初学者自己做网站廊坊seo推广公司
一、Milvus 介绍及安装
Milvus 于 2019 年创建,其目标只有一个:存储、索引和管理由深度神经网络和其他机器学习 (ML) 模型生成的大量嵌入向量。它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
作为专门为处理输入向量查询而设计的数据库,它能够对万亿规模的向量进行索引。与现有的关系数据库主要处理遵循预定义模式的结构化数据不同,Milvus 是自下而上设计的,旨在处理从非结构化数据转换而来的嵌入向量。
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次,分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。

在 Milvus 中相关术语:
-
Collection: 包含一组
Entity,可以理解为关系型数据库中的表。 -
Entity: 包含一组
Field,可以理解为关系型数据库中的行。 -
Field:可以是代表对象属性的结构化数据,也可以是代表对象特征的向量。可以理解为关系型数据库中的字段。
-
Partition:分区,针对
Collection数据分区存储多个部分,每个分区又可以包含多个段。 -
Segment:分段,一个
Partition可以包含多个Segment。一个Segment可以包含多个Entity。在搜索时,会搜索每个Segment合并后返回结果。 -
Sharding:分片,将数据分散到不同节点上,充分利用集群的并行计算能力进行写入,默认情况下,单个
Collection包含 2 个分片。 -
Index:索引,可以提高数据搜索的速度。但一个向量字段仅支持一种索引类型。
更多介绍可以参考官方文档:
官网地址:https://milvus.io/
Milvus Docker 单机部署
单机版 Milvus 主要包括三个组件:
- Milvus:负责提供系统的核心功能。
- etcd :元数据引擎,用于管理
Milvus内部组件的元数据访问和存储,例如:proxy、index node等。 - MinIO :存储引擎,负责维护
Milvus的数据持久化。
需要提前安装好 Docker、Docker-compose 环境。
官方介绍:https://milvus.io/docs/install_standalone-docker.md
下载 docker-compose.yml 文件:
wget https://github.com/milvus-io/milvus/releases/download/v2.3.1/milvus-standalone-docker-compose.yml -O docker-compose.yml
启动 Milvus
docker compose up -d
查看启动服务:
docker ps

安装可视化工具
vi docker-compose-insight.yml
version: '3.5'services:insight:container_name: milvus-insightimage: milvusdb/milvus-insight:latestenvironment:HOST_URL: http://172.19.222.20:3000MILVUS_URL: 172.19.222.20:19530ports:- "3000:3000"networks:- milvusnetworks:milvus:
启动
docker-compose -f docker-compose-insight.yml up -d
浏览器访问可视化页面:
http://ip:3000
二、Python Api 使用
Milvus 与 Python Api 版本对应如下:
| Milvus 版本 | 推荐的 PyMilvus 版本 |
|---|---|
| 1.0.* | 1.0.1 |
| 1.1.* | 1.1.2 |
| 2.0.x | 2.0.2 |
| 2.1.x | 2.1.3 |
| 2.2.x | 2.2.3 |
| 2.3.0 | 2.3.7 |
| 2.4.0-rc.1 | 2.4.0 |
这里安装 2.3.7 版本依赖,推荐 Python 版本 3.8 以上:
pip install pymilvus==v2.3.7 -i https://pypi.tuna.tsinghua.edu.cn/simple
连接 Milvus :
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")
如果有用户名密码,可以使用:
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus",db_name="default"
)
1. 创建 Collection
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")client.create_collection(collection_name="test", # 集合的名称dimension=5, # 向量的维度primary_field_name="id", # 主键字段名称id_type="int", # 主键的类型vector_field_name="vector", # 向量字段的名称metric_type="L2", # 指标类型,用于测量向量嵌入之间的相似性的算法。auto_id=True # 主键ID自动递增
)
或者自定义设置字段:
from pymilvus import MilvusClient, DataTypeclient = MilvusClient("http://172.19.222.20:19530")# 声明 schema
schema = MilvusClient.create_schema(auto_id=False,enable_dynamic_field=False,
)
# 添加主键字段
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
# 添加向量字段
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
# 添加其他字段
schema.add_field(field_name="name", datatype=DataType.VARCHAR, max_length=255)
schema.verify()
# 索引
index_params = client.prepare_index_params()
index_params.add_index(field_name="id",index_type="STL_SORT"
)index_params.add_index(field_name="vector",index_type="IVF_FLAT",metric_type="L2",params={"nlist": 1024}
)# 创建 collection
client.create_collection(collection_name="test1",schema=schema,index_params=index_params
)其中向量索引方式有如下选择:
| 索引 | 说明 |
|---|---|
| FLAT | 准确率高, 适合数据量小,暴力求解相似。 |
| IVF-FLAT | 量化操作, 准确率和速度的平衡 |
| IVF | inverted file 先对空间的点进行聚类,查询时先比较聚类中心距离,再找到最近的N个点。 |
| IVF-SQ8 | 量化操作,disk cpu GPU 友好 |
| SQ8 | 对向量做标量量化,浮点数表示转为int型表示,4字节->1字节。 |
| IVF-PQ | 快速,但是准确率降低,把向量切分成m段,对每段进行聚类 |
| HNSW | 基于图的索引,高效搜索场景,构建多层的NSW。 |
| ANNOY | 基于树的索引,高召回率 |
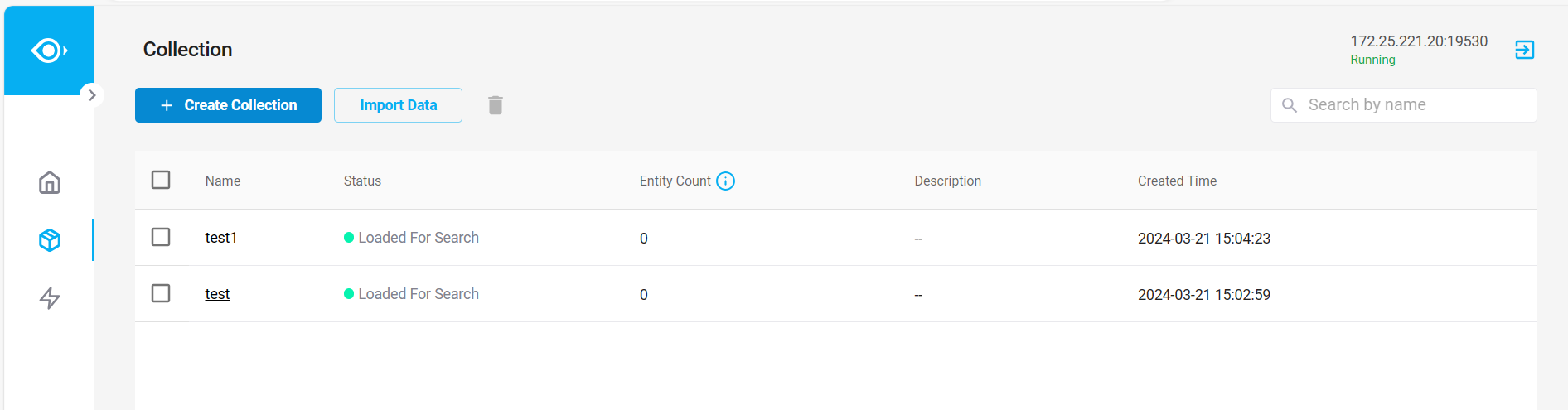
执行后可在可视化工具中看到创建的 Collection :
2. insert 写入数据:
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")# 写入一条
res1 = client.insert(collection_name="test1", # 前面创建的 collection 名称data={"id": 0, # 主键ID"vector": [ # 向量0.6186516144460161,0.5927442462488592,0.848608119657156,0.9287046808231654,-0.42215796530168403],"name": "测试1" # 其他字段}
)
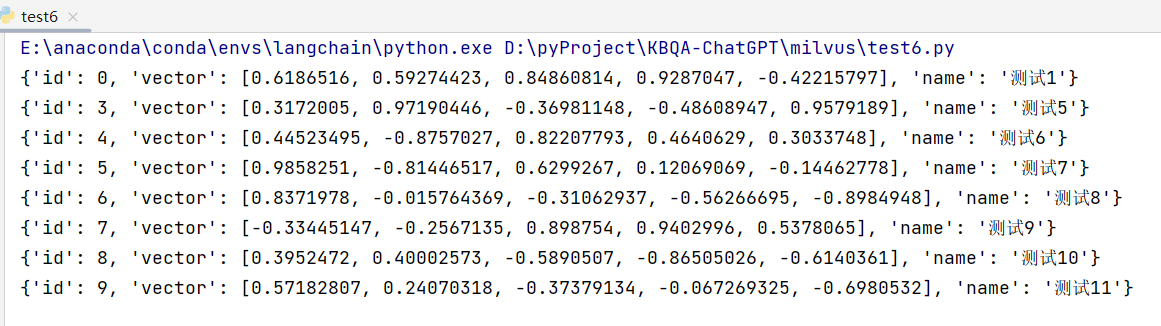
print(res1)# 批量写入
res2 = client.insert(collection_name="test1",data=[{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "name": "测试3"},{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "name": "测试4"},{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "name": "测试5"},{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "name": "测试6"},{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "name": "测试7"},{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "name": "测试8"},{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "name": "测试9"},{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "name": "测试10"},{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "name": "测试11"}],
)print(res2)

3. search 向量相似查询数据
3.1 向量相似检索
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")res = client.search(collection_name="test1",data=[[0.05, 0.23, 0.07, 0.45, 0.13]],limit=3,search_params={"metric_type": "L2","params": {}}
)for row in res[0]:print(row)
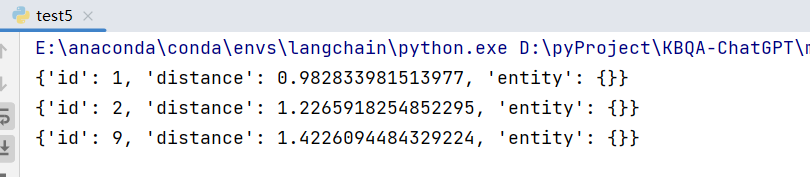
3.2 向量相似检索 + 过滤
过滤和 SQL 用法类似,通过 filter 字段控制:
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")res = client.search(collection_name="test1",data=[[0.05, 0.23, 0.07, 0.45, 0.13]],limit=3,filter='name == "测试5" and id > 2',search_params={"metric_type": "L2","params": {}}
)for row in res[0]:print(row)
3.3 向量相似检索 + 模糊查询过滤
模糊查询和 SQL 用法一直,使用 like 。
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")res = client.search(collection_name="test1",data=[[0.05, 0.23, 0.07, 0.45, 0.13]],limit=3,filter='name == "name like "测试%" and id > 2',search_params={"metric_type": "L2","params": {}}
)for row in res[0]:print(row)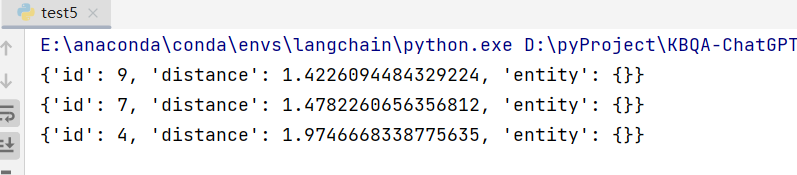
3.4 向量相似检索 + 指定输出字段
通过 output_fields 控制输出字段。
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")res = client.search(collection_name="test1",data=[[0.05, 0.23, 0.07, 0.45, 0.13]],limit=3,filter='name like "测试%" and id > 2',output_fields=["vector", "name"],search_params={"metric_type": "L2","params": {}}
)for row in res[0]:print(row)
3.5 向量相似检索 + 分页
通过增加 offset + limit 的方式实现:
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")res = client.search(collection_name="test1",data=[[0.05, 0.23, 0.07, 0.45, 0.13]],limit=3,offset=3,filter='name like "测试%" and id > 2',output_fields=["vector", "name"],search_params={"metric_type": "L2","params": {}}
)for row in res[0]:print(row)
4. query 普通查询数据
query 用法和 search 类似,只是不用传递 data 向量了:
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")res = client.query(collection_name="test1",filter="id > 1",output_fields=["*"]
)
for row in res:print(row)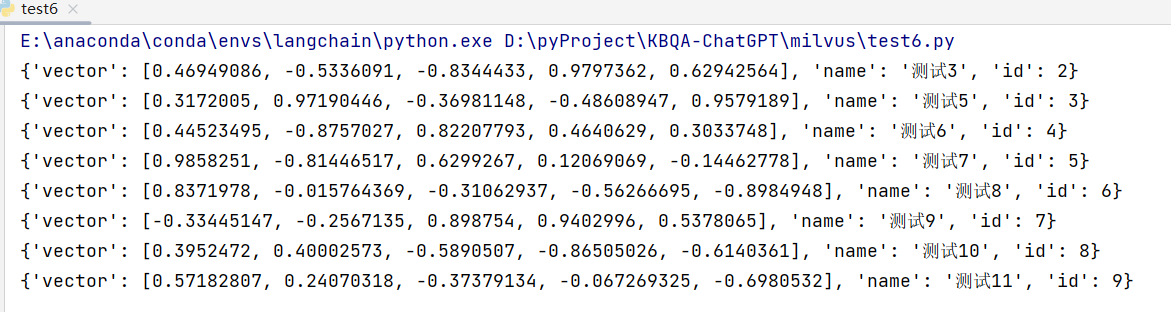
5. upsert 插入或更新数据
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")## 查询 id = 2 的数据
res = client.query(collection_name="test1",filter="id == 2",output_fields=["*"]
)
row = res[0]
print(row)# 修改name为张三
row['name'] = "张三"# 保存修改
client.upsert(collection_name="test1",data=[row]
)
再次查询:
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")## 查询 id = 2 的数据
res = client.query(collection_name="test1",filter="id == 2",output_fields=["*"]
)
row = res[0]
print(row)

6. delete 删除数据
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")# 删除 id 为 1、2 的数据
client.delete(collection_name="test1",ids=[1, 2]
)
查询数据:
from pymilvus import MilvusClientclient = MilvusClient("http://172.19.222.20:19530")res = client.query(collection_name="test1",filter="",output_fields=["*"],limit=1000
)
for row in res:print(row)