本地网站可以做吗?深圳网站seo优化
1.hadoop是一个分布式系统基础架构,主要解决海量数据额度存储与海量数据的分析计算问题
hdfs提供存储能力,yarn提供资源管理能力,MapReduce提供计算能力
2.安装
一:调整虚拟机内存,4G即可

二:下载安装包
网址:https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
hadoop安装包
命令: wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
三:解压: 命令: tar -zxvf hadoop-3.4.0.tar.gz -C ./
很遗憾,没有空间了,接下来解决这问题

查看磁盘文件,发现已经拉满了,接下来需要到VMware调整

删除快照后修改磁盘大小,我改了50G

再次解压,还是错误,df -h发现没变,应该是磁盘分区问题

(1)查看挂载点/的文件系统,在/dev/mapper/centos-root下面
(2)用mount命令查看挂载点的文件系统的文件类型也就是/dev/mapper/centos-root的文件类型

(3)此时发现分区是xfs类型

(4)命令:fdisk -l

(5)操作:命令 fdisk /dev/sda
按操作依次进行

(6)再次fdisk -l 发现有新分区,接下来格式化和挂载新分区,否则不能用

(7)先重启虚拟机操作系统,reboot
(8)先试用lvs命令,再创建物理卷 命令: pvcreate /dev/sda3
(9)物理卷添加到卷组中 命令: vgextend centos /dev/sda3 (centos为组名)
(10)查看可扩展的空间大小 命令:vgdisplay
找到这个free pe,这个是可扩充的大小(我弄完写的文章,所以这里是4mb)
![]()
(11)扩充磁盘空间: 命令: lvextend -L+16G /dev/mapper/centos-root /dev/sda3
(12).扩充生效 命令: xfs_growfs /dev/mapper/centos-root (后面这个是文件系统)
(13)再次df -h,发现容量扩充成功!

这时候解压没有问题

四:构建软连接
命令: ln -s /export/server/hadoop-3.4.0 /export/server/hadoop

五:修改配置文件hadoop-env.sh 命令: vi /export/server/hadoop-3.4.0/etc/hadoop/hadoop-env.sh
# 在文件开头加入:
#配置Java安装路径
export JAVA_HOHE=/export/server/jdk
#配置Hadoop安装路径
export HADOOP_HOME=/export/server/hadoop
# Hadoop hdfs配置文件路径
export HADOOP_CONF_OIR=$HADOOP_HOME/etc/hadoop
# Hadoop YARN配置文件路径
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# Hadoop YARN 日志文件夹
export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
# Hadoop hdfs 日志文件夹
export HADOOP_LOG_DIR=$HADOOP_HOME/logs/hdfs
# Hadoop的使用启动用户配置
export HDFS_NAHENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root

六:修改core-site.xml文件 命令: vi core-site.xml
全部删除,加入下面的!!
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file.-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://wtk:8020</value>
<description></description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description></description>
</property>
</configuration>
七:修改hdfs-site.xml文件 命令: vi hdfs-site.xml
清空加入
<?xmm version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href='"configuration.xsl"?>
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<valve>/data/nn</value>
<description>Path on the local fIlesysten where the NameNode stores the namespace and transactions logs
persistently.</description>
</property>
<property>
<name>dfs.namenode.hosts</name>
<valve>wtk,wtk1,wtk2</value>
<description>List Of permitted DataNodes.</description>
</property>
<valve>268435456</value>
<description></description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<valve>100</value>
<description></description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<valve>/data/dn</value>
</property>
</configuration>
八:修改mapred-env.sh文件
开头加入:
export JAVA_HOHE=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO, RFA

八:修改配置文件 mapred-site.xml
清空加入
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>wtk:10020</value>
<description></description>
</property>
<property>
<value>/data/mr-history/done</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=SHADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
九:修改yarn-env.sh配置
加入如下

九:修改yarn-site.xml 配置
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.log.server.url</name>
<value>http://wtk:19888/jobhistory/logs</value>
<description></description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>wtk:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>wtk</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>Comma-separated list of paths on the local filesystem where logs are written.</description>
</property>
<property>
<name>yarn.nodemanager. log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable
if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>
</configuration>
十:更改环境变量(所有主机都要配置): 命令: vi /etc/profile
加入:
export HADOOP_HOME=/export/server/hadoop-3.4.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin

配置生效: 命令:如下source /etc/profile
hadoop version查看是否配置成功
source /etc/profile
十一:修改workers文件
加入:

十二:分发hadoop到其他主机
命令 cd /export/server
scp -r hadoop-3.3.0 wtk1:`pwd`/ (wtk1是主机名)
十三:其他主机构建软连接
命令: ln -s /export/server/hadoop-3.4.0 /export/server/hadoop
十四:创建所需目录:

[root@wtk1 hadoop]# mkdir -p /data/nn
[root@wtk1 hadoop]# mkdir -p /data/dn
[root@wtk1 hadoop]# mkdir -p /data/nm-log
[root@wtk1 hadoop]# mkdir -p /data/nm-local
十五:格式化文件系统
命令: hadoop namenode -format

十六:启动hdfs集群 命令:start-dfs.sh

start-dfs.sh失败![]() https://www.cnblogs.com/live41/p/15636229.html
https://www.cnblogs.com/live41/p/15636229.html
启动后jps将会看到

十七:启动yarn 命令: start-yarn.sh
启动完将会看到

十八:启动历史服务器 命令: mapred --daemon start historyserver
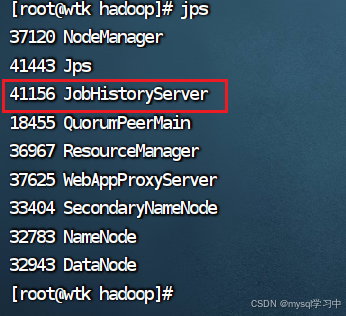
这就搭建好了,下班