从零开始学做网站 网站国际机票搜索量大涨
在 Elasticsearch 中,mapping 定义了索引中的字段类型及其处理方式。
近期有球友提问,为什么设置了 index: false 的字段仍能被检索。
本文将详细探讨这个问题,并引入列式存储的概念,帮助大家更好地理解 Elasticsearch 的存储和查询机制。

1、问题描述
我们创建了一个名为 my-index-000001 的索引,并为其添加了一个名为 employee-id 的字段,该字段的 index 属性被设置为 false。
按理说,这个字段不应该被索引,也不应能被检索,但在执行查询时,却能检索到该字段。这是为什么呢?
PUT /my-index-000001
{"mappings": {"properties": {"employee-id": {"type": "keyword","index": false}}}
}POST /my-index-000001/_doc/1
{"employee-id": "1111"
}POST /my-index-000001/_search
{"query": {"term": {"employee-id": "1111"}}
}问题来源:https://t.zsxq.com/GuwKP
2、原因分析
在 Elasticsearch 中,index 选项控制字段值是否被索引。
默认情况下,所有字段都是被索引的 (index: true)。当 index 设置为 false 时,字段不会被索引,因此不能通过常规查询方法高效地检索该字段。
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-index.html
然而,对于某些特定类型的字段,即使设置了 index: false,它们仍然可以通过 doc_values 进行查询。
这其实就是咱们的问题所在!
这些特定字段类型包括:
数值类型(Numeric types)
日期类型(Date types)
布尔类型(Boolean type)
IP 类型(IP type)
地理点类型(Geo_point type)
关键字类型(Keyword type)
对于这些类型的字段,即使 index 设置为 false,只要 doc_values 启用,它们仍然可以被查询。
查询效率会较低,因为需要对整个索引进行全扫描(full scan)。
3、列式存储概述
列式存储(Columnar Storage)是指将每个字段的数据独立存储,这种存储方式不同于传统的行式存储。
在数据仓库和大数据处理系统中,列式存储优化了读取和分析操作。
以下是一些常见的列式存储格式及其应用:
Parquet:广泛用于 Apache Hadoop 生态系统中的数据处理,提供高效的存储和压缩。
ORC(Optimized Row Columnar):主要用于 Apache Hive 和 Hadoop 生态系统,提供优化的列存储格式。
Cassandra:分布式数据库系统,采用行和列的混合存储方式,支持列级别的高效查询。

列式存储 VS 行式存储
在 Elasticsearch 中,doc_values 是一种列式存储机制,用于存储字段的数据,以支持高效的排序和聚合操作。
这里就是明显区别于“倒排索引”的一种正排索引技术,详细解读参见《一本书讲透 Elasticsearch》P97-P98。
Doc values 是指在文档索引时创建的存储在磁盘数据结构,它们以列式存储的方式保存与 _source 相同的数据,从而大大提高了排序和聚合操作的效率。除文本 text 和带注释的文本(annotated_text ,新类型)字段外,几乎所有字段类型都支持 doc values。
https://www.elastic.co/guide/en/elasticsearch/reference/current/doc-values.html
3.1 列式存储示例:词组数据举例
假设我们有以下文档集合,这些文档包含多个字段,包括 employee-id 雇员 id 序号和 address 地址信息:
[{"employee-id": "1111", "name": "Alice", "age": 30, "address": "123 Main St, Springfield, IL"},{"employee-id": "1112", "name": "Bob", "age": 25, "address": "456 Elm St, Springfield, IL"},{"employee-id": "1113", "name": "Charlie", "age": 35, "address": "789 Oak St, Springfield, IL"}
]列式存储如下图所示:
当这些文档被索引到 Elasticsearch 中时,启用了 doc_values 的字段会以列式存储的方式独立存储。
假设我们为 employee-id、address 字段启用了 doc_values,其存储结构如下:
employee-id 列存储:
"1111"
"1112"
"1113"address 列存储:
"123 Main St, Springfield, IL"
"456 Elm St, Springfield, IL"
"789 Oak St, Springfield, IL"3.2 列式存储查询行为
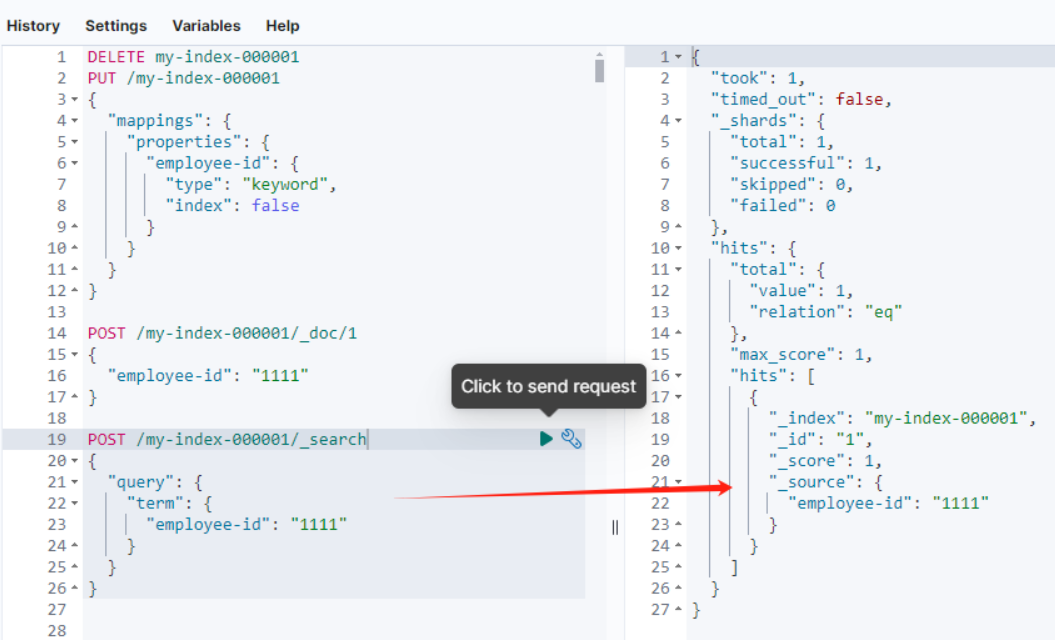
回到开篇问题,在这种情况下,如果我们对 employee-id 进行查询:
POST /my-index/_search
{"profile": true, "query": {"term": {"employee-id": "1111"}}
}由于 employee-id 字段启用了 doc_values,但没有被索引,Elasticsearch 会使用基于 doc_values 的查询机制来处理。
这个查询会遍历 employee-id 列的数据,找到匹配 "1111" 的文档。
这里就分析出了 index:false, 依然可以被检索的原因。
再进一步验证,
PUT /my-index-0606
{"mappings": {"properties": {"employee-id": {"type": "keyword","doc_values": true},"name": {"type": "text"},"age": {"type": "integer","doc_values": true},"address": {"type": "keyword","index":false}}}
}POST /my-index-0606/_bulk
{ "index": { "_id": "1" } }
{ "employee-id": "1111", "name": "Alice", "age": 30, "address": "123 Main St, Springfield, IL" }
{ "index": { "_id": "2" } }
{ "employee-id": "1112", "name": "Bob", "age": 25, "address": "456 Elm St, Springfield, IL" }
{ "index": { "_id": "3" } }
{ "employee-id": "1113", "name": "Charlie", "age": 35, "address": "789 Oak St, Springfield, IL" }POST my-index-0606/_search
{"query": {"term": {"address": "123 Main St, Springfield, IL"}}
}得到结果如下:
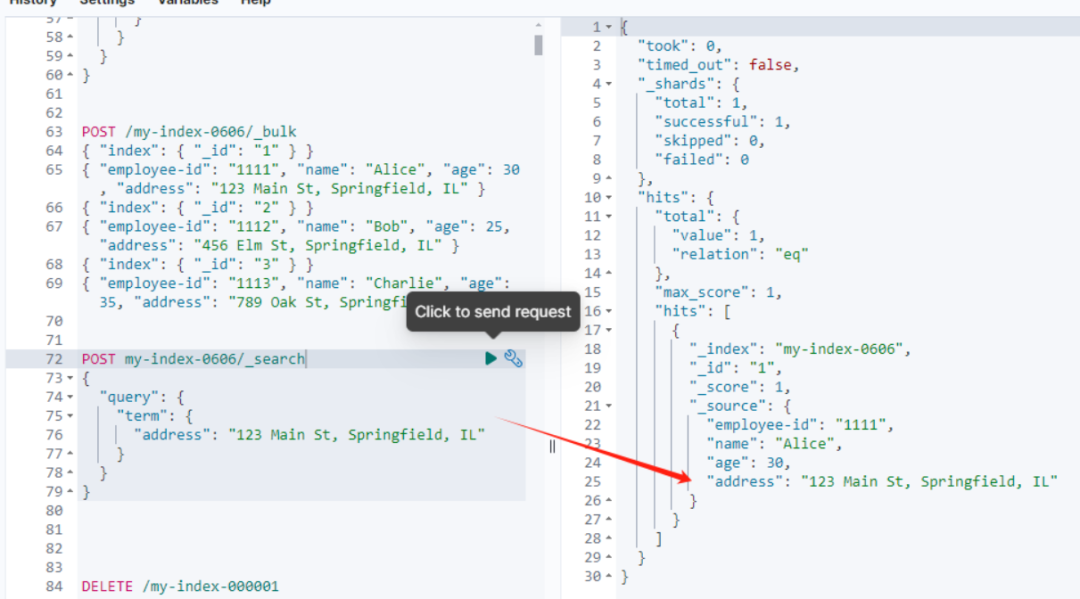
这就是基于正排索引做的轮询的结果。
3.3 列式存储的优势和劣势
优势:
列式存储使得对特定字段的聚合和排序操作更加高效,因为只需要读取相关列的数据,而不是整个文档的所有字段。
举例说明,假设我们有一个包含员工信息的索引(在之前基础上新增了字段),文档结构如下:
[{"employee-id": "1111", "name": "Alice", "age": 30, "salary": 5000, "address": "123 Main St, Springfield, IL"},{"employee-id": "1112", "name": "Bob", "age": 25, "salary": 6000, "address": "456 Elm St, Springfield, IL"},{"employee-id": "1113", "name": "Charlie", "age": 35, "salary": 7000, "address": "789 Oak St, Springfield, IL"}
]如果行式存储:读取每个文档时,所有字段数据都被加载,即使我们只关心其中一个字段的数据。
行式存储举例——计算平均薪资时,整个文档(包括 name、age、address 等)都要被读取。如下图所示:
读取整行信息,有点类似 MySQL 如下操作:
SELECT * FROM employees WHERE employee-id = '1111';返回结果:
{"employee-id": "1111", "name": "Alice", "age": 30, "salary": 5000, "address": "123 Main St, Springfield, IL"}如果列式存储:只读取特定字段的数据。
列式存储举例——计算平均薪资时,只需读取 salary 列的数据即可,避免了读取无关字段的数据。如下图所示。
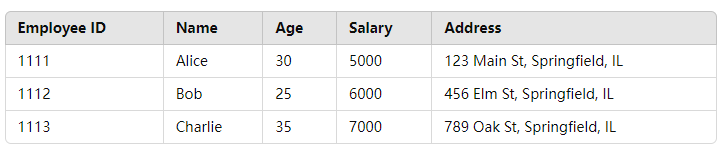
列式存储读取一列数据,有点类似 MySQL如下操作:
SELECT age FROM employees;返回结果:
[30, 25, 35]劣势:对于未被索引的字段,查询效率较低,因为需要遍历整个列的数据来匹配查询条件。
4、结论
通过这些示例,我们可以更清楚地理解 Elasticsearch 中列式存储和 doc_values 的应用。
列式存储使得对特定字段的聚合和排序操作更加高效,但对于未被索引的字段,查询效率较低,因为需要遍历整个列的数据来匹配查询条件。
希望这些解释能帮助你更好地理解 Elasticsearch 的存储和查询机制。
如果你对字段的查询和聚合有特定需求,合理使用 index 和 doc_values 设置可以大大提升性能和效率。
新时代写作与互动:《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

比同事抢先一步学习进阶干货!