嘉定装饰装修网站域名大全免费网站
目录
什么是遍历?
一、Collection集合的遍历方式
1.迭代器遍历
方法
流程
案例
2. foreach(增强for循环)遍历
案例
3.Lamdba表达式遍历
案例
二、数据结构
数据结构介绍
常见数据结构
栈(Stack)
队列(Queue)
链表(Link)
散列表(Hash Table)
树(Tree)
List接口
ArraysList集合
LinkedList集合
Set接口
HaseSet集合
LinkedHaseSet集合
TreeSet集合
工具类
Collecations集合工具类
补充
可变参数
什么是遍历?
遍历就是一个一个的把容器中的元素访问一遍
一、Collection集合的遍历方式
Collection集合的遍历方式有三种:
- 迭代器
- foreach(增强for循环)
- JDK 1.8开始之后的新技术 Lambda表达式
1.迭代器遍历
方法
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素
E next():获取下一个元素值!
boolean hasNext():判断是否有下一个元素,有返回true ;反之,则返回false
流程
1.先获取当前集合的迭代器,迭代器需要写泛型,指定类型
Iterator<E> it = lists.iterator();
2.定义一个while循环,问一次取一次
通过it.hasNext()询问是否有下一个元素,有就通过
it.next()取出下一个元素
出现异常NoSuchElementException,出现没有此元素异常!
案例
public class CollectionDemo01 {public static void main(String[] args) {Collection<String> lists = new ArrayList<>();lists.add("张三");lists.add("李四");lists.add("王五");lists.add("赵六");System.out.println(lists);// lists = [张三, 李四, 王五, 赵六]// 1.得到集合的迭代器对象。Iterator<String> it = lists.iterator();// 2.使用while循环遍历。while(it.hasNext()){String ele = it.next();System.out.println(ele);}} }[张三, 李四, 王五, 赵六] 张三 李四 王五 赵六
2. foreach(增强for循环)遍历
foreach可以遍历集合或者数组
缺点:foreach遍历无法知道遍历到了哪个元素了,因为没有索引
案例
public class CollectionDemo02 {public static void main(String[] args) {Collection<String> lists = new ArrayList<>();lists.add("张三");lists.add("李四");lists.add("王五");lists.add("赵六");System.out.println(lists);// lists = [张三, 李四, 王五, 赵六]// elefor (String ele : lists) {System.out.println(ele);}} }[张三, 李四, 王五, 赵六] 张三 李四 王五 赵六
3.Lamdba表达式遍历
JDK 1.8开始之后的新技术Lambda表达式,调用foeEach
案例
public class CollectionDemo03 {public static void main(String[] args) {Collection<String> lists = new ArrayList<>();lists.add("张三");lists.add("李四");lists.add("王五");lists.add("赵六");System.out.println(lists);// lists = [张三, 李四, 王五, 赵六]// elelists.forEach(s -> {System.out.println(s);});// lists.forEach(s -> System.out.println(s)); // // lists.forEach(System.out::println);} }
二、数据结构
数据结构介绍
数据结构:数据是以什么方式组合在一起的
数据结构不仅要存储元素,还要提供对元素进行增删改查的操作
常见数据结构
常见的数据结构:栈、队列、链表、散列表、树
栈(Stack)
栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈顶 (top)。它是后进先出(LIFO)的。对栈的基本操作只有 push(进栈)和 pop(出栈)两种,前者相当于插入,后者相当于删除最后的元素

队列(Queue)
队列是一种特殊的线性表 ,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头
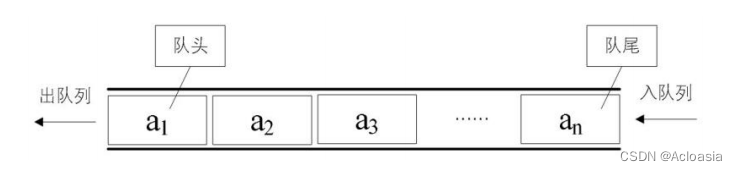
链表(Link)
1
散列表(Hash Table)
散列表算法希望能尽量做到不经过任何比较,通过一次存取就能得到所查找的数据元素构造散列函数的方法有:直接定址法: 取关键字或关键字的某个线性函数值为散列地址。
即:h(key) = key 或 h(key) = a * key + b,其中 a 和 b 为常数。
数字分析法
平方取值法: 取关键字平方后的中间几位为散列地址。
折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址。
除留余数法:取关键字被某个不大于散列表表长 m 的数 p 除后所得的余数为散列地址, 即:h(key) = key MOD p p ≤ m
随机数法:选择一个随机函数,取关键字的随机函数值为它的散列地址,
即:h(key) = random(key)
树(Tree)
树具有的特点:
每一个节点有零个或者多个子节点
没有父节点的节点称之为根节点,一个树最多有一个根节点。
每一个非根节点有且只有一个父节点
| 名词 | 含义 |
|---|---|
| 节点 | 指树中的一个元素 |
| 节点的度 | 节点拥有的子树的个数,二叉树的度不大于2 |
| 叶子节点 | 度为0的节点,也称之为终端结点 |
| 高度 | 叶子结点的高度为1,叶子结点的父节点高度为2,以此类推,根节点的高度最高 |
| 层 | 根节点在第一层,以此类推 |
| 父节点 | 若一个节点含有子节点,则这个节点称之为其子节点的父节点 |
| 子节点 | 子节点是父节点的下一层节点 |
| 兄弟节点 | 拥有共同父节点的节点互称为兄弟节点 |
树基本结构介绍
树的进阶
注意事项:
除了java.util.PriorityQueue没有实现Cloneable接口外,Java合集框架中的其他类所有类都实现了java.util.Cloneable和java.util.Serializable接口
所以,除了优先队列,其他合集都可以克隆和实例化
树
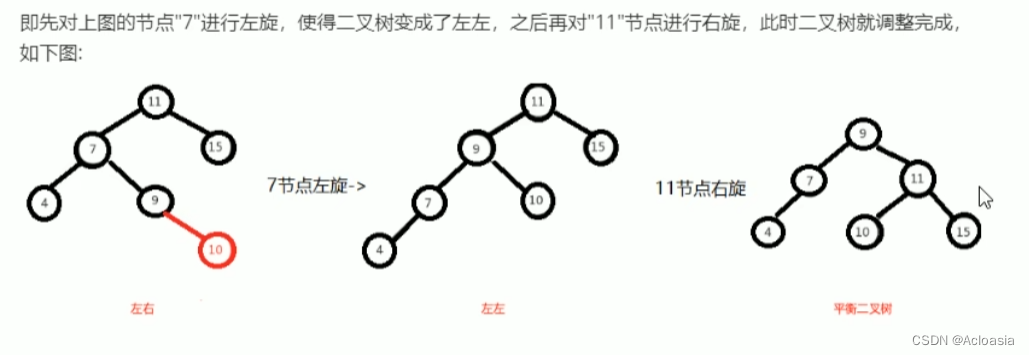
左边高,向右旋
如果右旋,无法满足条件的话,放弃右旋,用左旋
List接口
List系列集合:添加的元素,是有序,可重复,有索引的
LinkedList: 添加的元素,是有序,可重复,有索引的
ArrayList: 添加的元素,是有序,可重复,有索引的
Vector 是线程安全的,速度慢,工作中很少使用
List接口中常用方法
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。
public E get(int index):返回集合中指定位置的元素。
public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。
public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素
ArraysList集合
ArrayList实现类集合底层基于数组存储数据的,查询快,增删慢
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上
public E get(int index):返回集合中指定位置的元素
public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素
public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回更新前的元素值
底层
特点:元素增删慢,查找快
LinkedList集合
LinkedList是支持双链表,定位前后的元素是非常快的,增删首尾的元素也是最快的。
提供了很多操作首尾元素的特殊API可以做栈和队列的实现是一个双向链表
底层
特点:
方法:
public void addFirst(E e):将指定元素插入此列表的开头。
public void addLast(E e):将指定元素添加到此列表的结尾。
public E getFirst():返回此列表的第一个元素。
public E getLast():返回此列表的最后一个元素。
public E removeFirst():移除并返回此列表的第一个元素。
public E removeLast():移除并返回此列表的最后一个元素。
public E pop():从此列表所表示的堆栈处弹出一个元素。
public void push(E e):将元素推入此列表所表示的堆栈。
public boolean isEmpty():如果列表不包含元素,则返回true
Set接口
介绍
Set是一个用于存储和处理无重复元素的高效数据结构
特点
没有重复元素,没有提过索引遍历
可以使用HaseSet、LinkedHashSet、TreeSet类
研究两个问题(面试热点):
1)Set集合添加的元素是不重复的,是如何去重复的?
2)Set集合元素无序的原因是什么?
HaseSet集合
HashSet:添加的元素,是无序,不重复,无索引的
底层
LinkedHaseSet集合
LinkedHashSet底层依然是使用哈希表存储元素的,但是每个元素都额外带一个链来维护添加顺序
增删查快,而且有序。缺点:多了一个存储顺序的链会占内存空间,而且不允许重复,无索引。
TreeSet集合
TreeSet: 不重复,无索引,按照大小默认升序排序
TreeSet集合自自排序的方式:
- 有值特性的元素直接可以升序排序。(浮点型,整型)
- 字符串类型的元素会按照首字符的编号排序。
- 对于自定义的引用数据类型,TreeSet默认无法排序,执行的时候直接报错,因为说明排序规则。
自定义的引用数据类型的排序实现:
对于自定义的引用数据类型,TreeSet默认无法排序
所以我们需要定制排序的大小规则,程序员定义大小规则的方案有2种:
第1种:直接为对象的类实现比较器规则接口Comparable,重写比较方法(拓展方式)
如果程序员认为比较者大于被比较者 返回正数
如果程序员认为比较者小于被比较者 返回负数
如果程序员认为比较者等于被比较者 返回0
第2种:直接为集合设置比较器Comparator对象,重写比较方法
如果程序员认为比较者大于被比较者 返回正数
如果程序员认为比较者小于被比较者 返回负数
如果程序员认为比较者等于被比较者 返回0
注意:如果类和集合都带有比较规则,优先使用集合自带的比较规则
Map接口
Map集合是一种双列集合,每个元素包含两个值。
Map集合的每个元素的格式:key=value(键值对元素)。
Map集合也被称为“键值对集合”Map集合的完整格式:{key1=value1 , key2=value2 , key3=value3 , ...}特点:
- Map集合的特点都是由键决定的
- Map集合的键是无序,不重复的,无索引的。Map集合后面重复的键对应的元素会覆盖前面的整个元素
- Map集合的值无要求
- Map集合的键值对都可以为null
注意:
- Map集合的键和值都可以存储自定义类型。
- 如果希望Map集合认为自定义类型的键对象重复了,必须重写对象的hashCode()和equals()方法
实现类:
HashMap:元素按照键是无序,不重复,无索引,值不做要求。
LinkedHashMap:元素按照键是有序,不重复,无索引,值不做要求。TreeMap:按照键是可排序不重复的键值对集合
HashMap集合
LinkedHashMap集合
TreeMap集合
工具类
Collecations集合工具类
java.utils.Collections:是集合工具类
Collections并不属于集合,是用来操作集合的工具类。
Collections有几个常用的API:
public static <T> boolean addAll(Collection<? super T> c, T... elements)
给集合对象批量添加元素!
public static void shuffle(List<?> list) :打乱集合顺序。
public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。
public static <T> void sort(List<T> list,Comparator<? super T> ):将集合中元素按照指定规则排序。
补充
可变参数
可变参数用在形参中可以接收多个数据
可变参数的格式:数据类型... 参数名称可变参数的作用
- 传输参数非常灵活,方便
- 可以不传输参数
- 可以传输一个参数
- 可以传输多个参数
- 可以传输一个数组
可变参数在方法内部本质上就是一个数组
可变参数的注意事项:
- 一个形参列表中可变参数只能有一个
- 可变参数必须放在形参列表的最后面
public class MethodDemo {public static void main(String[] args) {sum(); // 可以不传输参数。sum(10); // 可以传输一个参数。sum(10,20,30); // 可以传输多个参数。sum(new int[]{10,30,50,70,90}); // 可以传输一个数组。}public static void sum(int...nums){// 可变参数在方法内部本质上就是一个数组。System.out.println("元素个数:"+nums.length);System.out.println("元素内容:"+ Arrays.toString(nums));System.out.println("--------------------------");} }