站长之家 网站模板上海优化seo排名
目录
- 简介
- 什么是JDBC
- 如何使用JDBC
- 1、获取连接
- 2、操作数据
- 3、关闭连接,释放资源
- 使用技巧
- 查询操作
- 创建表,插入模拟数据
- 使用Java查询数据的数据
- SQL注入问题
- 使用PreparedStatement查询
- 更新操作
- 插入
- 插入并获取主键
- 更新
- 删除
- JDBC事务
- JDBC的批量操作
- JDBC连接池
简介
什么是JDBC
JDBC是Java DataBase Connectivity的缩写。它是让Java程序连接数据的接口。
Java程序要连接数据库,必然是需要通过网络连接,和数据库商制定协议来实现连接的。所以Java推出了JDBC这一套连接数据库的空接口,然后不同的数据库厂商来根据JDBC来实现连接自己数据库的驱动。
对于Java来说连接数据库只需要操作JDBC接口即可,需要连接哪个厂商的数据库就导入哪个厂商的驱动程序。
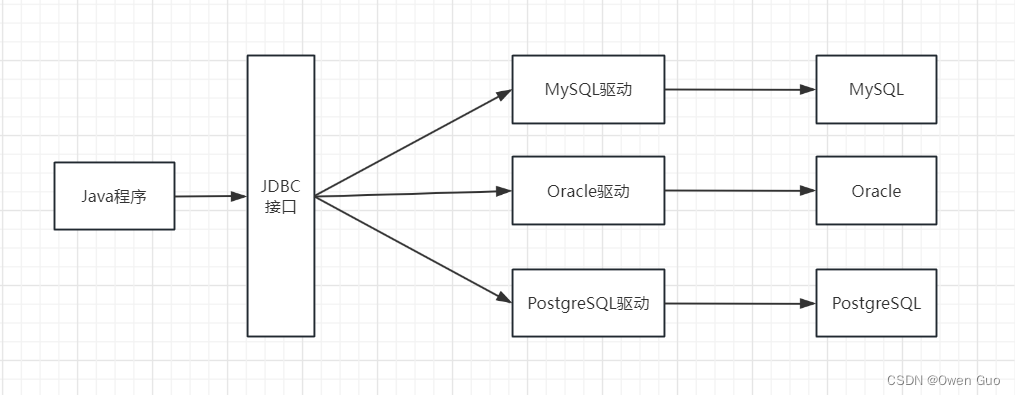
看上面这个图并且拿MySQL来举例,Java程序如何连接MySQL数据库,并且如何操作MySQL是通过MySQL数据库的厂商自己开发的MySQL驱动来实现的,并且是依赖Java提供的JDBC标准来实现的。所以Java程序想要操作数据库,只需要导入MySQL驱动,然后调用JDBC接口即可实现。
如何使用JDBC
整体的流程为:1、获取连接;2、访问数据库;3、关闭连接;
1、获取连接
1)连接是什么呢?
在Java中连接是Connection,相当于Java程序和数据库的TCP连接,通过Connection就可以操作数据库了。
2)如何获得呢?
Connection conn = DriverManager.getConnection("连接数据库的URL", "用户名", "密码”);
通过DriverManager.getConnection()来获取一个连接
连接数据库的URL
URL是各个数据库厂商指定的连接格式,例如MySQL是:jdbc:mysql://<hostname>:<port>/<db>?key1=value1&key2=value2<hostname>是ip地址
<port>是端口
<db>是数据库名
key1和key2是连接的参数,可以有很多个
如下这个连接就是连接到本机MySQL的test数据库
jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8
2、操作数据
获取到JDBC连接后,就可以操作数据库了。
1)通过Connection提供的createStatement()来获取一个Statement对象,
Statement stmt = conn.createStatement()
注意:Statement也是系统资源,使用完成需要释放
2)通过Statement对象就可以执行SELECT,UPDATE等操作了
可以通过Statement对象的prepareStatement来执行SQL
更多详细数据库操作将在后面演示
3、关闭连接,释放资源
上面获取到的Connection和Statement都是系统资源,使用完后一定要及时释放,否则会导致系统资源耗尽,其他程序无法使用。
可以执行它们的close()方法来释放资源,并且要先释放Statement再释放Connection。例如:
// 获取连接
Connection conn = ...
// 获取Statement
Statement stmt = conn.createStatement();// 释放Statement
stms.close();
// 释放连接
conn.close();
还有一个在执行查询语句时会返回ResultSet对象,ResultSet也是系统资源,使用完成后要释放
使用技巧
可以直接将获取资源的代码写到try括号内try(”获取资源"),这样就不需要显示的指定释放资源了,会自动释放。
try (Connection conn = DriverManager.getConnection("连接数据库的URL", "用户名", "密码”)) {try (Statement stmt = conn.createStatement()) {try (ResultSet rs = stmt.executeQuery("SELECT ...")) {}}
} catch (SQLException e) {throw new RuntimeException(e);
}
查询操作
创建表,插入模拟数据
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for users
-- ----------------------------
DROP TABLE IF EXISTS `users`;
CREATE TABLE `users` (`id` int(0) NOT NULL AUTO_INCREMENT,`username` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '',`email` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '',`gender` int(0) DEFAULT NULL,`birthdate` date DEFAULT NULL,`country` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`created_at` timestamp(0) DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 11 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of users
-- ----------------------------
INSERT INTO `users` VALUES (1, 'user1', 'user1@example.com', 1, '1990-01-15', 'USA', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (2, 'user2', 'user2@example.com', 2, '1985-05-20', 'Canada', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (3, 'user3', 'user3@example.com', 1, '1998-09-10', 'Australia', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (4, 'user4', 'user4@example.com', 1, '1982-03-02', 'UK', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (5, 'user5', 'user5@example.com', 3, '1995-11-12', 'Germany', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (6, 'user6', 'user6@example.com', 1, '2000-07-25', 'France', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (7, 'user7', 'user7@example.com', 2, '1993-04-08', 'Spain', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (8, 'user8', 'user8@example.com', 0, '1989-08-30', 'Italy', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (9, 'user9', 'user9@example.com', 0, '1987-12-18', 'Japan', '2023-08-12 16:59:57');
INSERT INTO `users` VALUES (10, 'user10', 'user10@example.com', 2, '2002-02-05', 'China', '2023-08-12 16:59:57');SET FOREIGN_KEY_CHECKS = 1;
使用Java查询数据的数据
我们来直接上代码:
public class SelectDemo { public static void main(String[] args) {// JDBC连接的URL, 不同数据库有不同的格式:String JDBC_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8";String JDBC_USER = "root";String JDBC_PASSWORD = "123456";// 获取连接try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {// 获取Statementtry (Statement stmt = conn.createStatement()) {// 执行查询SQL,返回ResultSet对象try (ResultSet rs = stmt.executeQuery("SELECT id,username, email, gender, country FROM users WHERE id=1")) {// 遍历结果集while (rs.next()) {long id = rs.getLong(1);String username = rs.getString(2); // 注意:索引从1开始String email = rs.getString(3);int gender = rs.getInt(4);String country = rs.getString(5);System.out.println("id=" + id + ", username=" + username + ", email=" + email + ", gender=" + gender + ", country=" + country);}}}} catch (SQLException e) {throw new RuntimeException(e);}}
}
看到这个代码,大家应该就一部了然了,下面我们再来讲解一下关键代码
1)、通过执行Statement对象的executeQuery方法来执行SQL,返回了ResultSet对象
2)、ResultSet对象就是此次查询的结果集,可以使用while循环来遍历结果集
3)、通过rs.next()来判断是否还有下一行记录,没有记录则返回false推出循环,如果有则移动到下一行记录
4)、通过getLong、getString和getInt等方法来获取返回结果,参数是列的索引,从1开始
必须根据SELECT的列的对应位置来调用getLong(1),getString(2)这些方法,否则对应位置的数据类型不对,将报错。
SQL注入问题
上面是通过stms.executeQuery()执行SQL查询的,这个SQL是如果要加参数是通过拼接的方式形成最终的SQL来执行的。
我们来假设一个例子,一个用户要登录,需要通过查询语句来判断用户是否存在:
User login(String name, String pass) {...stmt.executeQuery("SELECT * FROM user WHERE login=" + name + " AND pass=" + pass);...
}
这里name和pass传的是正常值Tom和123456,那么执行的SQL就是:
SELECT * FROM user WHERE login='Tom' AND pass='123456'
看起来好像没有什么问题,但是如果用户传的是Tom OR 1=1 #和123456呢?执行的SQL就是:
SELECT * FROM user WHERE login='bob' OR 1=1 # ADN pass='123456'
这条语句有1=1,#将后面的SQL失效了,是不是你写的sql是什么都能查询成功了。这就是SQL注入。
那么如何解决SQL注入的问题呢?
最简单的方式就是不要使用SQL拼接的这种方式来操作数据库,使用PreparedStatement来操作数据库。
使用PreparedStatement查询
PreparedStatement是写一个SQL,然后用?作为占位符,然后对占位符传入不同的数据来执行的。
public class SelectDemo {public static void main(String[] args) {// JDBC连接的URL, 不同数据库有不同的格式:// JDBC连接的URL, 不同数据库有不同的格式:String JDBC_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8";String JDBC_USER = "root";String JDBC_PASSWORD = "123456";try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {try (PreparedStatement ps = conn.prepareStatement("SELECT id,username, email, gender, country FROM users WHERE gender = ? AND country = ?")) {ps.setObject(1, 3); // 注意:索引从1开始ps.setObject(2, "Germany");try (ResultSet rs = ps.executeQuery()) {while (rs.next()) {// 这里可用索引的形式,也可以使用列名称的形式long id = rs.getLong("id");String username = rs.getString("username");String email = rs.getString("email");int gender = rs.getInt("gender");String country = rs.getString("country");System.out.println("id=" + id + ", username=" + username + ", email=" + email + ", gender=" + gender + ", country=" + country);}}}} catch (SQLException e) {throw new RuntimeException(e);}}
}
我们来讲解一下这个代码:
1)、首先SQL不是采用拼接的形式,而是传入参数的地方使用占位符?来写SQL
2)、使用ps.setObject(2, "Germany")来传入参数,第一个传索引,从1开始,第二个传真正的参数
3)、获取结果和之前的方式是一样的,不过多了一种可以通过列名称来获取的方式
PreparedStatement是如何避免SQL注入的
在使用PreparedStatement查询的情况下,数据库服务器不会将参数的内容视为 SQL 语句的一部分来进行处理,而是在数据库完成 SQL 语句的编译之后,才套用参数运行。因此就算参数中含有破坏性的指令,也不会被数据库所运行。
使用Java对数据库进行操作时,必须使用PreparedStatement,严禁任何通过参数拼字符串的代码!
更新操作
更新操作和查询不同的是:
更新操作使用executeUpdate()执行SQL,返回结果是int,表示改变的记录数量
查询操作使用executeQuery()执行SQL,返回结果是ResultSet
插入
public class InsertDemo {public static void main(String[] args) {// JDBC连接的URL, 不同数据库有不同的格式:String JDBC_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8";String JDBC_USER = "root";String JDBC_PASSWORD = "123456";try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {try (PreparedStatement ps = conn.prepareStatement("INSERT INTO users(username, email, gender) VALUES (?,?,?)")) {ps.setObject(1, "张三"); // 注意:索引从1开始ps.setObject(2, "zhangsan@qq.com");ps.setObject(3, 2);int n = ps.executeUpdate(); // 这里使用executeUpdate()}} catch (SQLException e) {throw new RuntimeException(e);}}
}
插入并获取主键
如果数据表设置了自增主键,那么如果在插入数据返回自增主键呢?而不是返回影响记录行数。
public class InsertDemo1 {public static void main(String[] args) {// JDBC连接的URL, 不同数据库有不同的格式:String JDBC_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8";String JDBC_USER = "root";String JDBC_PASSWORD = "123456";try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {// 第二个参数设置Statement.RETURN_GENERATED_KEYStry (PreparedStatement ps = conn.prepareStatement("INSERT INTO users(username, email, gender) VALUES (?,?,?)",Statement.RETURN_GENERATED_KEYS)) {ps.setObject(1, "李四"); // 注意:索引从1开始ps.setObject(2, "lisi@qq.com");ps.setObject(3, 2);int n = ps.executeUpdate(); // 这里依然返回的是影响记录行数// 要使用getGeneratedKeys()来获取ResultSet对象try (ResultSet rs = ps.getGeneratedKeys()) {// 从ResultSet对象来获取主键idif (rs.next()) {Long id = rs.getLong(1); // 注意:索引从1开始System.out.println(id);}}}} catch (SQLException e) {throw new RuntimeException(e);}}
}
我们来解释一下这个代码:
1)、主要是在执行prepareStatement()方法时第二个参数传递了Statement.RETURN_GENERATED_KEYS
2)、其他都是相同的,executeUpdate()返回的依然是影响记录行数
3)、使用getGeneratedKeys()来获取ResultSet对象,然后从ResultSet对象来获取主键id
4)、ResultSet也是资源,所以最后要释放资源
更新
更新操作和新增操作是一样的,把SQL换成UPDATE就可以了,返回结果是影响记录行数
public class UpdateDemo {public static void main(String[] args) {// JDBC连接的URL, 不同数据库有不同的格式:String JDBC_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8";String JDBC_USER = "root";String JDBC_PASSWORD = "123456";try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {try (PreparedStatement ps = conn.prepareStatement("UPDATE users SET username=? WHERE id=?")) {ps.setObject(1, "王五"); // 注意:索引从1开始ps.setObject(2, 15);int n = ps.executeUpdate(); // 返回更新的行数}} catch (SQLException e) {throw new RuntimeException(e);}}
}
删除
删除操作和新增、更新操作是一样的,把SQL换成DELETE就可以了,返回结果是影响记录行数
public class DeleteDemo {public static void main(String[] args) {// JDBC连接的URL, 不同数据库有不同的格式:String JDBC_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8";String JDBC_USER = "root";String JDBC_PASSWORD = "123456";try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {try (PreparedStatement ps = conn.prepareStatement("DELETE FROM users WHERE username=?")) {ps.setObject(1, "李四"); // 注意:索引从1开始int n = ps.executeUpdate(); // 返回更新的行数System.out.println(n);}} catch (SQLException e) {throw new RuntimeException(e);}}
}
JDBC事务
这里我们只演示JDBC是如何操作事务的。
public class TransactionDemo {public static void main(String[] args) throws SQLException {// JDBC连接的URL, 不同数据库有不同的格式:String JDBC_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8";String JDBC_USER = "root";String JDBC_PASSWORD = "123456";Connection conn = null;// 创建连接try {conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD);} catch (SQLException e) {throw new RuntimeException(e);}try {// 关闭事务自动提交conn.setAutoCommit(false);// 新增数据try (PreparedStatement ps = conn.prepareStatement("INSERT INTO users(username, email, gender) VALUES (?,?,?)")) {ps.setObject(1, "张三"); // 注意:索引从1开始ps.setObject(2, "zhangsan@qq.com");ps.setObject(3, 2);int n = ps.executeUpdate(); // 这里使用executeUpdate()}int a = 10 / 0;// 更新数据try (PreparedStatement ps = conn.prepareStatement("UPDATE users SET username=? WHERE id=?")) {ps.setObject(1, "王五"); // 注意:索引从1开始ps.setObject(2, 15);int n = ps.executeUpdate(); // 返回更新的行数}// 提交事务conn.commit();} catch (Exception e) {// 抛出异常回滚事务conn.rollback();throw new RuntimeException(e);} finally {// 恢复连接原来的状态conn.setAutoCommit(true);// 关闭连接conn.close();}}
}
我们来解释一下这里的代码:
1)、获取连接默认事务是自动提交的,即执行一条SQL立即就提交了
2)、所有要conn.setAutoCommit(false)关闭自动提交事务,只有在调用conn.commit()才能提交事务
3)、如果代码抛出了异常,则会在catch语句块中执行conn.rollback()回滚事务。
4)、最后在finally中通过conn.setAutoCommit(true)把连接恢复到初始状态,然后conn.close()关闭连接
如果要设定事务的隔离级别,可以使用如下代码:
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
JDBC的批量操作
如果一条一条的执行SQL,那么每一次操作都是一次网络请求,众所周知,网络请求是很慢的,所以如果要执行1000条SQL,那肯定不能说一条一条去执行。
测试发现:1000条SQL,一条一条执行需要1254ms,如果使用批处理,只需要345ms,整整快了3倍。
public class BatchDemo {public static void main(String[] args) {// JDBC连接的URL, 不同数据库有不同的格式:String JDBC_URL = "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8";String JDBC_USER = "root";String JDBC_PASSWORD = "123456";long start = System.currentTimeMillis();try (Connection conn = DriverManager.getConnection(JDBC_URL, JDBC_USER, JDBC_PASSWORD)) {conn.setAutoCommit(false);try (PreparedStatement ps = conn.prepareStatement("INSERT INTO users(username, email, gender) VALUES (?,?,?)")) {// 批量插入5条记录for (int i = 0; i < 1000; i++) {ps.setObject(1, "李四" + i);ps.setObject(2, "lisi" + i + "@qq.com");ps.setObject(3, 2);// 这里不再是执行SQL语句了,变成添加到batchps.addBatch();}// 执行所有SQLint[] ns = ps.executeBatch();// // 查看每个SQL的返回结果
// for (int n : ns) {
// System.out.println(n + " inserted.");
// }conn.commit();}long end = System.currentTimeMillis();System.out.println("time:" + (end - start));} catch (SQLException e) {throw new RuntimeException(e);}}
}
其实批处理和正常操作数据库是一样的,不过在传入参数后是执行ps.addBatch(),最后再使用ps.executeBatch()执行命令。
这种批操作有特别的优化,速度远远快于普通循环执行SQL。
JDBC连接池
在执行JDBC的增删改的操作时,如果每一次操作都来一次打开连接,操作,关闭连接的动作,那么可以想象到创建和销毁JDBC连接的开销有多大。为了避免频繁的创建和销毁JDBC连接,我们可以通过连接池(Connection Pool)复用已经创建好的连接。

JDBC连接池有一个标准的接口javax.sql.DataSource,注意这个类位于Java标准库中,但仅仅是接口。要使用JDBC连接池,我们必须选择一个JDBC连接池的实现。常用的JDBC连接池有:
- HikariCP
- C3P0
- BoneCP
- Druid
Druid连接池—目前最热门的连接池,由阿里巴巴开发,所以下面我们用Druid来演示:
先导入Druid依赖
<!-- druid -->
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.0.9</version>
</dependency>
然后添加配置信息
Properties properties = new Properties();properties.setProperty("driverClassName", "com.mysql.cj.jdbc.Driver");
properties.setProperty("url", "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8");
properties.setProperty("username", "root");
properties.setProperty("password", "123456");
properties.setProperty("initialSize", "5"); // 初始化连接数量
properties.setProperty("maxActive", "10"); // 最大连接数量
properties.setProperty("maxWait", "3000"); // 连接最大超时时间
然后就可以创建连接池,正常使用了
public class DruidDemo {public static void main(String[] args) {Properties properties = new Properties();properties.setProperty("driverClassName", "com.mysql.cj.jdbc.Driver");properties.setProperty("url", "jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8");properties.setProperty("username", "root");properties.setProperty("password", "521125");properties.setProperty("initialSize", "5"); // 初始化连接数量properties.setProperty("maxActive", "10"); // 最大连接数量properties.setProperty("maxWait", "3000"); // 连接最大超时时间try {// 创建连接池DataSource dataSe = DruidDataSourceFactory.createDataSource(properties);// 从连接池获取连接Connection conn = dataSe.getConnection();// 执行SQLtry (PreparedStatement ps = conn.prepareStatement("INSERT INTO users(username, email, gender) VALUES (?,?,?)")) {ps.setObject(1, "张三"); // 注意:索引从1开始ps.setObject(2, "zhangsan@qq.com");ps.setObject(3, 2);int n = ps.executeUpdate(); // 这里使用executeUpdate()}// 释放连接,这里是把连接返回连接池conn.close();} catch (Exception e) {throw new RuntimeException(e);}}
}
1)、连接池内部维护了若干个Connection实例,如果调用dataSe .getConnection(),就选择一个空闲连接,并标记它为【正在使用】然后返回
2)、对Connection调用close(),那么就把连接再次标记为【空闲】从而等待下次调用