怎么做网站多少钱在线培训系统平台
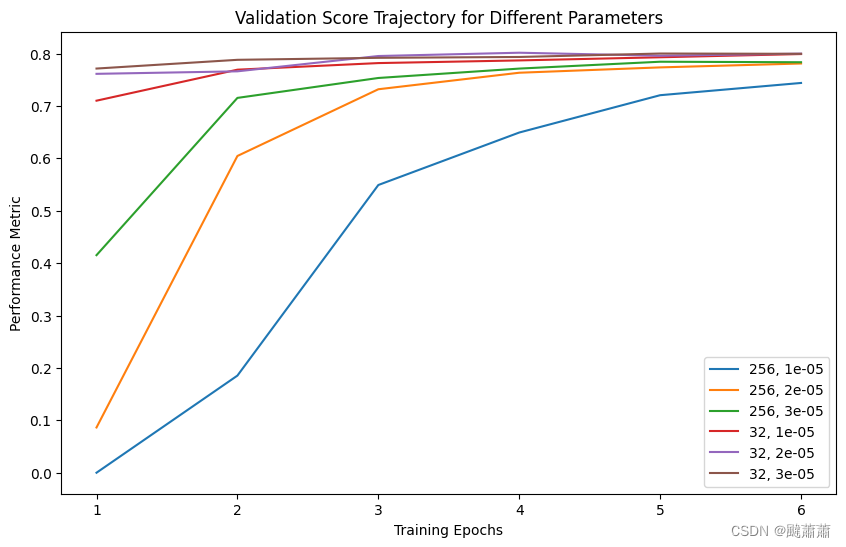
针对批大小和学习率的组合进行收敛速度测试,结论:
- 相同轮数的条件下,batchsize-32 相比 batchsize-256 的迭代步数越多,收敛更快
- 批越大的话,学习率可以相对设得大一点
画图代码(deepseek生成):
import matplotlib.pyplot as pltdic = {(256, 1e-5): [0, 0.185357, 0.549124, 0.649283, 0.720528, 0.743900],(256, 2e-5): [0.086368, 0.604535, 0.731870, 0.763409, 0.773608, 0.781042],(256, 3e-5): [0.415224, 0.715375, 0.753391, 0.771326, 0.784421, 0.783432],(32, 1e-5): [0.710058, 0.769245, 0.781832, 0.786909, 0.792920, 0.799076],(32, 2e-5): [0.761296, 0.766089, 0.795317, 0.801602, 0.795861, 0.799864],(32, 3e-5): [0.771385, 0.788055, 0.791863, 0.793491, 0.800057, 0.799527],
}# 提取参数和对应的训练轨迹
params = list(dic.keys())
trajectories = list(dic.values())# 绘制折线图
plt.figure(figsize=(10, 6))
for param, trajectory in zip(params, trajectories):plt.plot(range(1, len(trajectory) + 1), trajectory, label=f'{param[0]}, {param[1]}')# 设置图表标题和坐标轴标签
plt.title('Validation Score Trajectory for Different Parameters')
plt.xlabel('Training Epochs')
plt.ylabel('Performance Metric')# 添加图例
plt.legend()# 显示图表
plt.show()
附录
微调命令
!python ner_finetune.py \
--gpu_device 0 \
--train_batch_size 32 \
--valid_batch_size 32 \
--epochs 6 \
--learning_rate 3e-5 \
--train_file data/cluener2020/train.json \
--valid_file data/cluener2020/dev.json \
--allow_label "{'name': 'PER', 'organization': 'ORG', 'address': 'LOC', 'company': 'ORG', 'government': 'ORG'}" \
--pretrained_model models/bert-base-chinese \
--tokenizer models/bert-base-chinese \
--save_model_dir models/local/bert_tune_5
日志
Namespace(allow_label={'name': 'PER', 'organization': 'ORG', 'address': 'LOC', 'company': 'ORG', 'government': 'ORG'}, epochs=6, gpu_device='0', learning_rate=3e-05, max_grad_norm=10, max_len=128, pretrained_model='models/bert-base-chinese', save_model_dir='models/local/bert_tune_5', tokenizer='models/bert-base-chinese', train_batch_size=32, train_file='data/cluener2020/train.json', valid_batch_size=32, valid_file='data/cluener2020/dev.json')
CUDA is available!
Number of CUDA devices: 1
Device name: NVIDIA GeForce RTX 2080 Ti
Device capability: (7, 5)
标签映射: {'O': 0, 'B-PER': 1, 'B-ORG': 2, 'B-LOC': 3, 'I-PER': 4, 'I-ORG': 5, 'I-LOC': 6}
加载数据集:data/cluener2020/train.json0%| | 0/10748 [00:00<?, ?it/s]2024-05-21 14:05:00.121060: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2024-05-21 14:05:00.172448: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-05-21 14:05:00.914503: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
100%|███████████████████████████████████| 10748/10748 [00:06<00:00, 1667.09it/s]
100%|█████████████████████████████████████| 1343/1343 [00:00<00:00, 2244.82it/s]
TRAIN Dataset: 7824
VALID Dataset: 971
加载模型:models/bert-base-chinese
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:- Avoid using `tokenizers` before the fork if possible- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Some weights of the model checkpoint at models/bert-base-chinese were not used when initializing BertForTokenClassification: ['cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertForTokenClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForTokenClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForTokenClassification were not initialized from the model checkpoint at models/bert-base-chinese and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Training epoch: 1
Training loss per 100 training steps: 2.108242988586426
Training loss per 100 training steps: 0.16535191606767108
Training loss per 100 training steps: 0.10506394136678521
Training loss epoch: 0.09411744458638892
Training accuracy epoch: 0.9225966380147197
Validation loss per 100 evaluation steps: 0.05695410072803497
Validation Loss: 0.03870751528489974
Validation Accuracy: 0.9578078217665675precision recall f1-score support
LOC 0.544872 0.683646 0.606421 373.0
ORG 0.750225 0.841734 0.793349 992.0
PER 0.806452 0.913978 0.856855 465.0
micro avg 0.718691 0.827869 0.769426 1830.0
macro avg 0.700516 0.813119 0.752208 1830.0
weighted avg 0.722656 0.827869 0.771385 1830.0
Training epoch: 2
Training loss per 100 training steps: 0.030774801969528198
Training loss per 100 training steps: 0.03080757723033133
Training loss per 100 training steps: 0.03123850032538917
Training loss epoch: 0.03104725396450685
Training accuracy epoch: 0.965836879311368
Validation loss per 100 evaluation steps: 0.07264477759599686
Validation Loss: 0.03662088588480988
Validation Accuracy: 0.961701479064846precision recall f1-score support
LOC 0.606635 0.686327 0.644025 373.0
ORG 0.776735 0.834677 0.804665 992.0
PER 0.821497 0.920430 0.868154 465.0
micro avg 0.752613 0.826230 0.787705 1830.0
macro avg 0.734956 0.813812 0.772281 1830.0
weighted avg 0.753439 0.826230 0.788055 1830.0
Training epoch: 3
Training loss per 100 training steps: 0.01707942970097065
Training loss per 100 training steps: 0.020070969108676555
Training loss per 100 training steps: 0.0214405001942717
Training loss epoch: 0.021760025719294744
Training accuracy epoch: 0.9760199331084162
Validation loss per 100 evaluation steps: 0.04943108558654785
Validation Loss: 0.03711987908689245
Validation Accuracy: 0.9608263101353024precision recall f1-score support
LOC 0.596847 0.710456 0.648715 373.0
ORG 0.776328 0.839718 0.806780 992.0
PER 0.855967 0.894624 0.874869 465.0
micro avg 0.755866 0.827322 0.789982 1830.0
macro avg 0.743047 0.814932 0.776788 1830.0
weighted avg 0.759981 0.827322 0.791863 1830.0
Training epoch: 4
Training loss per 100 training steps: 0.014015918597579002
Training loss per 100 training steps: 0.015494177154827826
Training loss per 100 training steps: 0.015997812416015278
Training loss epoch: 0.016311514128607756
Training accuracy epoch: 0.9820175765149567
Validation loss per 100 evaluation steps: 0.04825771600008011
Validation Loss: 0.04313824124514095
Validation Accuracy: 0.9585233633276977precision recall f1-score support
LOC 0.618037 0.624665 0.621333 373.0
ORG 0.794118 0.843750 0.818182 992.0
PER 0.853955 0.905376 0.878914 465.0
micro avg 0.774948 0.814754 0.794353 1830.0
macro avg 0.755370 0.791264 0.772810 1830.0
weighted avg 0.773433 0.814754 0.793491 1830.0
Training epoch: 5
Training loss per 100 training steps: 0.008429908193647861
Training loss per 100 training steps: 0.012711652241057098
Training loss per 100 training steps: 0.012486798004177747
Training loss epoch: 0.012644028145705862
Training accuracy epoch: 0.9862629694070859
Validation loss per 100 evaluation steps: 0.06491336971521378
Validation Loss: 0.049802260893967845
Validation Accuracy: 0.9582402189526026precision recall f1-score support
LOC 0.608899 0.697051 0.650000 373.0
ORG 0.795749 0.867944 0.830280 992.0
PER 0.831643 0.881720 0.855950 465.0
micro avg 0.764735 0.836612 0.799061 1830.0
macro avg 0.745430 0.815572 0.778743 1830.0
weighted avg 0.766785 0.836612 0.800057 1830.0
Training epoch: 6
Training loss per 100 training steps: 0.009717799723148346
Training loss per 100 training steps: 0.008476002312422093
Training loss per 100 training steps: 0.008608183584903456
Training loss epoch: 0.008819052852614194
Training accuracy epoch: 0.9903819524689835
Validation loss per 100 evaluation steps: 0.023518526926636696
Validation Loss: 0.049626993015408516
Validation Accuracy: 0.9602429496287505precision recall f1-score support
LOC 0.614251 0.670241 0.641026 373.0
ORG 0.806482 0.852823 0.829005 992.0
PER 0.848548 0.879570 0.863780 465.0
micro avg 0.776574 0.822404 0.798832 1830.0
macro avg 0.756427 0.800878 0.777937 1830.0
weighted avg 0.777989 0.822404 0.799527 1830.0