医院网站建设技术方案免费产品推广网站
1. 问题
如果是采用hdfs上传加载的表、或者是flume直接写hdfs的表空间通常看hive的属性是不准确的。
2. 思路
为了使结果更精确,我们直接使用linux下命令统计hive仓库目录下的每个表对应的文件夹目录占用空间的大小。
3. 解决方法
这里建立三层表结构
ods: 原始数据采集
ods.ods_hive_tablelist
ods.ods_hive_tablespace
dw:清洗整合
dw.dw_hive_metadata
mdl: 统计
mdl.mdl_hive_metadata_stat
3.1 ODS层数据采集
在ods层建立文件路径列表和每个路径占用空间大小。
create table ods.ods_hive_tablelist(
path string comment '表路径',
update_time string comment '更新时间'
) comment 'hive表更新时间'
partitioned by (pk_day string)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;create table ods.ods_hive_tablespace(
path string comment '表路径',
size string comment '表占用大小(byte)',
blocksize string comment '副本占用大小(byte)'
) comment 'hive表空间占用统计'
partitioned by (pk_day string)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
这里的数据采集使用shell命令格式,我是使用pySpark里面直接执行的。
tableList = os.popen("""hdfs dfs -ls /user/hive/warehouse/*.db |awk '{print $8","$6" "$7}'""")
tablespaceList = os.popen("""hadoop fs -du /user/hive/warehouse/*.db|awk '{print $3","$1","$2}'""")new_tableList = []
for table in tableList:arr = table.replace('\n','').split(",")new_tableList.append((arr[0],arr[1]))new_tablespaceList = []
for tablespace in tablespaceList:arr = tablespace.replace('\n','').split(",")new_tablespaceList.append((arr[0],arr[1],arr[2]))#----ods----
current_dt = date.today().strftime("%Y-%m-%d")
print(current_dt)
spark.createDataFrame(new_tableList,['path','update_time']).registerTempTable('tablelist')
spark.createDataFrame(new_tablespaceList,['path','size','blocksize']).registerTempTable('tablespacelist')
tablelistdf = spark.sql('''(select path,update_time,current_date() as pk_day from tablelist where path != '') ''')
tablelistdf.show(10)tablelistdf.repartition(2).write.insertInto('ods.ods_hive_tablelist',True)tablespacelistdf = spark.sql('''(select path,size,blocksize,current_date() as pk_day from tablespacelist where path != '')''')
tablespacelistdf.show(10)
tablespacelistdf.repartition(2).write.insertInto('ods.ods_hive_tablespace',True)
经过简单的清洗后,落表。
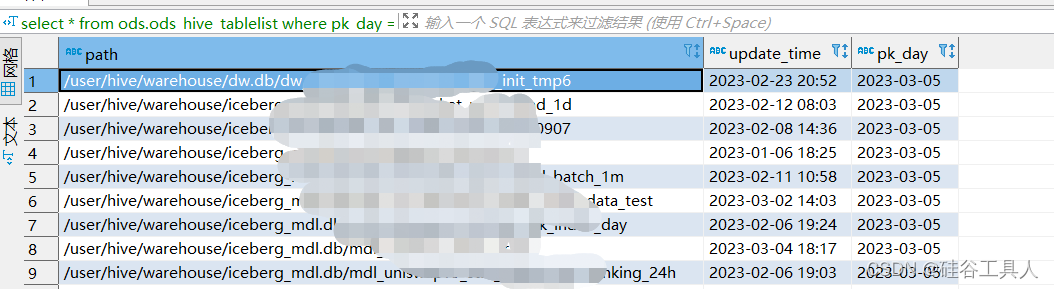
ods.ods_hive_tablelist表的显示如下:
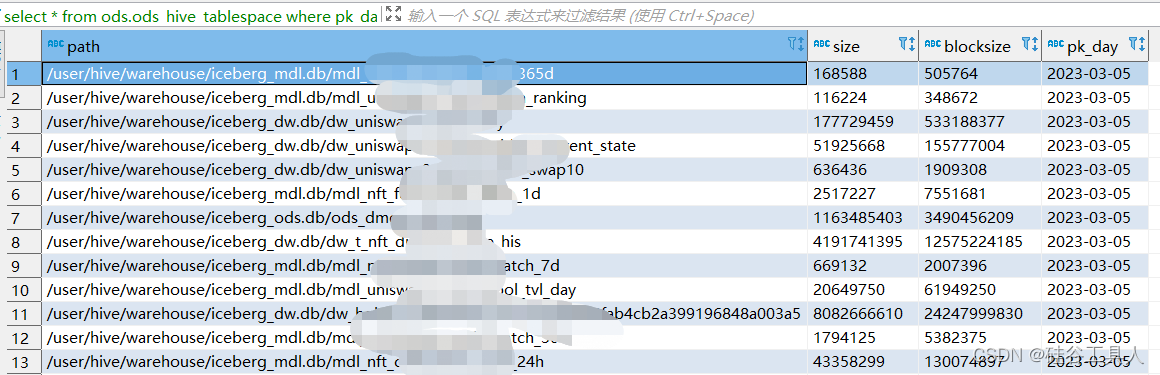
在ods.ods_hive_tablespace中显示的如下
3.2 清洗整合入仓
接下来在dw层进行整合,对应的表结构如下:
create table dw.dw_hive_metadata(
dbname string comment '数据库名',
tblname string comment '表名',
path string comment '表路径',
update_date string comment '更新日期',
update_time string comment '更新时间',
mb double comment '表占用大小(MB)',
gb double comment '表占用大小(GB)',
size double comment '表占用大小(byte)',
blocksize double comment '副本占用大小(byte)',
blocksize_gb double comment '副本占用大小(gb)'
) comment 'hive表元数据统计'
partitioned by (pk_day string)
stored as textfile;
这里整合ods层的两张表关联,就可以拼接出每个表占用的空间大小:
#----dw----
dwdf = spark.sql('''(
selectsplit(a.path,'/')[4] as dbname,split(a.path,'/')[5] as tblname,a.path,substr(a.update_time,1,10) as update_date,a.update_time,nvl(round(b.size/1000/1000,2),0) as mb,nvl(round(b.size/1000/1000/1000,2),0) as gb,nvl(round(b.size,2),0) as size,nvl(round(b.blockSize,2),0) as blocksize,nvl(round(b.blockSize/1000/1000/1000,2),0) as blocksize_gb,a.pk_day
from(select * from ods.ods_hive_tablelist where pk_day = current_date()) aleft join(select * from ods.ods_hive_tablespace where pk_day = current_date()) b
on a.path = b.path and a.pk_day = b.pk_day
where a.path is not null
and a.path != ''
)''')
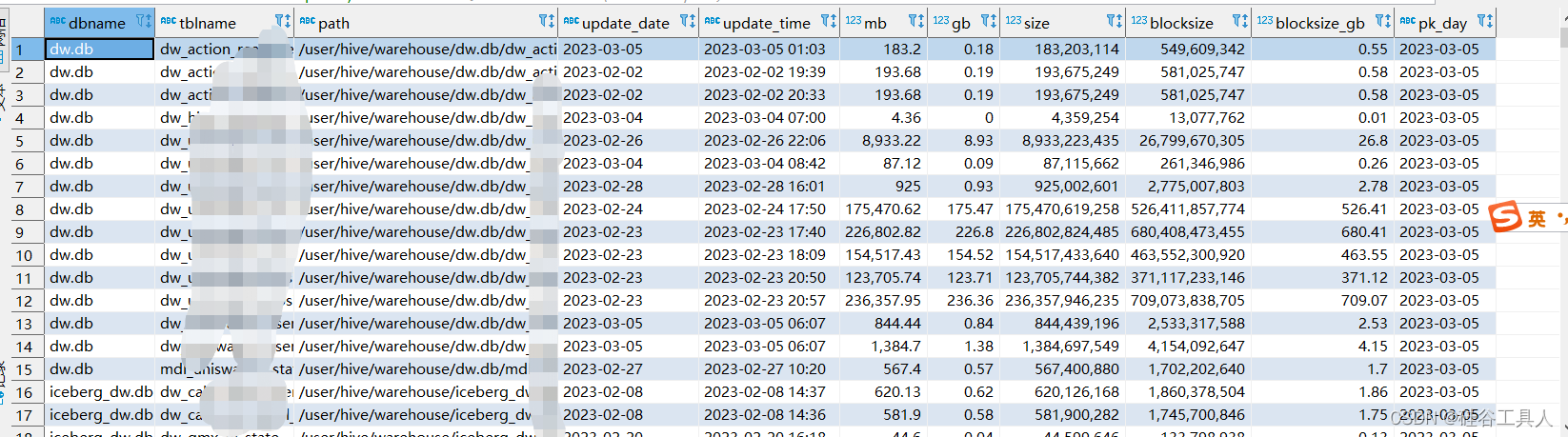
我们可以看到这个明细数据展示如下:
3.3 统计分析
这里可以根据需要自己增加统计逻辑,我这里按照db层级统计每天的增量大小。
统计层表结构如下:
create table mdl.mdl_hive_metadata_stat(
dbname string comment '数据库名',
tblcount int comment '表个数',
dbspace double comment '数据库空间(GB)',
dbspace_incr double comment '数据库空间日增量(GB)',
blockspace_incr double comment '服务器空间日增量(GB)'
) comment 'hive元数据db统计'
partitioned by (pk_day string)
stored as textfile;
实现方式:
#----mdl----
spark.sql('''(select pk_day,dbname,count(tblname) as tblCount,round(sum(gb),2) as dbspace,round(sum(blocksize_gb),2) as blockSpacefrom dw.dw_hive_metadatawhere pk_day>= date_sub(current_date(),7)group by pk_day,dbname)''').createTempView('tmp_a')spark.sql('''(selectpk_day,dbname,tblCount,dbspace,blockSpace,lag(dbspace,1,0) over(partition by dbname order by pk_day) as lagSpace,lag(blockSpace,1,0) over(partition by dbname order by pk_day) as lagBlockSpacefrom tmp_a
)''').createTempView('tmp_b')mdldf = spark.sql('''(
select dbname,tblCount,dbspace,
round((dbspace-lagSpace),2) as dbspace_incr,
round((blockSpace-lagBlockSpace),2) as blockspace_incr,
pk_day
from tmp_b where pk_day = current_date()
)''')
mdldf.show(10)
mdldf.repartition(1).write.insertInto('mdl.mdl_hive_metadata_stat',True)
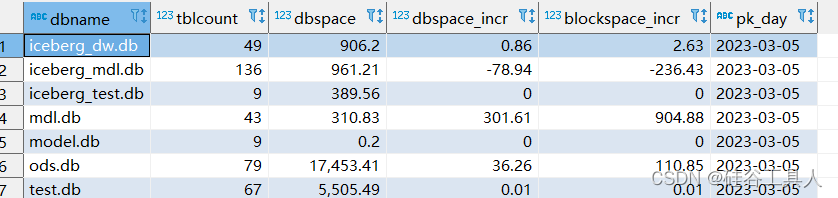
最后看看,统计层的内容如下: