网站更换空间对优化的影响5118数据分析平台官网
以马蜂窝“普达措国家公园”为例,其评论高达3000多条,但这3000多条并非是完全向用户展示的,向用户展示的只有5页,数了一下每页15条评论,也就是75条评论,有点太少了吧!

因此想了个办法尽可能多爬取一些评论,根据我对爬虫爬取数据法律法规的相关了解,爬取看得到的数据是合法的,而在评论最开始的这个地方有对评论的分类,当然每个分类主题也是最多能看到5页内容,但是肯定会比我们被动的只爬取5页多很多内容,因此我们选择按主题分类去爬取评论。

点击上图中的全部,右键检查或者按下F12去定位“全部”

把这个元素收起来就可以看到如下图,这个<li></li>标签的列表里保存着分类名称、类型、id等,如果比较多的话可以利用selenium的XPATH自动获取之后,再套进代码里面,由于我只演示一个例子并且分类标签也不多,我就直接拿了这个列表放在代码里。

注意我们需要用到的是他的两个属性值:
data-type、data-catagory我存放的方式:(代码标注的分类id)
data-type:a = [0,0,1,1,1,2,2,2,2,2,0]
data-catagory:b = [0,2,13,12,11,134700810,173942219,112047583,112968615,143853527,1]注意这个顺序a[i]与b[i]是按照图中框起来的<li></li>标签一一对应的,顺序不能错。
点击Network,按下Ctrl+R刷新一下

找到Name为poiCommentListApi?为首的(如下图),点击Headers,红线画出来的内容是代码中comment_url(代码标注①的地方),根据你自己需要的进行替换。
 下滑可以看到Request Headers中的‘Referer’和‘User-agent’两个参数,根据你自己所需要的进行替换(代码标注的②和③)
下滑可以看到Request Headers中的‘Referer’和‘User-agent’两个参数,根据你自己所需要的进行替换(代码标注的②和③)
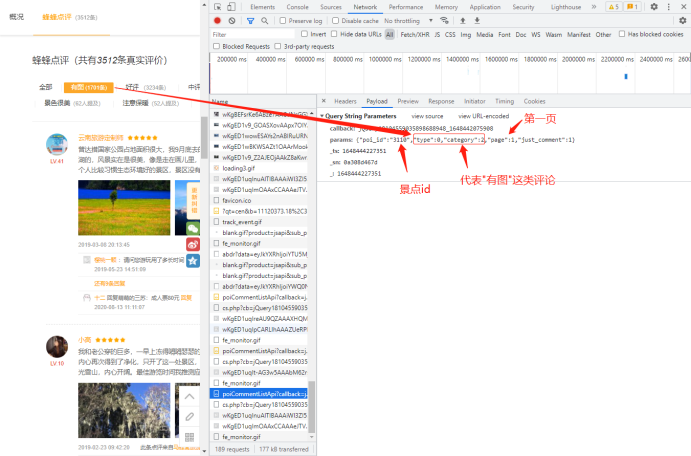
点击Payload,如果是下面这种情况你就点击一下左边的分类标签(任选一个),在Name列表中一直往下滑找到Name为poiCommentListApi?为首的(根据你的点击次数就会有多少个,从后往前找看看规律)

找到最后一个Name为poiCommentListApi?为首的,点击Payload,看一下这个params参数
所以对于同一个景点来说,变化的参数有:评论类别(由type、catagory决定)、页码(取值范围1-5)
分析完之后就可以写代码了
🌹--<-<-<@美味的code👑
import re
import time
import requests
import pandas as pdcomment_url = 'http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?'
requests_headers = {'Referer': 'https://www.mafengwo.cn/poi/3110.html','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}# Comment categories
a = [0, 0, 1, 1, 1, 2, 2, 2, 2, 2, 0]
b = [0, 2, 13, 12, 11, 134700810, 173942219, 112047583, 112968615, 143853527, 1]# Iterate through ten categories of comments
for i in range(11):# Get comments from five pages for each categoryfor num in range(1, 6):print('Fetching Page', num)requests_data = {'params': '{"poi_id":"3110","type":"%d","category":"%d","page":"%d","just_comment":1}' % (a[i], b[i], num)}response = requests.get(url=comment_url, headers=requests_headers, params=requests_data)if 200 == response.status_code:page = response.content.decode('unicode-escape', 'ignore').encode('utf-8', 'ignore').decode('utf-8')page = page.replace('\\/', '/')date_pattern = r'<a class="btn-comment _j_comment" title="Add Comment">Comment</a>.*?\n.*?<span class="time">(.*?)</span>'date_list = re.compile(date_pattern).findall(page)star_pattern = r'<span class="s-star s-star(\d)"></span>'star_list = re.compile(star_pattern).findall(page)comment_pattern = r'<p class="rev-txt">([\s\S]*?)</p>'comment_list = re.compile(comment_pattern).findall(page)for num in range(0, len(date_list)):date = date_list[num]star = star_list[num]comment = comment_list[num]comment = str(comment).replace(' ', '')comment = comment.replace('<br>', '')comment = comment.replace('<br />', "")comment = comment.replace('\n', "")comment = comment.replace("【", "")comment = comment.replace("】", "")comment = comment.replace("~", "")comment = comment.replace("*", "")comment = comment.replace('<br />', '')df = pd.DataFrame({'time1': date_list, 'score': star_list, 'content': comment_list})df.to_csv('mafengwo.csv', mode='a', encoding='gb18030', index=False, header=None)print('Write successful')else:print("Fetch failed")
既然都看到這裏了,不如点个关注+收藏再走咯!?