网站 建设设计百度优化
数据增强是针对数据集图像数量太少所采取的一种方法。
博主在实验过程中,使用自己的数据集时发现其数据量过少,只有280张,因此便想到使用数据增强的方式来获取更多的图像信息。对于图像数据,我们可以采用旋转等操作来获取更多的图像。
对于已经标注好的图片,则可以通过imgaug实现对图片和标签中的boundingbox同时变换。
首先,安装依赖库。我们首先创建conda环境,然后下载对应的工具包,这里需要提示一下,里面有个工具包imgaug只能在python2.7,3.4以及3.6使用,并且其需要很多依赖包,我们在直接执行安装imgaug命令时会默认安装opencv-python,但博主却总是安装失败,后来发现可以安装opencv来代替。即:
conda install opencv
考虑到下载速度,可以使用以下命令按照imgaug依赖包:
pip install six numpy scipy matplotlib scikit-image opencv-python imageio tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple
随后也可以直接安装imgaug
conda install imgaug
接下来是相关功能介绍。
读取原影像bounding boxes坐标
读取xml文件并使用ElementTree对xml文件进行解析,找到每个object的坐标值。
def change_xml_list_annotation(root, image_id, new_target, saveroot, id):in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思tree = ET.parse(in_file)#修改增强后的xml文件中的filenameelem = tree.find('filename')elem.text = (str(id) + '.jpg')xmlroot = tree.getroot()#修改增强后的xml文件中的pathelem = tree.find('path')if elem != None:elem.text = (saveroot + str(id) + '.jpg')index = 0for object in xmlroot.findall('object'): # 找到root节点下的所有country节点bndbox = object.find('bndbox') # 子节点下节点rank的值# xmin = int(bndbox.find('xmin').text)# xmax = int(bndbox.find('xmax').text)# ymin = int(bndbox.find('ymin').text)# ymax = int(bndbox.find('ymax').text)new_xmin = new_target[index][0]new_ymin = new_target[index][1]new_xmax = new_target[index][2]new_ymax = new_target[index][3]xmin = bndbox.find('xmin')xmin.text = str(new_xmin)ymin = bndbox.find('ymin')ymin.text = str(new_ymin)xmax = bndbox.find('xmax')xmax.text = str(new_xmax)ymax = bndbox.find('ymax')ymax.text = str(new_ymax)index = index + 1tree.write(os.path.join(saveroot, str(id + '.xml')))
生成变换序列
产生一个处理图片的Sequential。
# 影像增强seq = iaa.Sequential([iaa.Invert(0.5),iaa.Fliplr(0.5), # 镜像iaa.Multiply((1.2, 1.5)), # change brightness, doesn't affect BBsiaa.GaussianBlur(sigma=(0, 3.0)), # iaa.GaussianBlur(0.5),iaa.Affine(translate_px={"x": 15, "y": 15},scale=(0.8, 0.95),) # translate by 40/60px on x/y axis, and scale to 50-70%, affects BBs])
bounding box 变化后坐标计算
先读取该影像对应xml文件,获取所有目标的bounding boxes,然后依次计算每个box变化后的坐标。
seq_det = seq.to_deterministic() # 保持坐标和图像同步改变,而不是随机
# 读取图片
img = Image.open(os.path.join(IMG_DIR, name[:-4] + '.jpg'))
# sp = img.size
img = np.asarray(img)
# bndbox 坐标增强
for i in range(len(bndbox)):bbs = ia.BoundingBoxesOnImage([ia.BoundingBox(x1=bndbox[i][0], y1=bndbox[i][1], x2=bndbox[i][2], y2=bndbox[i][3]),], shape=img.shape)bbs_aug = seq_det.augment_bounding_boxes([bbs])[0]boxes_img_aug_list.append(bbs_aug)# new_bndbox_list:[[x1,y1,x2,y2],...[],[]]n_x1 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x1)))n_y1 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y1)))n_x2 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x2)))n_y2 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y2)))if n_x1 == 1 and n_x1 == n_x2:n_x2 += 1if n_y1 == 1 and n_y2 == n_y1:n_y2 += 1if n_x1 >= n_x2 or n_y1 >= n_y2:print('error', name)new_bndbox_list.append([n_x1, n_y1, n_x2, n_y2])
# 存储变化后的图片
image_aug = seq_det.augment_images([img])[0]
path = os.path.join(AUG_IMG_DIR,str(str(name[:-4]) + '_' + str(epoch)) + '.jpg')
image_auged = bbs.draw_on_image(image_aug, thickness=0)
Image.fromarray(image_auged).save(path)# 存储变化后的XML
change_xml_list_annotation(XML_DIR, name[:-4], new_bndbox_list, AUG_XML_DIR,str(name[:-4]) + '_' + str(epoch))
# print(str(str(name[:-4]) + '_' + str(epoch)) + '.jpg')
new_bndbox_list = []
开始增强
数据准备
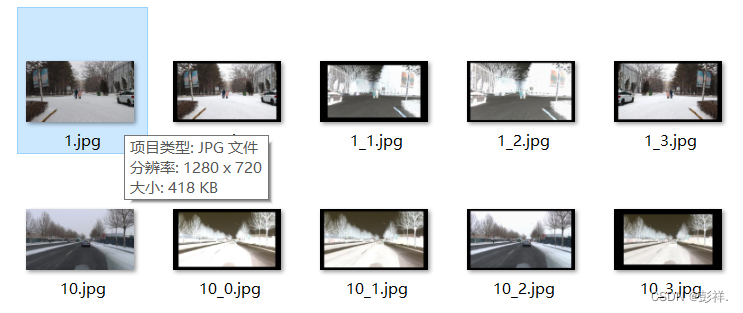
输入数据为两个文件夹一个是需要增强的图像数据(JPEGImages),一个是对应的xml文件(Annotations)。注意:图像文件名需和xml文件名相对应!
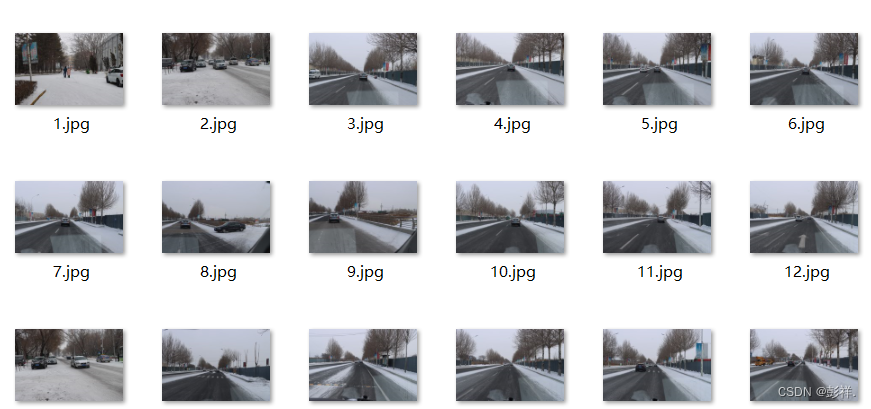
之后执行即可,得到文件如下:
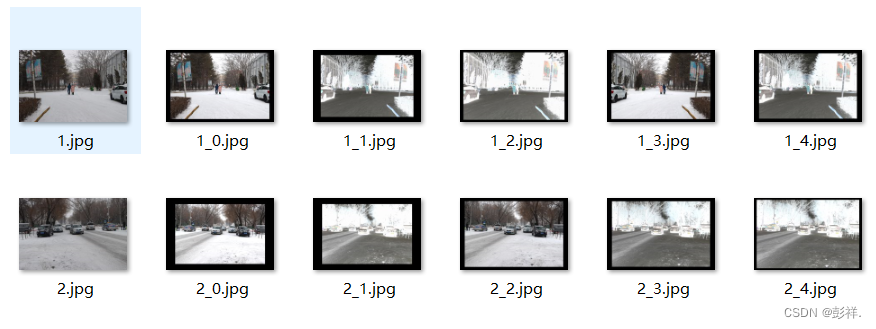
完整代码
import xml.etree.ElementTree as ET
import os
import imgaug as ia
import numpy as np
import shutil
from tqdm import tqdm
from PIL import Image
from imgaug import augmenters as iaaia.seed(1)def read_xml_annotation(root, image_id):in_file = open(os.path.join(root, image_id))tree = ET.parse(in_file)root = tree.getroot()bndboxlist = []for object in root.findall('object'): # 找到root节点下的所有country节点bndbox = object.find('bndbox') # 子节点下节点rank的值xmin = int(bndbox.find('xmin').text)xmax = int(bndbox.find('xmax').text)ymin = int(bndbox.find('ymin').text)ymax = int(bndbox.find('ymax').text)# print(xmin,ymin,xmax,ymax)bndboxlist.append([xmin, ymin, xmax, ymax])# print(bndboxlist)bndbox = root.find('object').find('bndbox')return bndboxlistdef change_xml_list_annotation(root, image_id, new_target, saveroot, id):in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思tree = ET.parse(in_file)# 修改增强后的xml文件中的filenameelem = tree.find('filename')elem.text = (str(id) + '.jpg')xmlroot = tree.getroot()# 修改增强后的xml文件中的pathelem = tree.find('path')if elem != None:elem.text = (saveroot + str(id) + '.jpg')index = 0for object in xmlroot.findall('object'): # 找到root节点下的所有country节点bndbox = object.find('bndbox') # 子节点下节点rank的值# xmin = int(bndbox.find('xmin').text)# xmax = int(bndbox.find('xmax').text)# ymin = int(bndbox.find('ymin').text)# ymax = int(bndbox.find('ymax').text)new_xmin = new_target[index][0]new_ymin = new_target[index][1]new_xmax = new_target[index][2]new_ymax = new_target[index][3]xmin = bndbox.find('xmin')xmin.text = str(new_xmin)ymin = bndbox.find('ymin')ymin.text = str(new_ymin)xmax = bndbox.find('xmax')xmax.text = str(new_xmax)ymax = bndbox.find('ymax')ymax.text = str(new_ymax)index = index + 1tree.write(os.path.join(saveroot, str(id + '.xml')))def mkdir(path):# 去除首位空格path = path.strip()# 去除尾部 \ 符号path = path.rstrip("\\")# 判断路径是否存在# 存在 True# 不存在 FalseisExists = os.path.exists(path)# 判断结果if not isExists:# 如果不存在则创建目录# 创建目录操作函数os.makedirs(path)print(path + ' 创建成功')return Trueelse:# 如果目录存在则不创建,并提示目录已存在print(path + ' 目录已存在')return Falseif __name__ == "__main__":IMG_DIR = "E:/KITTI/jiamusi/VOC/JPEGImage/"#图像原路径XML_DIR = "E:/KITTI/jiamusi/VOC/VOC_Annotation/"AUG_XML_DIR = "E:/KITTI/jiamusi/VOC/VOC/Annotations/" # 存储增强后的XML文件夹路径try:shutil.rmtree(AUG_XML_DIR)except FileNotFoundError as e:a = 1mkdir(AUG_XML_DIR)AUG_IMG_DIR = "E:/KITTI/jiamusi/VOC/VOC/JPEGImages/" # 存储增强后的影像文件夹路径try:shutil.rmtree(AUG_IMG_DIR)except FileNotFoundError as e:a = 1mkdir(AUG_IMG_DIR)AUGLOOP = 5 # 每张影像增强的数量,博主有近260张,增强5次即可boxes_img_aug_list = []new_bndbox = []new_bndbox_list = []# 影像增强seq = iaa.Sequential([iaa.Invert(0.5),iaa.Fliplr(0.5), # 镜像iaa.Multiply((1.2, 1.5)), # change brightness, doesn't affect BBsiaa.GaussianBlur(sigma=(0, 3.0)), # iaa.GaussianBlur(0.5),iaa.Affine(translate_px={"x": 15, "y": 15},scale=(0.8, 0.95),) # translate by 40/60px on x/y axis, and scale to 50-70%, affects BBs])for name in tqdm(os.listdir(XML_DIR), desc='Processing'):bndbox = read_xml_annotation(XML_DIR, name)# 保存原xml文件shutil.copy(os.path.join(XML_DIR, name), AUG_XML_DIR)# 保存原图og_img = Image.open(IMG_DIR + '/' + name[:-4] + '.jpg')og_img.convert('RGB').save(AUG_IMG_DIR + name[:-4] + '.jpg', 'JPEG')og_xml = open(os.path.join(XML_DIR, name))tree = ET.parse(og_xml)# 修改增强后的xml文件中的filenameelem = tree.find('filename')elem.text = (name[:-4] + '.jpg')tree.write(os.path.join(AUG_XML_DIR, name))for epoch in range(AUGLOOP):seq_det = seq.to_deterministic() # 保持坐标和图像同步改变,而不是随机# 读取图片img = Image.open(os.path.join(IMG_DIR, name[:-4] + '.jpg'))# sp = img.sizeimg = np.asarray(img)# bndbox 坐标增强for i in range(len(bndbox)):bbs = ia.BoundingBoxesOnImage([ia.BoundingBox(x1=bndbox[i][0], y1=bndbox[i][1], x2=bndbox[i][2], y2=bndbox[i][3]),], shape=img.shape)bbs_aug = seq_det.augment_bounding_boxes([bbs])[0]boxes_img_aug_list.append(bbs_aug)# new_bndbox_list:[[x1,y1,x2,y2],...[],[]]n_x1 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x1)))n_y1 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y1)))n_x2 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x2)))n_y2 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y2)))if n_x1 == 1 and n_x1 == n_x2:n_x2 += 1if n_y1 == 1 and n_y2 == n_y1:n_y2 += 1if n_x1 >= n_x2 or n_y1 >= n_y2:print('error', name)new_bndbox_list.append([n_x1, n_y1, n_x2, n_y2])# 存储变化后的图片image_aug = seq_det.augment_images([img])[0]path = os.path.join(AUG_IMG_DIR,str(str(name[:-4]) + '_' + str(epoch)) + '.jpg')image_auged = bbs.draw_on_image(image_aug, size=0)Image.fromarray(image_auged).convert('RGB').save(path)# 存储变化后的XMLchange_xml_list_annotation(XML_DIR, name[:-4], new_bndbox_list, AUG_XML_DIR,str(name[:-4]) + '_' + str(epoch))# print(str(str(name[:-4]) + '_' + str(epoch)) + '.jpg')new_bndbox_list = []print('Finish!')
但运行后发现问题,图片太大,所有我们需要进行修改。
原图为6960x46460,其不但图片较大,且6960不能整除32,造成错误。因此需要将图片进行修改。并要在resize的同时还要将标注信息一并转换。
import glob
import xml.dom.minidom
import cv2
from PIL import Image
import matplotlib.pyplot as plt
import os# 定义待批量裁剪图像的路径地址
IMAGE_INPUT_PATH = r'E:\KITTI\jiamusi\VOC\VOC2023\JPEGImages'
XML_INPUT_PATH = r'E:\KITTI\jiamusi\VOC\VOC2023\Annotations'
# 定义裁剪后的图像存放地址
IMAGE_OUTPUT_PATH = r'E:\KITTI\jiamusi\VOC\VOC2023\VOC2023\JPEGImages'
XML_OUTPUT_PATH = r'E:\KITTI\jiamusi\VOC\VOC2023\VOC2023\Annotations'
imglist = os.listdir(IMAGE_INPUT_PATH)
xmllist = os.listdir(XML_INPUT_PATH)for i in range(len(imglist)):# 每个图像全路径image_input_fullname = IMAGE_INPUT_PATH + '/' + imglist[i]xml_input_fullname = XML_INPUT_PATH + '/' + xmllist[i]image_output_fullname = IMAGE_OUTPUT_PATH + '/' + imglist[i]xml_output_fullname = XML_OUTPUT_PATH + '/' + xmllist[i]img = cv2.imread(image_input_fullname)height, width = img.shape[:2]# 定义缩放信息 以等比例缩放到416为例scale1 = 720/ height #yscale2 = 1280 / width#xheight = 720width = 1280dom = xml.dom.minidom.parse(xml_input_fullname)root = dom.documentElement# 读取标注目标框objects = root.getElementsByTagName("bndbox")for object in objects:xmin = object.getElementsByTagName("xmin")xmin_data = int(float(xmin[0].firstChild.data))# xmin[0].firstChild.data =str(int(xmin1 * x))ymin = object.getElementsByTagName("ymin")ymin_data = int(float(ymin[0].firstChild.data))xmax = object.getElementsByTagName("xmax")xmax_data = int(float(xmax[0].firstChild.data))ymax = object.getElementsByTagName("ymax")ymax_data = int(float(ymax[0].firstChild.data))# 更新xmlwidth_xml = root.getElementsByTagName("width")width_xml[0].firstChild.data = widthheight_xml = root.getElementsByTagName("height")height_xml[0].firstChild.data = heightxmin[0].firstChild.data = int(xmin_data * scale2)ymin[0].firstChild.data = int(ymin_data * scale1)xmax[0].firstChild.data = int(xmax_data * scale2)ymax[0].firstChild.data = int(ymax_data * scale1)# 另存更新后的文件with open(xml_output_fullname, 'w') as f:dom.writexml(f, addindent=' ', encoding='utf-8')# 测试缩放效果img = cv2.resize(img, (width, height))'''# xmin, ymin, xmax, ymax分别为xml读取的坐标信息left_top = (int(xmin_data*scale), int(ymin_data*scale))right_down= (int(xmax_data*scale), int(ymax_data*scale))cv2.rectangle(img, left_top, right_down, (255, 0, 0), 1)'''cv2.imwrite(image_output_fullname, img)
将其转换为1280x720的格式,就可以使用了。