网站模板下宝鸡seo培训
李宏毅-深度强化学习-入门笔记:PPO
- 一、Policy Gradient
- (一)基本元素
- (二)Policy of Actor
- (三)Actor, Environment, Reward
- 1. 轨迹 τ \tau τ 的概率
- 2. 计算总的 reward 的期望
- 3. Policy Gradient
- 4. Tip
- 二、On-policy 到 Off-policy
- (一)On-policy VS Off-policy
- (二)On-policy → Off-policy
- 三、增加 constraint:PPO / TRPO
- 1. 如果 p θ p_\theta pθ 跟 p θ ′ p'_\theta pθ′ 相差太多,importance sampling 的结果会不好时,可用 PPO 解决。
- 2. PPO vs TRPO
- 3. PPO 算法
- 4. PPO2 算法
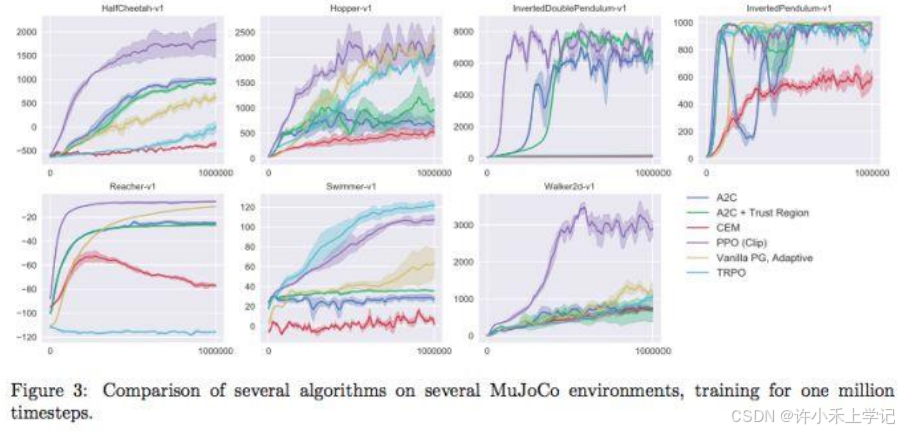
- 5. PPO 效果
网课链接:https://www.bilibili.com/video/BV1XP4y1d7Bk/?p=4
一、Policy Gradient
(一)基本元素
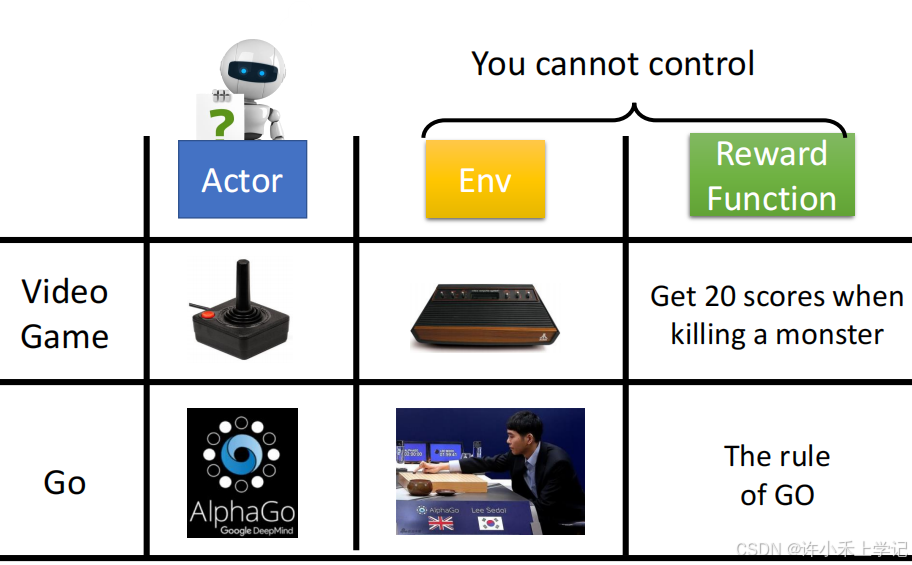
(二)Policy of Actor
1. Policy π \pi π 是带有参数 θ \theta θ 的 network
输入:表示机器观测的一个向量或矩阵
输出:在输出层与动作相关的神经元
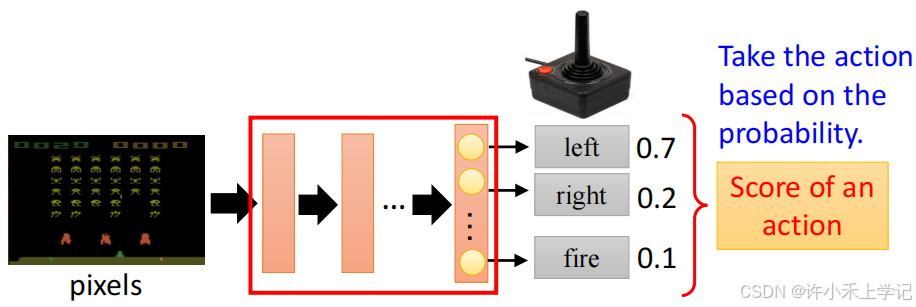
2. 例子:运行流程
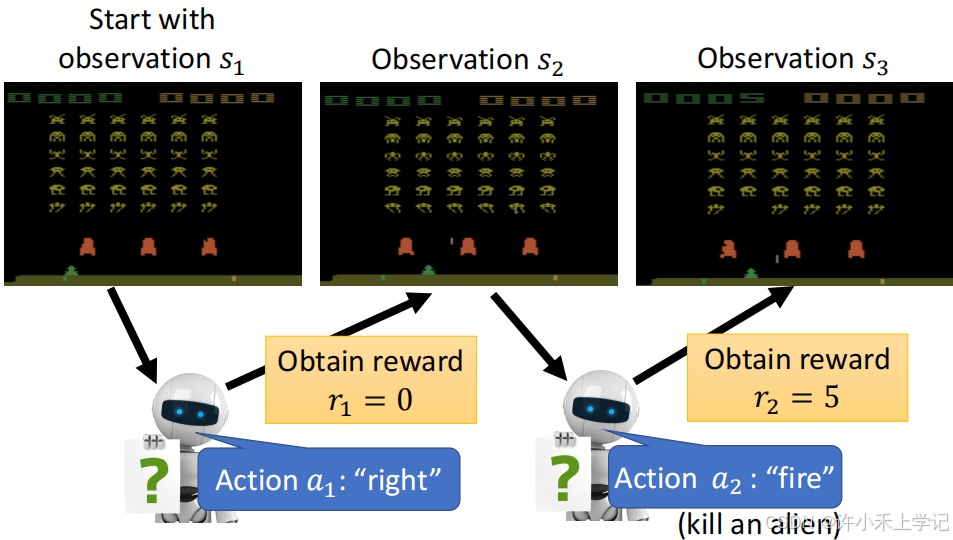
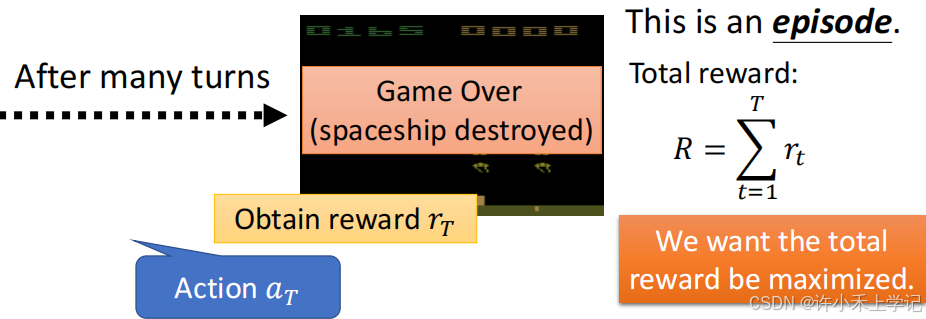
(三)Actor, Environment, Reward
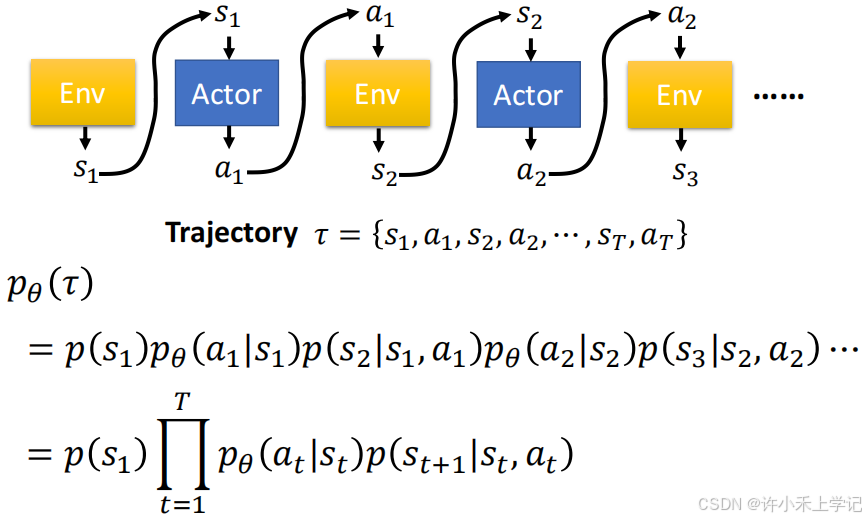
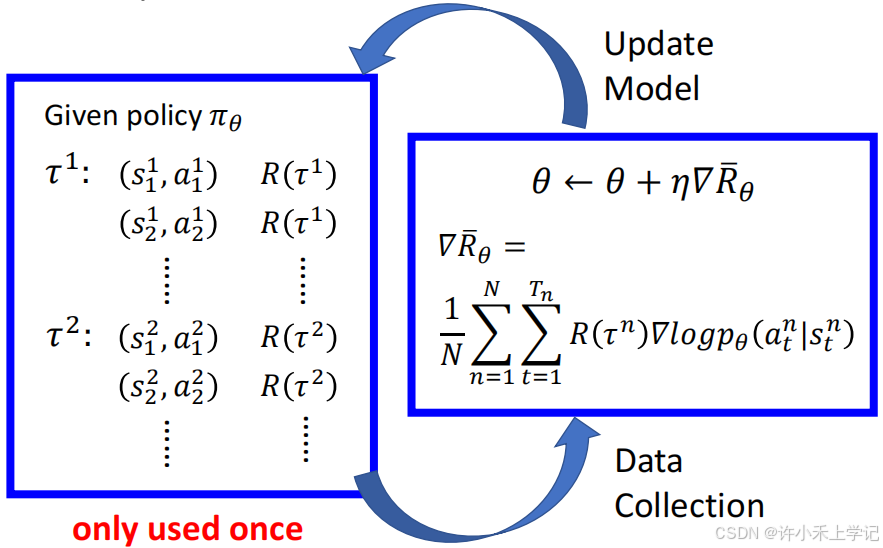
1. 轨迹 τ \tau τ 的概率
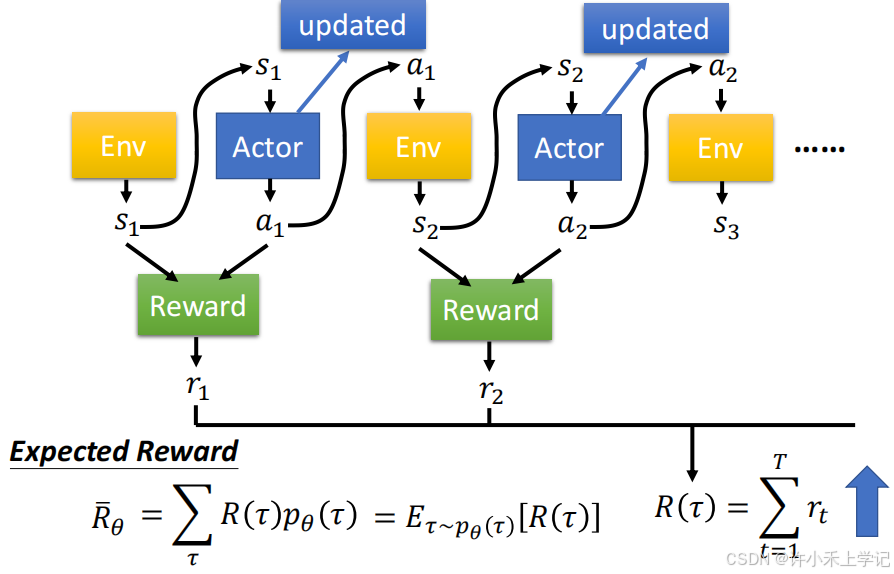
2. 计算总的 reward 的期望
3. Policy Gradient
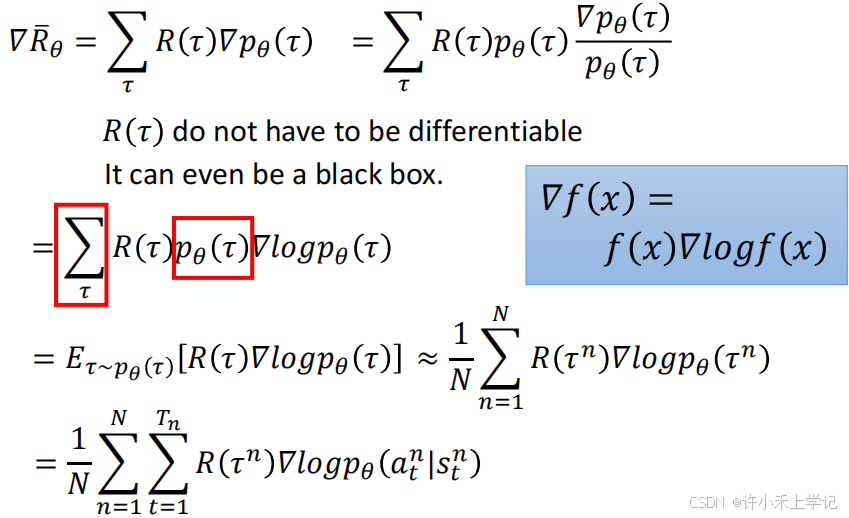
4. Tip
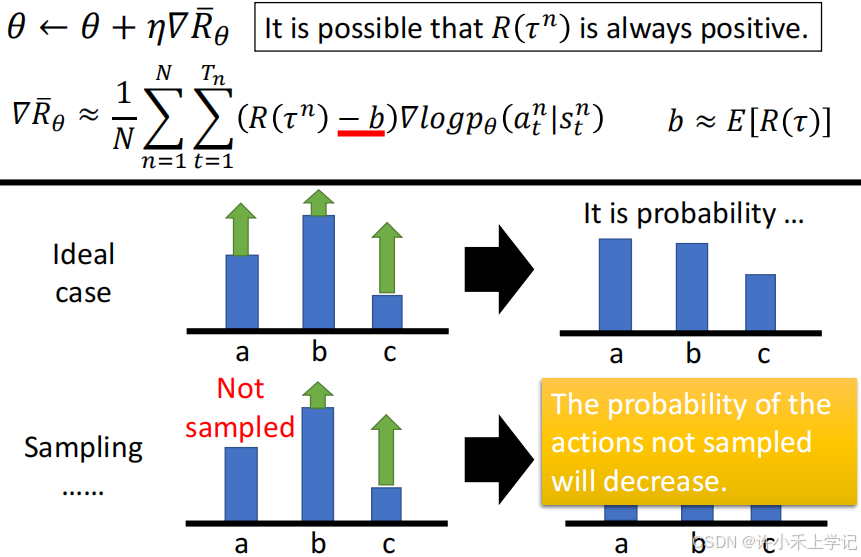
Tip 1:add a baseline
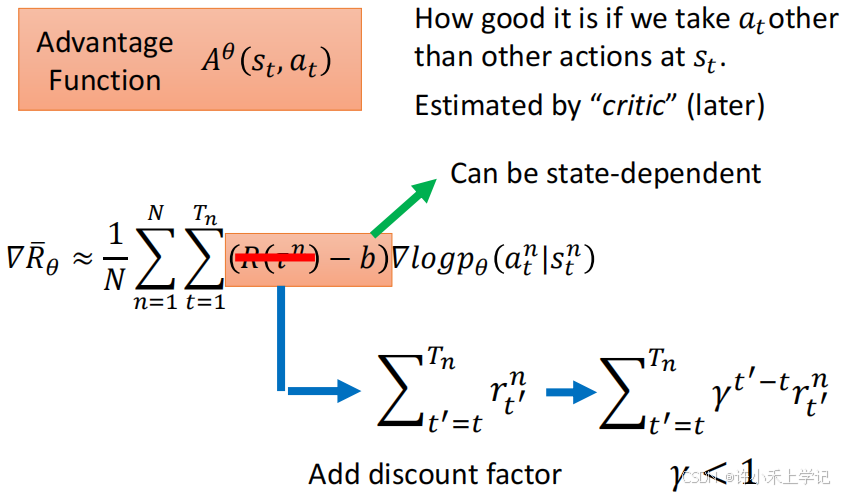
Tip 2:Assign suitable credit
二、On-policy 到 Off-policy
(一)On-policy VS Off-policy
on-policy:跟环境互动的 agent 跟要学习的 agent 是同一个
off-policy:跟环境互动的 agent 跟要学习的 agent 不是同一个
(二)On-policy → Off-policy
如果想要在 p 做互动,但又不能跟 p 做互动,可以把 p 换成 q 进行实验。


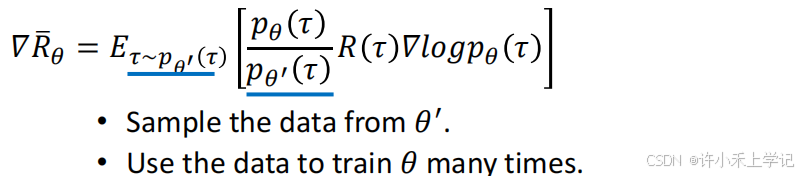

三、增加 constraint:PPO / TRPO
1. 如果 p θ p_\theta pθ 跟 p θ ′ p'_\theta pθ′ 相差太多,importance sampling 的结果会不好时,可用 PPO 解决。
2. PPO vs TRPO
PPO 的前身是 TRPO,二者不同之处在于 K L ( θ , θ ′ ) KL(\theta, \theta') KL(θ,θ′)。

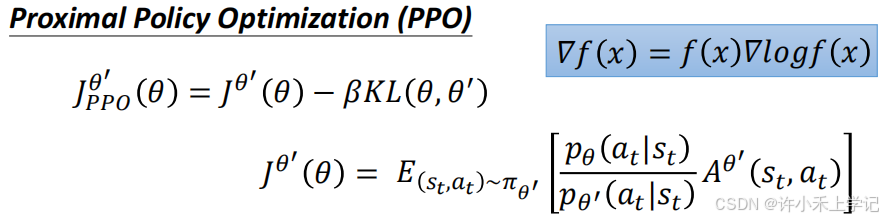
K L ( θ , θ ′ ) KL(\theta, \theta') KL(θ,θ′) 衡量 θ \theta θ 跟 θ ′ \theta' θ′ 有多像,一般时越像越好的。
PPO 和 TRPO 结果看着似乎差不多,但在实践中,PPO 比 TRPO 容易得多。
3. PPO 算法
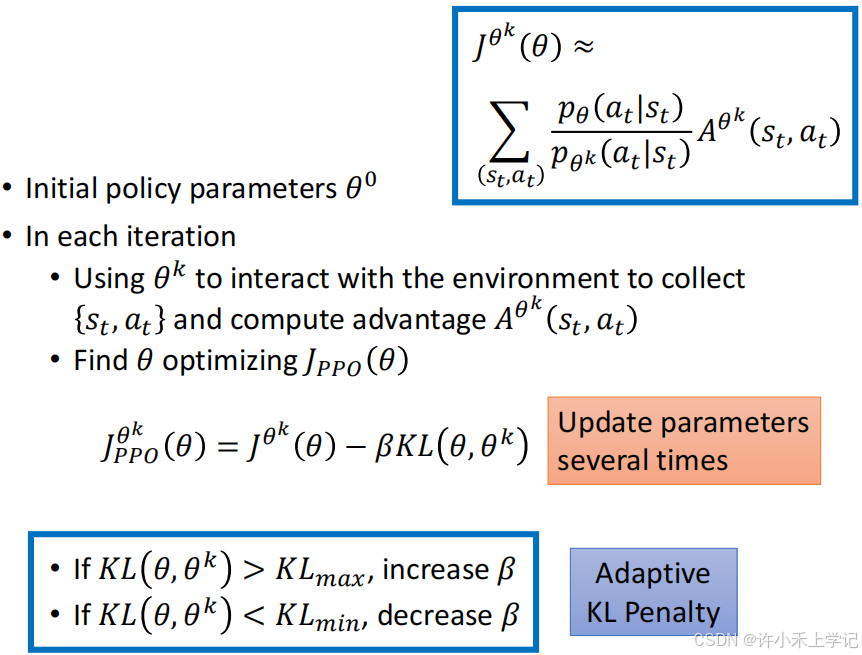
原论文代码:

4. PPO2 算法
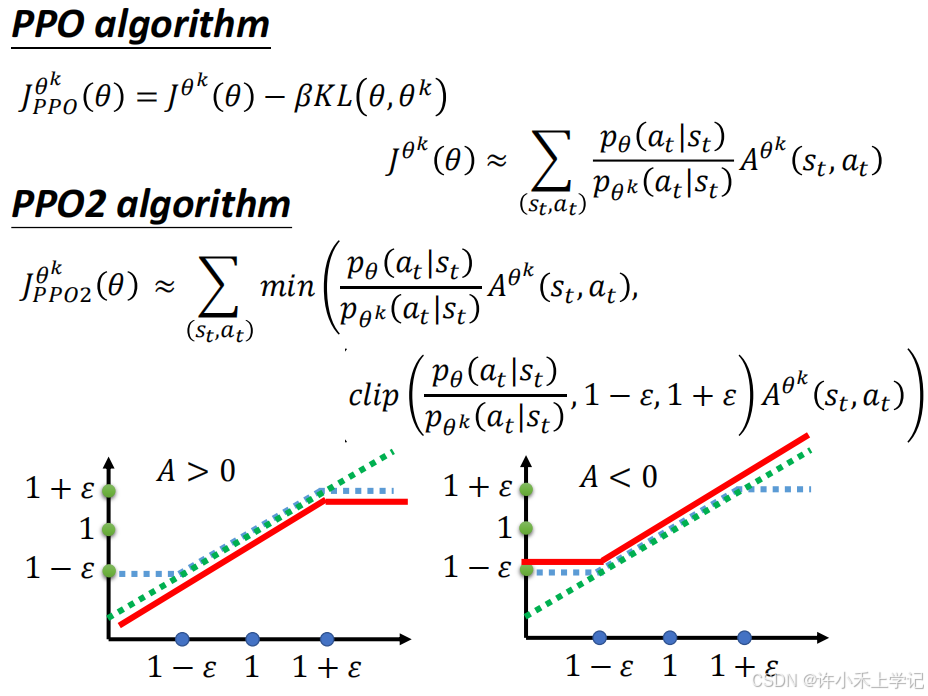
当 A<B 时,cilp(A,B,C) = B
当 A>C 时,cilp(A,B,C) = C
PPO2 算法目的: p θ p^{\theta} pθ 跟 p θ ′ p^{\theta'} pθ′ 在优化后不要差距太大
5. PPO 效果