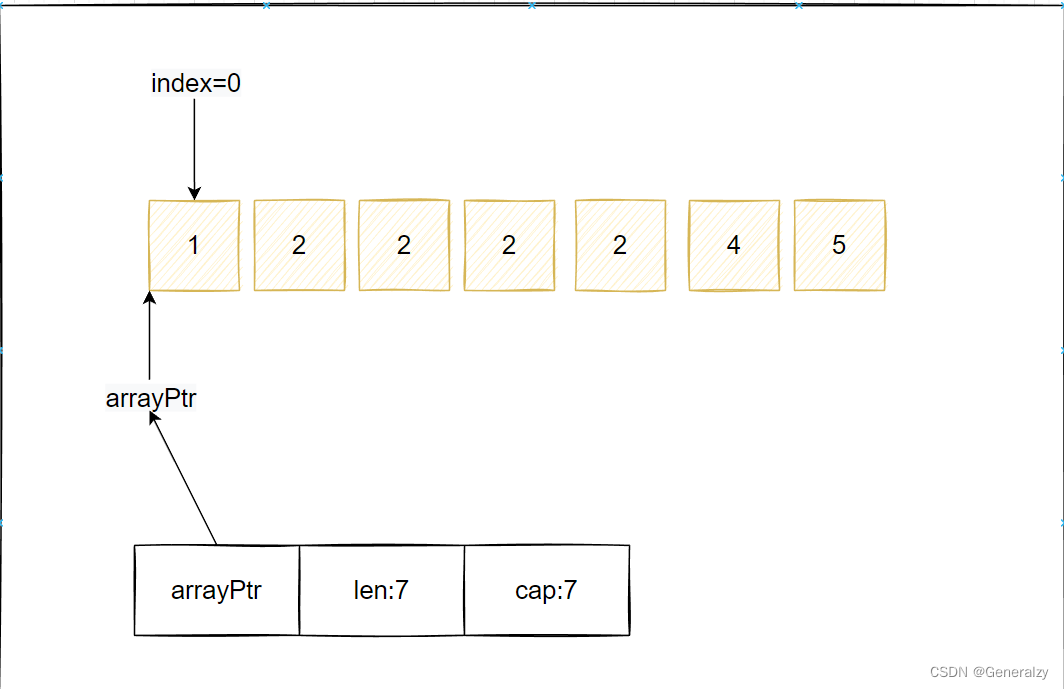
当index = 1时,删除第一次2后: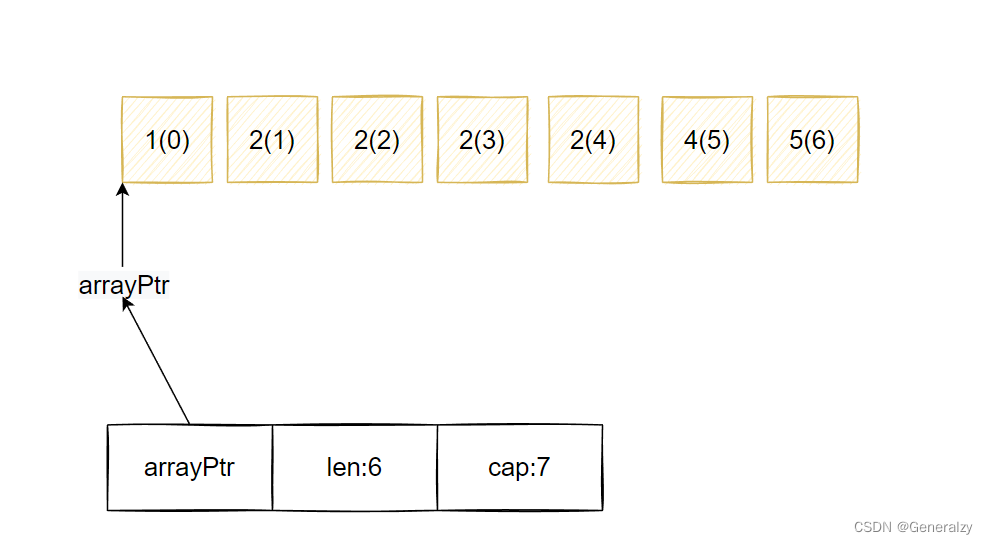
当index = 2时,删除第二次2后: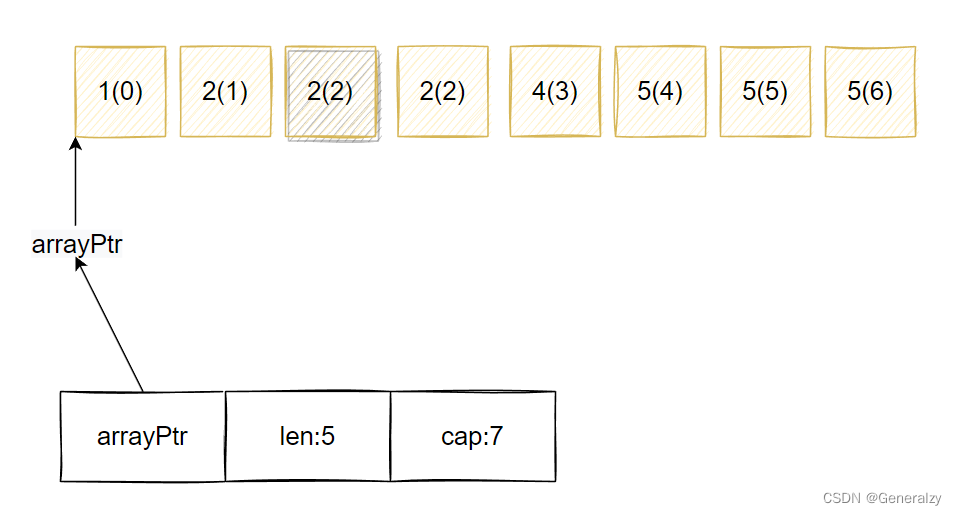
在 Go 的 for index, val := range slice 循环中,index 和 val 在每次循环迭代中都会被重新赋值,以便遍历切片中的每个元素。这意味着在每次循环迭代中,index 和 val 都会随着切片中的元素不断变化。
例如,考虑以下代码片段:
slice := []int{1, 2, 3, 4, 5}
for index, val := range slice {fmt.Printf("Index: %d, Value: %d\n", index, val)
}
在这个循环中,index 会取遍历到的元素的索引值,val 会取遍历到的元素的值。每次循环迭代,index 和 val 都会随着切片中的元素变化,从 0 到切片长度减 1。
虽然 index 和 val 会在循环中变化,但在循环内部对它们的重新赋值不会影响切片本身。即使在循环内部修改了 index 或 val 的值,也不会影响切片中的元素。这是因为 index 和 val 是在每次迭代中以新的值被复制,不会直接影响原切片中的数据。
用文字描述就是:
// index = 0,val = 1 不删除 slice = [1,2,2,2,2,4,5],打印(index,val)=(0,1)
// index = 1,val = 2 删除 slice = [1,2(1),2(2),2,4,5],打印(index,val)=(1,2)
// index = 2,val = 2 删除 slice = [1,2(1),2,4,5],打印(index,val)=(2,2)
// index = 3,val = 4 不删除
// index = 4,val = 5 不删除
// index = 5,val = 5 不删除
// index = 6,val = 5 不删除
index和val在循环开始时就已经确定了,所以打印时不受影响;但由于slice变化了,所以下一次循环开始时,index和val顺次增加从内存中取出的值却不是以前的值了,所以打印受到了影响。
正确的做法是,可以首先记录需要删除的元素的索引,然后再循环外面执行删除操作,避免在循环中修改切片。例如:
package mainimport "fmt"func main() {slice := []int{1, 2, 3, 4, 5}indexesToDelete := []int{}for index, value := range slice {if value == 3 {indexesToDelete = append(indexesToDelete, index)}}// 从后往前删除前面的不会受到影响for i := len(indexesToDelete) - 1; i >= 0; i-- {index := indexesToDelete[i]slice = append(slice[:index], slice[index+1:]...)}fmt.Println(slice)
}
在这个示例中,我们首先记录了需要删除的元素的索引,然后在第二个循环中进行了删除操作。这样可以避免在循环中修改切片,从而避免了索引越界和其他问题。
其他循环中删除slice元素的方法
a := []int{1, 2, 3, 4, 5},slice 删除大于 3 的数字
方法1
package mainimport "fmt"func main() {a := []int{1, 2, 3, 4, 5}for i := 0; i < len(a); i++ {if a[i] > 3 {// 当前元素被删除后,整体元素前移1位// 如果此时index++,相当于指针向后移动了两位,会导致跳过1位数组的读取// 因此,把i的自增行为抵消掉,指针不动,数组前移,i指向的地方自动会有下一个值填充进来a = append(a[:i], a[i+1:]...)i--}}fmt.Println(a)
}
方法2(推荐)
package mainimport "fmt"func main() {a := []int{1, 2, 3, 4, 5}j := 0for _, v := range a {if v <= 3 {a[j] = v// 符合条件的顺次赋值给前面的数组j++}}// 通过一次切片操作,将len置为j// 相当于只有len<=j的数组才可以看到a = a[:j]fmt.Println(a)
}
方法3
package mainimport "fmt"func main() {a := []int{1, 2, 3, 4, 5}j := 0// 相当于将a拷贝到qq := make([]int, len(a))for _, v := range a {if v <= 3 {q[j] = vj++}}q = q[:j] // q is copy with numbers >= 0fmt.Println(q)
}
官方提供的方法
go1.21版本后提供了slice库,封装了常用的slice方法:
func DeleteFunc[S ~[]E, E any](s S, del func(E) bool) S {// Don't start copying elements until we find one to delete.for i, v := range s {if del(v) {j := ifor i++; i < len(s); i++ {v = s[i]if !del(v) {s[j] = vj++}}return s[:j]}}return s
}
将del(v)改为v <= 3
func DeleteFunc[S ~[]int](s S) S {// Don't start copying elements until we find one to delete.for i, v := range s {if v <= 3 {j := ifor i++; i < len(s); i++ {v = s[i]if !(v <= 3) {s[j] = vj++}}return s[:j]}}return s
}
官方的操作和方法2非常相似,
func main() {a := []int{1, 2, 3, 4, 5}a = DeleteFunc(a)fmt.Println(a)a = a[:cap(a)]fmt.Println(a)
}
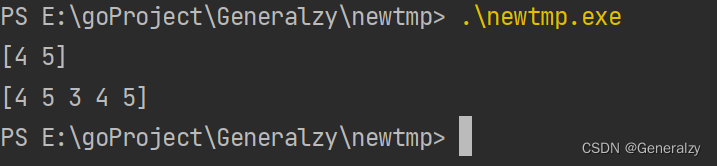
由于切片的扩缩容机制,基本上必须要把切片返回,防止切片底层指向的地址变动导致外部感受不到。
结论
- 当使用 for range 循环(for range) 遍历切片时,key 返回的是切片的索引,value 返回的是索引对应的值的拷贝。
- 在 Go 语言中,使用 for 循环删除切片元素可能会引发意外的结果,因为切片的长度在循环过程中可能会发生变化,导致索引越界或不正确的元素被删除。这是因为在删除切片元素时,删除操作会影响切片的长度和索引,从而影响后续的迭代。
切片 for 循环删除map元素
前提知识:map为什么会有这种无序性呢?map在某些条件下会自动扩容和重新hash所有的key以便存储更多的数据。 因为散列值映射到数组索引上本身就是随机的,在重新hash前后,key的顺序自然就会改变了。所以Go的设计者们就对map增加了一种随机性,以确保开发者在使用map时不依赖于有序的这个特性。
一句话:for循环中删除map元素是安全的。
官方go1.21 maps包中的删除方法:
// DeleteFunc deletes any key/value pairs from m for which del returns true.
func DeleteFunc[M ~map[K]V, K comparable, V any](m M, del func(K, V) bool) {for k, v := range m {if del(k, v) {delete(m, k)}}
}
奇怪的是,删除元素是安全的,新增元素却是不可预知的:
func main() {m := map[int]bool{0: true,1: false,2: true,}for k, v := range m {if v {m[10+k] = true}}fmt.Println(m)
}
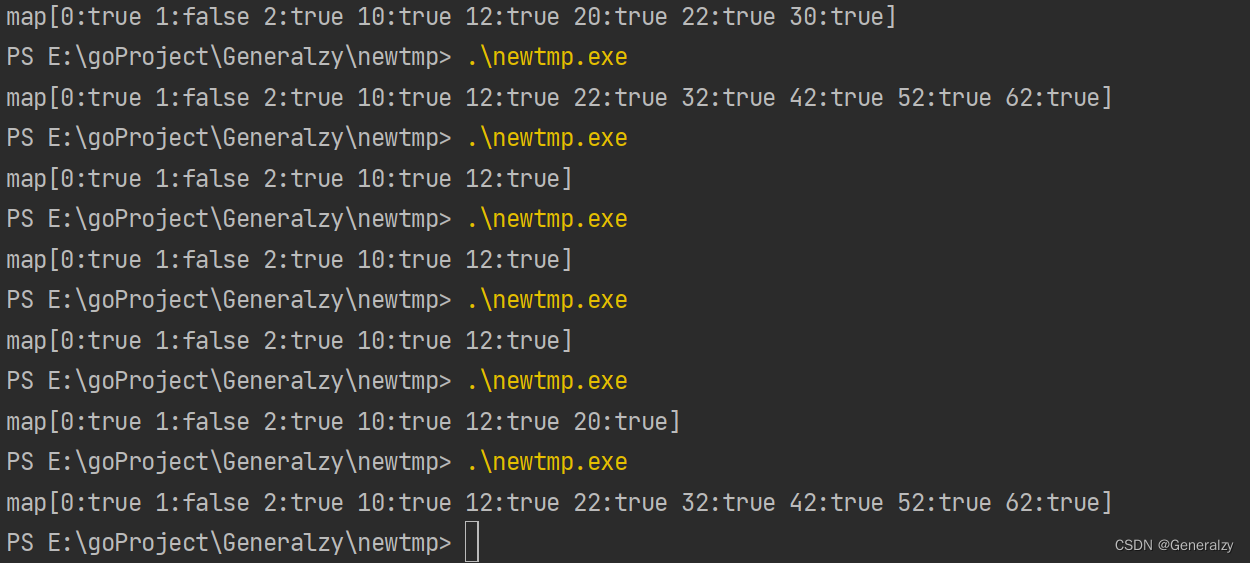
上面这段代码的输出结果是不确定的。为什么呢?Go的官方文档中有这样的一段话:
If a map entry is created during iteration, it may be produced during the iteration or skipped. The choice may vary for each entry created and from one iteration to the next. – Go spec
大致的意思就是:
在遍历map期间,如果有一个新的key被创建,那么,在循环遍历过程中可能会被输出,也可能会被跳过。对于每一个创建的key在迭代过程中是选择输出还是跳过都是不同的。
也就是说,在迭代期间创建的key,有的可能会被输出,也的就可能会被跳过。这就是由于map中key的无序性造成的。
怎么解决上述问题,让输出结果变的是稳定的呢?最简单的方案就是使用复制:
m := map[int]bool{0: true,1: false,2: true,
}
m2 := make(map[int]bool)
for k, v := range m {m2[k] = vif v {m2[10+k] = true}
}
fmt.Println(m2)
由此可知,通过一个新的map,将读和写分离。即从m中读,在m2中更新,这样就能保持稳定的输出结果:
map[0:true 1:false 2:true 10:true 12:true]
goalng map delete操作不会释放底层内存
package mainimport ("fmt""runtime"
)//var a = make(map[int]struct{})func main() {v := struct{}{}a := make(map[int]struct{})for i := 0; i < 10000; i++ {a[i] = v}runtime.GC()printMemStats("添加1万个键值对后")fmt.Println("删除前Map长度:", len(a))for i := 0; i < 10000-1; i++ {delete(a, i)}fmt.Println("删除后Map长度:", len(a))// 再次进行手动GC回收runtime.GC()printMemStats("删除1万个键值对后")// 设置为nil进行回收a = nilruntime.GC()printMemStats("设置为nil后")
}func printMemStats(mag string) {var m runtime.MemStatsruntime.ReadMemStats(&m)fmt.Printf("%v:分配的内存 = %vKB, GC的次数 = %v\n", mag, m.Alloc/1024, m.NumGC)
}
可以看到,新版本的 Golang 难道真的会回收 map 的多余空间,难道哈希表会随着 map 里面的元素变少,然后缩小了?

将 map 放在外层:
package mainimport ("fmt""runtime"
)var a = make(map[int]struct{})func main() {v := struct{}{}//a := make(map[int]struct{})for i := 0; i < 10000; i++ {a[i] = v}runtime.GC()printMemStats("添加1万个键值对后")fmt.Println("删除前Map长度:", len(a))for i := 0; i < 10000-1; i++ {delete(a, i)}fmt.Println("删除后Map长度:", len(a))// 再次进行手动GC回收runtime.GC()printMemStats("删除1万个键值对后")// 设置为nil进行回收a = nilruntime.GC()printMemStats("设置为nil后")
}func printMemStats(mag string) {var m runtime.MemStatsruntime.ReadMemStats(&m)fmt.Printf("%v:分配的内存 = %vKB, GC的次数 = %v\n", mag, m.Alloc/1024, m.NumGC)
}
这时 map 好像内存没变化,直到设置为 nil。
为什么全局变量就会不变呢?
将局部变量添加一万个数,然后再删除9999个数,再添加9999个,看其变化:
package mainimport ("fmt""runtime"
)//var a = make(map[int]struct{})func main() {v := struct{}{}a := make(map[int]struct{})for i := 0; i < 10000; i++ {a[i] = v}runtime.GC()printMemStats("添加1万个键值对后")fmt.Println("删除前Map长度:", len(a))for i := 0; i < 10000-1; i++ {delete(a, i)}fmt.Println("删除后Map长度:", len(a))// 再次进行手动GC回收runtime.GC()printMemStats("删除1万个键值对后")for i := 0; i < 10000-1; i++ {a[i] = v}// 再次进行手动GC回收runtime.GC()printMemStats("再一次添加1万个键值对后")// 设置为nil进行回收a = nilruntime.GC()printMemStats("设置为nil后")
}func printMemStats(mag string) {var m runtime.MemStatsruntime.ReadMemStats(&m)fmt.Printf("%v:分配的内存 = %vKB, GC的次数 = %v\n", mag, m.Alloc/1024, m.NumGC)
}
这次局部变量删除后,和全局变量map一样了,内存也没变化。
但是添加10000个数后内存反而变小了。
map删除元素后map内存是不会释放的,无论是局部还是全局,但引出了上面一个奇怪的问题。
https://github.com/golang/go/issues/20135
为什么添加10000个数后内存反而变小了?因为 Golang 编译器有提前优化功能,它知道后面 map a 已经不会被使用了,所以会垃圾回收掉,a = nil 不起作用。
go map原理
源码
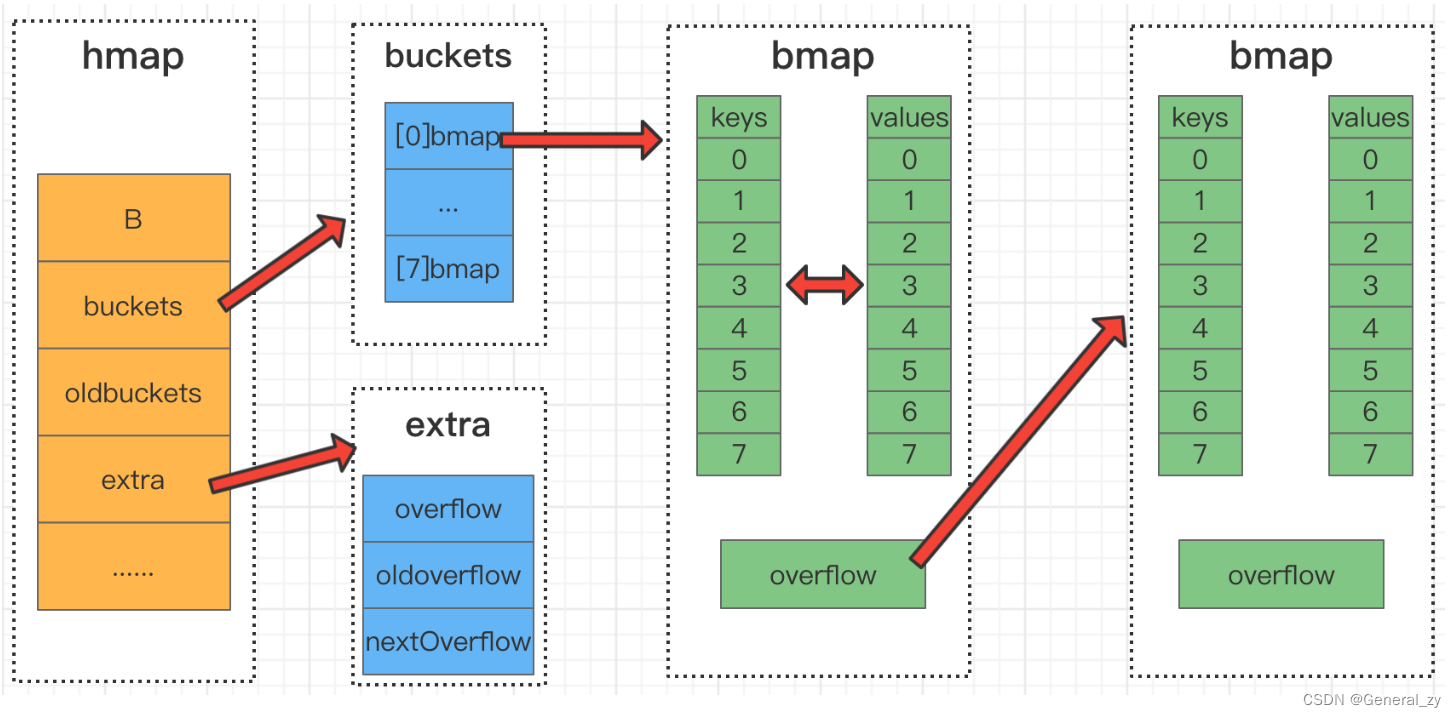
// A header for a Go map.
type hmap struct {count int // map元素的个数,len()的返回值flags uint8 // 状态标识,比如正在被写、buckets和oldbuckets在被遍历、等量扩容(Map扩容相关字段)B uint8 // B的值==log_2(buckets的长度)noverflow uint16 // 溢出桶里bmap大致的数量hash0 uint32 // hash因子buckets unsafe.Pointer // 2^B个桶对应的指针数组的指针oldbuckets unsafe.Pointer // 旧指针,用于扩缩容nevacuate uintptr // 记录渐进式扩容阶段下一个要迁移的旧桶编号 extra *mapextra // 可选字段
}// bucket结构体定义type bmap struct {tophash [8]uint8 //存储哈希值的高8位keys // key数组elems // 值数组overflow *bmap //溢出bucket的地址}type mapextra struct {overflow *[]*bmapoldoverflow *[]*bmap// nextOverflow 持有一个指向空闲溢出桶的指针。nextOverflow *bmap
}

- tophash用来快速查找key值是否在该bucket中,而不同每次都通过真值进行比较;
- 根据注释(us to eliminate padding which would be needed for, e.g., map[int64]int8.),map[int64]int8,key是int64(8个字节),value是int8(一个字节),kv的长度不同,如果按照kv格式存放,则考虑内存对齐v也会占用int64,而按照后者存储时,8个v刚好占用一个int64。
CRUD
将B初始化为4,则buckets为16
查询
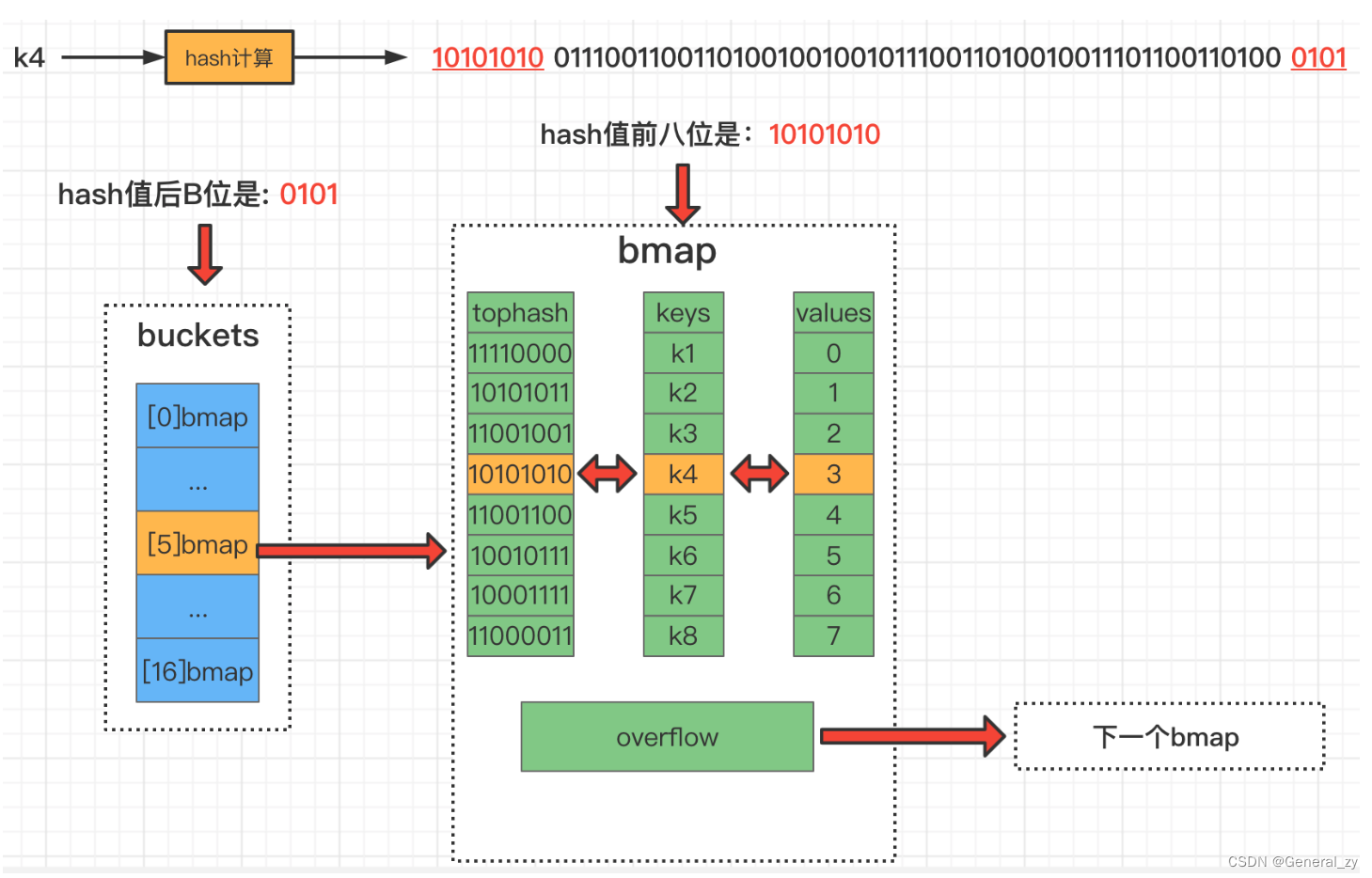
-
计算key的hash值。
-
通过最后的“B”位来确定在哪号桶,此时B为4,所以取k4对应哈希值的后4位,也就是0101
-
根据key对应的hash值前8位快速确定是在这个桶的哪个位置
-
对比key完整的hash是否匹配,如果匹配则获取对应value
-
如果都没有找到,就去连接的下一个溢出桶中找
新增
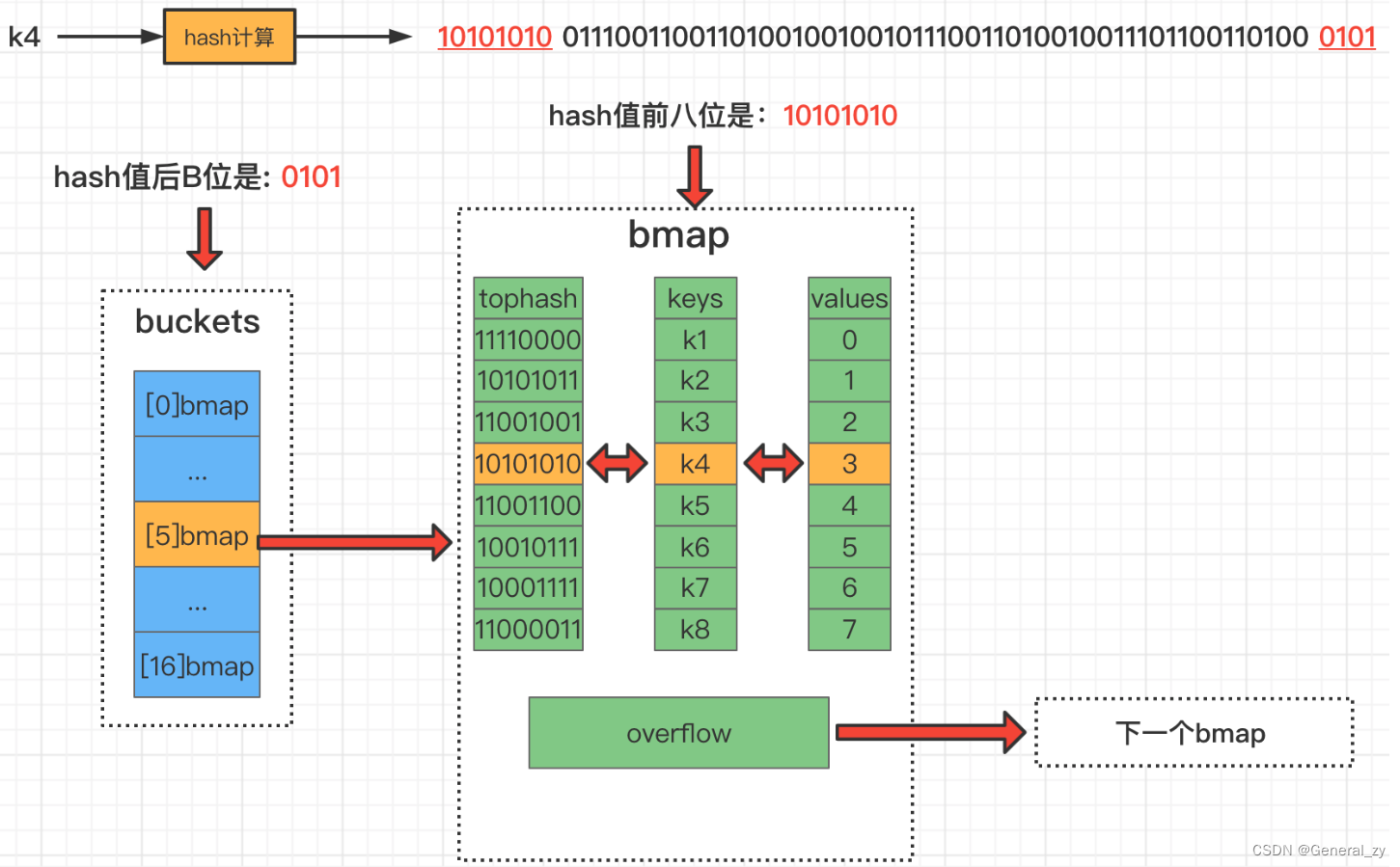
- 通过key获取hash值
- hash值的低八位和bucket数组长度取余,定位到在数组中的哪个个下标
- hash值的高八位存储在bucket中的tophash中,用来快速判断key是否存在,key和value的具体值则通过指针运算存储,当一个bucket满时,通过overfolw指针链接到下一个bucket。
操作注意事项
map元素是无法取址的
- 可以得到m[key],但是无法对它的值作出任何修改,除非使用带指针的value。
- 因为map 会随着元素数量的增长而重新分配更大的内存空间,会导致之前的地址无效。
map是线程不安全的
某map桶数量为4,即B=2,此时 goroutine1来插入key1, goroutine2来读取 key2. 可能会发生如下过程:
-
goroutine2 计算key2的hash值,B=2,并确定桶号为1。
-
goroutine1添加key1,触发扩容条件。
-
B=B+1=3, buckets数据迁移到oldbuckets。
-
goroutine2从桶1中遍历,获取数据失败。