南通专业网站排名推广广告推广平台赚取佣金
目录
一、Hive做离线批处理
1、实现步骤
①、启动hadoop,启动hive
②、在hive下创建weblog库,并使用
③、 创建外部表管理数据
④、为总表添加当天分区数据
⑤、建立数据清洗表,用于清洗出业务所需的字段。
⑥、业务处理
⑦、创建业务表并插入数据
⑧、从清洗表查询得到当天的统计指标,插入到业务表中
⑨、利用Sqoop工具从HDFS上将数据导入到Mysql数据库中
二、Hive的占位符与文件调用
1、概述
2、Hive文件的调用
3、Hive占位符的使用
4、结合业务实现
5、Linux Crontab定时任务
三、实时业务系统搭建
1、Flume与Kafka的连通
四、实时流开发环境搭建
1、Spark与HBase整合基础
2、实时流业务处理
一、Hive做离线批处理
1、实现步骤

①、启动hadoop,启动hive
进入hive的bin目录(以后台方式启动)
nohup hive --service metastore &
nohup hive --service hiveserver2 &
sh hive
②、在hive下创建weblog库,并使用
create database weblog;
use weblog
③、 创建外部表管理数据
建立总表,用于管理所有的字段数据。
总表特点:管理所有字段,外部表,分区表
hdfs上的数据:
建表语句:
create external table flux (url string,urlname string,title string,chset string,scr string,col string,lg string,je string,ec string,fv string,cn string,ref string,uagent string,stat_uv string,stat_ss string,cip string) PARTITIONED BY (reporttime string) row format delimited fields terminated by '|' location '/weblog';



④、为总表添加当天分区数据
1、msck repair table flux;
2、alter table flux add partition(reporttime='2022-04-20') location '/weblog/reporttime=2022-04-20';

⑤、建立数据清洗表,用于清洗出业务所需的字段。
dataclear 指定的分割符 : |
去除多余字段,只保留需要的字段,并将会话信息拆开保存
所需要的字段为:
reporttime、url、urlname、uvid、ssid、sscount、sstime、cip
create table dataclear(reportTime string,url string,urlname string,uvid string,ssid string,sscount string,sstime string,cip string)row format delimited fields terminated by '|';
从总表中查询出当天的对应的字段插入到清洗表中
insert overwrite table dataclear select reporttime,url,urlname,stat_uv,split(stat_ss,"_")[0],split(stat_ss,"_")[1],split(stat_ss,"_")[2],cip from flux;



⑥、业务处理
1、pv
select count(*) as pv from dataclear where reportTime = '2022-04-20';
2、uv
uv - 独立访客数 - 一天之内所有的访客的数量 - 一天之内uvid去重后的总数
select count(distinct uvid) as uv from dataclear where reportTime = '2022-04-20';
3、vv
vv - 独立会话数 - 一天之内所有的会话的数量 - 一天之内ssid去重后的总数
select count(distinct ssid) as vv from dataclear where reportTime = '2022-04-20';
4、br
br - 跳出率 - 一天内跳出的会话总数/会话总数
select round(br_taba.a/br_tabb.b,4)as br from (select count(*) as a from (select ssid from dataclear where reportTime='2022-04-20' group by ssid having count(ssid) = 1) as br_tab) as br_taba,(select count(distinct ssid) as b from dataclear where reportTime='2022-04-20') as br_tabb;
这段sql就是对会话id分组,然后求出会话id为1的个数,这个就是跳出会话
5、newip
newip - 新增ip总数 - 一天内所有ip去重后在历史数据中从未出现过的数量
select count(distinct dataclear.cip) from dataclear where dataclear.reportTime = '2022-04-20' and cip not in (select dc2.cip from dataclear as dc2 where dc2.reportTime < '2022-04-20');
6、newcust
newcust - 新增客户数 - 一天内所有的uvid去重后在历史数据中从未出现过的总数
select count(distinct dataclear.uvid) from dataclear where dataclear.reportTime='2021-05-10'
and uvid not in
(select dc2.uvid from dataclear as dc2 where dc2.reportTime < '2021-05-10');
7、avgtime
avgtime - 平均访问时常 - 一天内所有会话的访问时常的平均值
注: 一个会话的时长 = 会话中所有访问的时间的最大值 - 会话中所有访问时间的最小值
select avg(atTab.usetime) as avgtime from(select max(sstime) - min(sstime) as usetime from dataclear where reportTime='2022-04-20' group by ssid) as atTab;
8、avgdeep
avgdeep - 平均访问深度 - 一天内所有会话访问深度的平均值
一个会话的访问深度=一个会话访问的所有url去重后的个数
比如会话①:url http://demo/a.jsp http://demo/b.jsp http://demo/a.jsp 则访问深度是2
select round(avg(adTab.deep),4) as avgdeep from (select count(distinct urlname) as deep from dataclear where reportTime='2022-04-20' group by ssid) as adTab;


⑦、创建业务表并插入数据
create table tongji(reportTime string,pv int,uv int,vv int, br double,newip int, newcust int, avgtime double,avgdeep double) row format delimited fields terminated by '|';


⑧、从清洗表查询得到当天的统计指标,插入到业务表中
insert overwrite table tongji select '2022-04-20',tab1.pv,tab2.uv,tab3.vv,tab4.br,tab5.newip,tab6.newcust,tab7.avgtime,tab8.avgdeep from(select count(*) as pv from dataclear where reportTime = '2022-04-20') as tab1, (select count(distinct uvid) as uv from dataclear where reportTime = '2022-04-20') as tab2, (select count(distinct ssid) as vv from dataclear where reportTime = '2022-04-20') as tab3, (select round(br_taba.a/br_tabb.b,4)as br from (select count(*) as a from (select ssid from dataclear where reportTime='2022-04-20' group by ssid having count(ssid) = 1) as br_tab) as br_taba, (select count(distinct ssid) as b from dataclear where reportTime='2022-04-20') as br_tabb) as tab4, (select count(distinct dataclear.cip) as newip from dataclear where dataclear.reportTime = '2022-04-20' and cip not in (select dc2.cip from dataclear as dc2 where dc2.reportTime < '2022-04-20')) as tab5, (select count(distinct dataclear.uvid) as newcust from dataclear where dataclear.reportTime='2022-04-20' and uvid not in (select dc2.uvid from dataclear as dc2 where dc2.reportTime < '2022-04-20')) as tab6, (select round(avg(atTab.usetime),4) as avgtime from (select max(sstime) - min(sstime) as usetime from dataclear where reportTime='2022-04-20' group by ssid) as atTab) as tab7, (select round(avg(deep),4) as avgdeep from (select count(distinct urlname) as deep from dataclear where reportTime='2022-04-20' group by ssid) as adTab) as tab8;

⑨、利用Sqoop工具从HDFS上将数据导入到Mysql数据库中
进入mysql:
mysql -uroot -proot
创建和使用库:create database weblog;
use weblog;创建表:
create table tongji(reporttime varchar(40),pv int,uv int,vv int,br double,newip int,newcust int,avgtime double,avgdeep double);
使用Sqoop将数据导入到mysql中:
进入:
cd /home/software/sqoop-1.4.7/bin/
执行:sh sqoop export --connect jdbc:mysql://hadoop01:3306/weblog --username root --password root --export-dir '/user/hive/warehouse/weblog.db/tongji' --table tongji -m 1 --fields-terminated-by '|'
进入mysql 查询:



二、Hive的占位符与文件调用
1、概述
对于上面的工作,我们发现需要手动去写hql语句从而完成离线数据的ETL,但每天都手动来做显然是不合适的,所以可以利用hive的文件调用与占位符来解决这个问题。
2、Hive文件的调用
实现步骤:
①、编写一个文件,后缀名为.hive
比如我们现在我们创建一个01.hive文件
目的是在 hive的weblog数据库下,创建一个tb1表
use weblog; create table tb1 (id int,name string);②、进入hive安装目录的bin目录
执行: sh hive -f 01.hive
注:-f 参数后跟的是01.hive文件的路径
③、测试hive的表是否创建成功


3、Hive占位符的使用
我们现在想通过hive执行文件,将 "tb1"这个表删除,则我们可以这样做:
①、创建02.hive文件
use weblog; drop table ${tb_name};②、在bin目录下,执行:
sh hive -f 02.hive -d tb_name="tb1"

4、结合业务实现
在hive最后插入数据时,涉及到一个日志的分区是以每天为单位,所以我们需要手动去写这个日期,比如 2022-04-20。我们可以这样做:
①、将hql语句里的日期相关的取值用占位符来表示,并写在weblog.hive文件里
use weblog; insert overwrite table tongji select ${reportTime},tab1.pv,tab2.uv,tab3.vv,tab4.br,tab5.newip,tab6.newcust,tab7.avgtime,tab8.avgdeep from (select count(*) as pv from dataclear where reportTime = ${reportTime}) as tab1,(select count(distinct uvid) as uv from dataclear where reportTime = ${reportTime}) as tab2,(select count(distinct ssid) as vv from dataclear where reportTime = ${reportTime}) as tab3,(select round(br_taba.a/br_tabb.b,4)as br from (select count(*) as a from (select ssid from dataclear where reportTime=${reportTime} group by ssid having count(ssid) = 1) as br_tab) as br_taba,(select count(distinct ssid) as b from dataclear where reportTime=${reportTime}) as br_tabb) as tab4,(select count(distinct dataclear.cip) as newip from dataclear where dataclear.reportTime = ${reportTime} and cip not in (select dc2.cip from dataclear as dc2 where dc2.reportTime < ${reportTime})) as tab5,(select count(distinct dataclear.uvid) as newcust from dataclear where dataclear.reportTime=${reportTime} and uvid not in (select dc2.uvid from dataclear as dc2 where dc2.reportTime < ${reportTime})) as tab6,(select round(avg(atTab.usetime),4) as avgtime from (select max(sstime) - min(sstime) as usetime from dataclear where reportTime=${reportTime} group by ssid) as atTab) as tab7,(select round(avg(deep),4) as avgdeep from (select count(distinct urlname) as deep from dataclear where reportTime=${reportTime} group by ssid) as adTab) as tab8;
②、在hive 的bin目录下执行:
sh hive -f weblog.hive -d reportTime="2022-04-20"
对于日期,如果不想手写的话,可以通过linux的指令来获取:
date "+%G-%m-%d"
所以我们可以这样来执行hive文件的调用:
sh hive -f weblog.hive -d reportTime=`date "+%G-%m-%d"`(注:是键盘右上方的反引号)
也可以写为:
sh hive -f weblog.hive -d reportTime=$(date "+%G-%m-%d")

5、Linux Crontab定时任务
在工作中需要数据库在每天零点自动备份所以需要建立一个定时任务。
crontab命令的功能是在一定的时间间隔调度一些命令的执行。
可以通过 crontab -e 进行定时任务的编辑
crontab文件格式:
* * * * * command
minute hour day month week command
分 时 天 月 星期 命令
示例:
*/1 * * * * rm -rf /home/software/1.txt
每隔一分钟,删除指定目录的 1.txt文件
对于上面的项目,我们可以这样写:
45 23 * * * ./home/software/hive-3.1.2/bin/hive -f /home/software/hive-3.1.2/bin/weblog.hive -d time=`date "+%G-%m
-%d"`

三、实时业务系统搭建
1、Flume与Kafka的连通

1.启动zk集群
2.启动kafka集群在其bin目录下执行
指令:sh kafka-server-start.sh ../config/server.properties
3.创建主题
查看主题:sh kafka-topics.sh --list --zookeeper hadoop01:2181
创建主题:sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic fluxdata
4.配置flume的data下的weblog.conf(自己建的)
a1.sources=r1 a1.channels=c1 c2 a1.sinks=k1 k2a1.sources.r1.type=avro a1.sources.r1.bind=0.0.0.0 a1.sources.r1.port=44444 a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.i1.type=timestampa1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=hdfs://192.168.186.128:9000/weblog/reportTime=%Y-%m-%d a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.rollInterval=0 a1.sinks.k1.hdfs.rollSize=0 a1.sinks.k1.hdfs.rollCount=1000a1.sinks.k2.type=org.apache.flume.sink.kafka.KafkaSink a1.sinks.k2.brokerList=hadoop01:9092,hadoop02:9092,hadoop03:9092 a1.sinks.k2.topic=fluxdataa1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100a1.sources.r1.channels=c1 c2 a1.sinks.k1.channel=c1 a1.sinks.k2.channel=c2启动hadoop
在flume的data目录,执行下面语句启动flume:
../bin/flume-ng agent -n a1 -c ./ -f ./weblog.conf -Dflume.root.logger=INFO,console
5.启动tomcat,访问埋点服务器
6.测试kafka是否能够收到数据
进入kafka的bin目录,启动kafka消费者线程:
sh kafka-console-consumer.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --topic fluxdata --from-beginning这时候我们访问页面:



四、实时流开发环境搭建
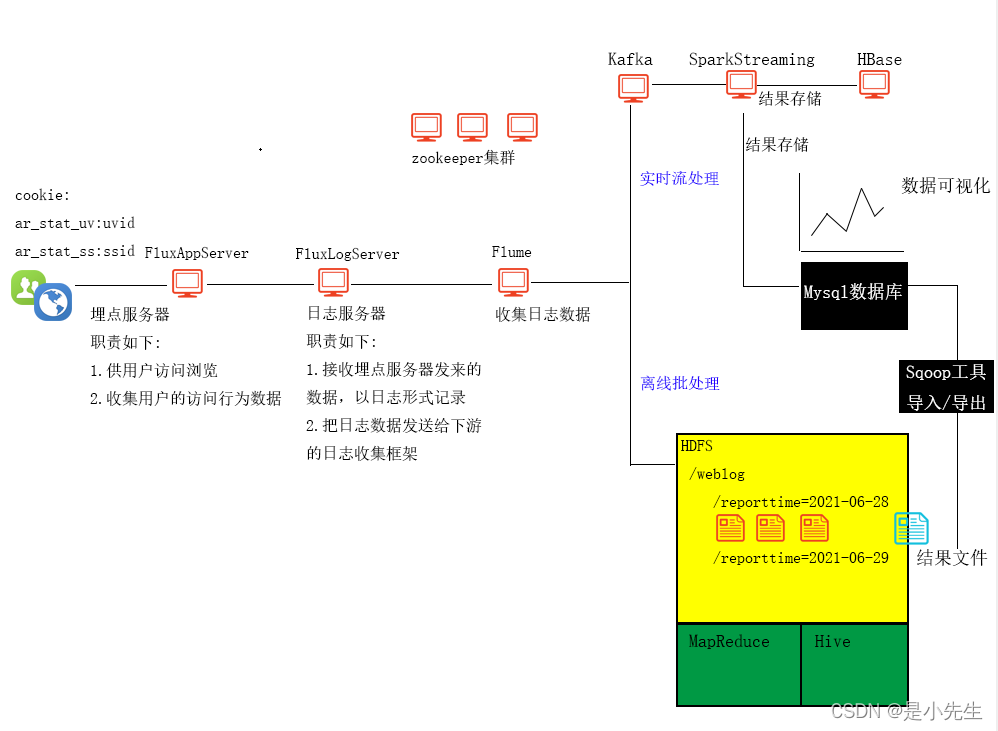
1、Spark与HBase整合基础
实现步骤:
1、启动IDEA
2、创建Maven工程,骨架选择quickstart
3、IDEA安装scala
4、为FluxStreamingServer工程添加scala sdk
这里如果spark如果是2版本,我们scala用scala2.11.7,稳定;如果是3版本,我们可以用scala2.12.X
5、创建一个scala目录,使其称为sources root
6、引入工程pom
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>FluxStreamingServer</artifactId><version>1.0-SNAPSHOT</version><name>FluxStreamingServer</name><!-- FIXME change it to the project's website --><url>http://www.example.com</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.7</maven.compiler.source><maven.compiler.target>1.7</maven.compiler.target></properties><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><!--spark --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.1.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.12</artifactId><version>3.1.2</version></dependency><!-- kafka --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.12</artifactId><version>2.8.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.1.2</version></dependency><!--HBase--><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase</artifactId><version>2.4.2</version><type>pom</type></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.4.2</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>2.4.2</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>2.4.2</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-protocol</artifactId><version>2.4.2</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-hadoop-compat</artifactId><version>2.4.2</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-mapreduce</artifactId><version>2.4.2</version></dependency><!--mysql--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><dependency><groupId>com.mchange</groupId><artifactId>c3p0</artifactId><version>0.9.5.5</version></dependency></dependencies><build><pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) --><plugins><!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle --><plugin><artifactId>maven-clean-plugin</artifactId><version>3.1.0</version></plugin><!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging --><plugin><artifactId>maven-resources-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.8.0</version></plugin><plugin><artifactId>maven-surefire-plugin</artifactId><version>2.22.1</version></plugin><plugin><artifactId>maven-jar-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-install-plugin</artifactId><version>2.5.2</version></plugin><plugin><artifactId>maven-deploy-plugin</artifactId><version>2.8.2</version></plugin><!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle --><plugin><artifactId>maven-site-plugin</artifactId><version>3.7.1</version></plugin><plugin><artifactId>maven-project-info-reports-plugin</artifactId><version>3.0.0</version></plugin><plugin><artifactId>maven-jar-plugin</artifactId><version>3.0.2</version><configuration><archive><manifest><addClasspath>true</addClasspath><useUniqueVersions>false</useUniqueVersions><classpathPrefix>lib/</classpathPrefix><mainClass>cn.tedu.streaming.StreamingDriver</mainClass></manifest></archive></configuration></plugin></plugins></pluginManagement></build> </project>7、学习Spark与Hbase整合基础
新建一个object
代码如下
package cn.yang.basicimport org.apache.hadoop.fs.shell.find.Result import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.TableOutputFormat import org.apache.hadoop.mapreduce.Job import org.apache.spark.{SparkConf, SparkContext}/*** 如何通过Spark将数据写出到HBase表中*/ object HBaseWriteDriver {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("writeHBase")val sc = new SparkContext(conf)//设定zookeeper集群IP地址。注意主机名和服务器ip对应一致sc.hadoopConfiguration.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")//设定zookeeper通信端口sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort","2181")//指定输出的HBase表名sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE,"tbx")//创建Hadoop Job对象val job = new Job(sc.hadoopConfiguration)//设定输出的key类型job.setOutputKeyClass(classOf[ImmutableBytesWritable])//设定输出的value类型,导包:org.apache.hadoop.fs.shell.find.Resultjob.setOutputValueClass(classOf[Result])//设定输出表类型job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])val rdd=sc.parallelize(List("1 tom 23","2 rose 18","3 jim 25","4 jary 30"))//为了能够将数据插入到HBase表,需要做类型转换 RDD[String]->RDD[(输出key,输出value)]val hbaseRDD=rdd.map{line=>val arr = line.split(" ")val id=arr(0)val name=arr(1)val age=arr(2)//创建HBase的行对象并指定行键。导包:org.apache.hadoop.hbase.client.Putval row = new Put(id.getBytes())//①参:列族名 ②参:列名 ③参:列值row.addColumn("cf1".getBytes(),"name".getBytes(),name.getBytes())row.addColumn("cf1".getBytes(),"age".getBytes(),age.getBytes())(new ImmutableBytesWritable(),row)}//执行插入hbaseRDD.saveAsNewAPIHadoopDataset(job.getConfiguration)} }8、启动服务器,三台zookeeper,hadoop,hbase
cd /home/software/hbase-2.4.2/bin/
sh start-hbase.sh9、进入01的hbase的shell建表 sh hbase shell
10、执行代码,附上读取与扫描hbase代码:
package cn.yang.basicimport org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.Result import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.spark.{SparkConf, SparkContext}object HBaseReadDriver {def main(args: Array[String]): Unit = {val conf=new SparkConf().setMaster("local").setAppName("read")val sc=new SparkContext(conf)//创建HBase环境参数对象val hbaseConf=HBaseConfiguration.create()hbaseConf.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")hbaseConf.set("hbase.zookeeper.property.clientPort","2181")//指定读取的表名hbaseConf.set(TableInputFormat.INPUT_TABLE,"tbx")//执行读取。并将HBase表数据读取到RDD结果集中val resultRDD=sc.newAPIHadoopRDD(hbaseConf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],//导包:import org.apache.hadoop.hbase.client.ResultclassOf[Result])resultRDD.foreach{case(k,v)=>val name=v.getValue("cf1".getBytes(),"name".getBytes())val age=v.getValue("cf1".getBytes(),"age".getBytes())println(new String(name)+":"+new String(age))}} }package cn.yang.basicimport org.apache.commons.codec.binary.Base64 import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.{Result, Scan} import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.protobuf.ProtobufUtil import org.apache.spark.{SparkConf, SparkContext}/*** 学习如何扫描hbase表数据*/ object HBaseScanDriver {def main(args: Array[String]): Unit = {val conf=new SparkConf().setMaster("local").setAppName("read")val sc=new SparkContext(conf)//创建HBase环境参数对象val hbaseConf=HBaseConfiguration.create()hbaseConf.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")hbaseConf.set("hbase.zookeeper.property.clientPort","2181")//指定读取的表名hbaseConf.set(TableInputFormat.INPUT_TABLE,"tbx")//创建HBase scan扫描对象val scan=new Scan()//设定扫描的起始行键scan.setStartRow("2".getBytes())//设定扫描终止行键。含头不含尾scan.setStopRow("4".getBytes())//设定scan对象使其生效hbaseConf.set(TableInputFormat.SCAN,Base64.encodeBase64String(ProtobufUtil.toScan(scan).toByteArray()))//执行读取。并将HBase表数据读取到RDD结果集中val resultRDD=sc.newAPIHadoopRDD(hbaseConf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],//导包:import org.apache.hadoop.hbase.client.ResultclassOf[Result])resultRDD.foreach{case(k,v)=>val name=v.getValue("cf1".getBytes(),"name".getBytes())val age=v.getValue("cf1".getBytes(),"age".getBytes())println(new String(name)+":"+new String(age))}} }








2、实时流业务处理
实现步骤:
①、启动三台服务器,启动zookeeper,启动hadoop,启动kafka,启动flume
cd /home/software/kafka_2.10-0.10.0.1/bin/
sh kafka-server-start.sh ../config/server.properties在flume的data目录,执行下面语句启动flume:
../bin/flume-ng agent -n a1 -c ./ -f ./weblog.conf -Dflume.root.logger=INFO,console
②、整合SparkStreaming与kafka,完成代码编写
在FluxStreamingServer下的scala文件下新建一个包,streaming,新建一个Driver
添加代码,下面为全部内容的代码:
结构:
Driver:
package cn.yang.streamingimport cn.yang.TongjiBean import cn.yang.dao.{HBaseUtil, MysqlUtil} import cn.yang.pojo.LogBean import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext}import java.util.Calendarobject Driver {def main(args: Array[String]): Unit = {//如果后续要使用SparkStreaming从kafka消费数据,启动的线程数至少是2个//其中一个线程负责SparkStreaming,另外一个线程负责从kafka消费数据//还需要设定一下序列化参数val conf=new SparkConf().setMaster("local[2]").setAppName("kafkasource").set("spark.serializer","org.apache.spark.serializer.KryoSerializer")val sc= new SparkContext(conf)sc.setLogLevel("error")//创建SparkStreaming对象,并指定批大小val ssc = new StreamingContext(sc,Seconds(5))//指定从kafka消费的主题,通过Array可以指定消费多个主题val topics = Array("fluxdata")//指定kafka的配置参数。通过Map来进行设定,key是属性名,value是属性值//需要指定:kafka服务集群列表;key value的序列化类型,固定为String类型,消费者组名val kafkaParams: Map[String, Object] = Map[String, Object]("bootstrap.servers" -> "hadoop01:9092,hadoop02:9092,hadoop03:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "bos")//1参:SparkStreaming对象 2参:从Kafka消费模式,消费指定主题的所有分区数据//3参:kafka订阅参阅信息val stream=KafkaUtils.createDirectStream[String, String](ssc,PreferConsistent,Subscribe[String, String](topics, kafkaParams)).map(x=>x.value())//打印输出方式一//foreachRDD,将当前批次内的所有数据转变为一个RDDstream.foreachRDD{rdd=>//将RDD[String]->Iterator[String]迭代器val lines=rdd.toLocalIterator//遍历迭代器while(lines.hasNext){//获取一条数据val line=lines.next()//第一步:做数据字段清洗。所需字段:url urlname uvid ssid sscount sstime cipval arr= line.split("\\|")val url=arr(0)val urlname=arr(1)val uvid=arr(13)val ssid=arr(14).split("_")(0)val sscount=arr(14).split("_")(1)val sstime=arr(14).split("_")(2)val cip=arr(15)//第二步:将清洗好的字段封装到bean中val logBean=LogBean(url,urlname,uvid,ssid,sscount,sstime,cip)//第三步:统计实时业务指标。有pv uv vv newip newcust//这5个指标的统计结果定为两种情况:1或0//3-1 pv:页面访问量。用户访问1次,就记作1个pvval pv =1//3-2 uv:独立用户数。uv=1或uv=0,处理逻辑://①拿着当前记录的uvid去HBase表(webtable)查询当天的所有数据//②、如果没查到此uvid的记录,则记uv=1//③、如果查到了此uvid的记录,则记uv=0//实现难点://如何查询Hbase表‘当天’的数据?//查询的起始时间戳startTime=当天的凌晨零点时间戳//查询的终止时间戳endTime=sstimeval endTime=sstime.toLongval calendar=Calendar.getInstance()calendar.setTimeInMillis(endTime)calendar.set(Calendar.HOUR,0)calendar.set(Calendar.MINUTE,0)calendar.set(Calendar.SECOND,0)calendar.set(Calendar.MILLISECOND,0)//获取当天凌晨零点的时间戳val startTime=calendar.getTimeInMillis//如何判断当前记录中的uvid在HBase表是否出现过?//可以使用HBase的行键过滤器来实现(使用HBase的行键正则过滤器)val uvRegex="^\\d+_"+uvid+".*$"val uvRDD=HBaseUtil.queryHBase(sc,startTime,endTime,uvRegex)val uv=if(uvRDD.count()==0) 1 else 0//3-3 vv:独立会话数。vv=1 或 vv=0 判断逻辑同uv//只不过判断指标变为当前记录的ssidval vvRegex="^\\d+_\\d+_"+ssid+".*$"val vvResult=HBaseUtil.queryHBase(sc,startTime,endTime,vvRegex)val vv=if(vvResult.count()==0) 1 else 0//3-4:newip:新增ip。newip=1 或newip=0 判断逻辑://用当前记录中的ip去HBase表查询历史数据(包含当天)//如果没查到,则newip=1.反之newip=0val ipRegex="^\\d+_\\d+_\\d+_"+cip+".*$"val ipResult=HBaseUtil.queryHBase(sc,startTime=0,endTime,ipRegex)val newip=if(ipResult.count()==0) 1 else 0//3-5 newcust:新增用户数。处理逻辑和newip相同//判断指标更换为uvid。正则使用uvRegexval custResult=HBaseUtil.queryHBase(sc,startTime=0,endTime,uvRegex)val newcust=if(custResult.count()==0)1 else 0//第四步:将统计好的业务指标封装到bean中,然后插入到mysql数据库中val tongjiBean=TongjiBean(sstime,pv,uv,vv,newip,newcust)MysqlUtil.saveToMysql(tongjiBean)//将封装好的bean数据存到HBase表中,供后续做查询使用HBaseUtil.saveToHBase(sc,logBean)println(logBean)}}//打印输出方式二,有线-----//stream.print()ssc.start()//保证SparkStreaming一直开启,直到用户主动中断退出为止ssc.awaitTermination()} }dao-HBaseUtil
package cn.yang.daoimport cn.yang.pojo.LogBean import org.apache.commons.codec.binary.Base64 import org.apache.hadoop.fs.shell.find.Result import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.{Put, Scan} import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp import org.apache.hadoop.hbase.filter.{RegexStringComparator, RowFilter} import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat} import org.apache.hadoop.hbase.protobuf.ProtobufUtil import org.apache.hadoop.mapreduce.Job import org.apache.spark.SparkContextimport scala.util.Randomobject HBaseUtil {def queryHBase(sc: SparkContext, startTime: Long, endTime: Long, regex: String) = {val hbaseConf=HBaseConfiguration.create()hbaseConf.set("hbase.zookeeper.quorum", "hadoop01,hadoop02,hadoop03")hbaseConf.set("hbase.zookeeper.property.clientPort","2181")//指定读取的表名hbaseConf.set(TableInputFormat.INPUT_TABLE,"webtable")val scan=new Scan()scan.withStartRow(startTime.toString().getBytes)scan.withStopRow(endTime.toString().getBytes)//org.apache.hadoop.hbase.filter.RowFilterval filter=new RowFilter(CompareOp.EQUAL,new RegexStringComparator(regex))//绑定过滤器使其生效,即在做范围查询时结合行键正则过滤器来返回对应的结果scan.setFilter(filter)//设置scan对象,使其生效hbaseConf.set(TableInputFormat.SCAN,Base64.encodeBase64String(ProtobufUtil.toScan(scan).toByteArray()))//执行读取,将结果返回到结果集RDD中val resultRDD=sc.newAPIHadoopRDD(hbaseConf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[org.apache.hadoop.hbase.client.Result])//QueryByRangeAndRegex方法:返回结果集RDDresultRDD}/*将封装好的logbean数据存到指定的HBase中*/def saveToHBase(sc: SparkContext, logBean: LogBean) = {sc.hadoopConfiguration.set("hbase.zookeeper.quorum","hadoop01,hadoop02,hadoop03")sc.hadoopConfiguration.set("hbase.zookeeper.property.clientPort","2181")sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE,"webtable")val job = new Job(sc.hadoopConfiguration)job.setOutputKeyClass(classOf[ImmutableBytesWritable])job.setOutputValueClass(classOf[Result])job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])val rdd=sc.parallelize(List(logBean))val hbaseRDD=rdd.map{bean=>//本项目的行键设计为:sstime_uvid_ssid_cip_随机数字//行键以时间戳开头,作用:让HBase按时间戳做升序排序,便于后续按时间段范围查询//行键中还包含uvid,ssid,cip信息。便于统计处相关业务指标,比如uv,vv等//随机数字满足散列原则val rowKey=bean.sstime+"_"+bean.uvid+"_"+bean.ssid+"_"+bean.cip+"_"+Random.nextInt(100)//创建一个HBase行对象并指定行键val row=new Put(rowKey.getBytes)row.addColumn("cf1".getBytes,"url".getBytes,bean.url.getBytes)row.addColumn("cf1".getBytes,"urlname".getBytes,bean.urlname.getBytes)row.addColumn("cf1".getBytes,"uvid".getBytes,bean.uvid.getBytes)row.addColumn("cf1".getBytes,"ssid".getBytes,bean.ssid.getBytes)row.addColumn("cf1".getBytes,"sscount".getBytes,bean.sscount.getBytes)row.addColumn("cf1".getBytes,"sstime".getBytes,bean.sstime.getBytes)row.addColumn("cf1".getBytes,"cip".getBytes,bean.cip.getBytes)(new ImmutableBytesWritable,row)}//执行写出hbaseRDD.saveAsNewAPIHadoopDataset(job.getConfiguration)}}dao-MysqlUtil
package cn.yang.daoimport cn.yang.TongjiBean import com.mchange.v2.c3p0.ComboPooledDataSourceimport java.sql.{Connection, PreparedStatement, ResultSet} import java.text.SimpleDateFormatobject MysqlUtil {val c3p0=new ComboPooledDataSource()def saveToMysql(tongjiBean: TongjiBean) = {var conn:Connection=nullvar ps1:PreparedStatement=nullvar rs:ResultSet=nullvar ps2:PreparedStatement=nullvar ps3:PreparedStatement=nulltry{conn=c3p0.getConnection/*处理逻辑:1、查询mysql的tongji2表当天的数据2、如果当天还没有数据,则做新增插入如果当天已有数据,则作更新累加*///解析出当天的日期。格式如:2022-04-24val sdf=new SimpleDateFormat("YYYY-MM-dd")val todayTime=sdf.format(tongjiBean.sstime.toLong)//先查询tongji2表。如果当天已经有数据了,则更新累加//如果当天还没有数据,则新增插入ps1=conn.prepareStatement("select * from tongji2 where reporttime=?")ps1.setString(1,todayTime)//执行查询并返回结果集rs=ps1.executeQuery()if(rs.next()){//当天已经有数据,则做更新累积ps2=conn.prepareStatement("update tongji2 set pv=pv+?,uv=uv+?,vv=vv+?,newip=newip+?,newcust=newcust+? where reporttime=?")ps2.setInt(1, tongjiBean.pv)ps2.setInt(2, tongjiBean.uv)ps2.setInt(3, tongjiBean.vv)ps2.setInt(4, tongjiBean.newip)ps2.setInt(5, tongjiBean.newcust)ps2.setString(6, todayTime)ps2.executeUpdate()}else{//则表示当天还没有数据,则新增插入ps3=conn.prepareStatement("insert into tongji2 values(?,?,?,?,?,?)")ps3.setString(1, todayTime)ps3.setInt(2, tongjiBean.pv)ps3.setInt(3, tongjiBean.uv)ps3.setInt(4, tongjiBean.vv)ps3.setInt(5, tongjiBean.newip)ps3.setInt(6, tongjiBean.newcust)ps3.executeUpdate()}}catch {case t:Exception=>{t.printStackTrace()}}finally {if(ps3!=null)ps3.closeif(ps2!=null)ps2.closeif(rs!=null)rs.closeif(ps1!=null)ps1.closeif(conn!=null)conn.close}}}pojo-LogBean
package cn.yang.pojocase class LogBean(url:String,urlname:String,uvid:String,ssid:String,sscount:String,sstime:String,cip:String)TongjiBean
package cn.yangcase class TongjiBean(sstime:String,pv:Int,uv:Int,vv:Int,newip:Int,newcust:Int)③、启动SparkStreaming
④、启动tomcat,访问埋点服务器,测试SparkStreaming是否能够收到数据
⑤、启动HBase
cd /home/software/hbase-2.4.2/bin/
sh start-hbase.sh
sh hbase shell
建表:create 'webtable','cf1'
⑥、我们启动tomcat,启动Driver测试,然后扫描表webtable
发现有数据了:
⑦、进入mysql,在weblog库下新建表
create table tongji2(reporttime date,pv int,uv int,vv int,newip int,newcust int);
⑧、执行我们的程序,访问埋点,最后到mysql查看数据,这也是我们本项目实现的最终结果,结果内容存储到mysql数据库中




