发任务做任务得网站网络推广渠道公司
K-Means 是一种常用的无监督学习算法,广泛应用于数据聚类分析。本文将详细讲解 K-Means 算法的原理、步骤、公式以及 Python 实现,帮助你深入理解这一经典算法。
什么是 K-Means 算法?
K-Means 算法是一种基于原型的聚类算法,其目标是将数据集分成K个簇(clusters),使得同一簇内的数据点尽可能相似,不同簇之间的数据点尽可能不同。每个簇由其中心(即质心,centroid)表示。
K-Means 算法的步骤
K-Means 算法的主要步骤如下:
- 初始化:随机选择 K个数据点作为初始质心。
- 分配簇:将每个数据点分配到距离其最近的质心对应的簇。
- 更新质心:计算每个簇的质心,即簇内所有数据点的平均值。
- 重复步骤 2 和 3:直到质心不再发生变化(或变化很小),或者达到预设的迭代次数。
详细步骤解释
-
初始化:
- 从数据集中随机选择K 个点作为初始质心。这些质心可以是数据集中的实际点,也可以是随机生成的点。
-
分配簇:
- 计算每个数据点到所有质心的距离(通常使用欧氏距离)。对于数据点 ( x i ) \ (x_i ) (xi) 和质心 ( μ j ) (\mu_j) (μj),欧氏距离计算公式为:
d ( x i , μ j ) = ∑ m = 1 M ( x i m − μ j m ) 2 \ d(x_i, \mu_j) = \sqrt{\sum_{m=1}^M (x_{im} - \mu_{jm})^2} \ d(xi,μj)=m=1∑M(xim−μjm)2 - 将每个数据点分配到距离其最近的质心对应的簇,即:
C i = { x p : ∥ x p − μ i ∥ ≤ ∥ x p − μ j ∥ , ∀ j , 1 ≤ j ≤ k } \ C_i = \{ x_p : \| x_p - \mu_i \| \leq \| x_p - \mu_j \|, \forall j, 1 \leq j \leq k \} \ Ci={xp:∥xp−μi∥≤∥xp−μj∥,∀j,1≤j≤k}
- 计算每个数据点到所有质心的距离(通常使用欧氏距离)。对于数据点 ( x i ) \ (x_i ) (xi) 和质心 ( μ j ) (\mu_j) (μj),欧氏距离计算公式为:
-
更新质心:
- 对每个簇 ( C i ) \ ( C_i ) (Ci),计算簇内所有数据点的平均值,并将该平均值作为新的质心。新的质心计算公式为:
μ i = 1 ∣ C i ∣ ∑ x j ∈ C i x j \ \mu_i = \frac{1}{|C_i|} \sum_{x_j \in C_i} x_j \ μi=∣Ci∣1xj∈Ci∑xj
- 对每个簇 ( C i ) \ ( C_i ) (Ci),计算簇内所有数据点的平均值,并将该平均值作为新的质心。新的质心计算公式为:
-
重复:
- 重复分配簇和更新质心的步骤,直到质心位置不再发生变化或达到最大迭代次数。
K-Means 算法的优化目标
K-Means 算法的优化目标是最小化所有数据点到其所属簇质心的距离平方和。优化目标函数可以表示为:
J = ∑ i = 1 k ∑ x j ∈ C i ∥ x j − μ i ∥ 2 \ J = \sum_{i=1}^k \sum_{x_j \in C_i} \| x_j - \mu_i \|^2 \ J=i=1∑kxj∈Ci∑∥xj−μi∥2
该目标函数也称为聚类内的总平方误差(Total Within-Cluster Sum of Squares,简称 TSS)。
K-Means 算法的优缺点
优点
- 简单易懂:K-Means 算法原理简单,容易实现。
- 速度快:算法收敛速度快,适合处理大规模数据集。
- 适用范围广:在许多实际问题中表现良好。
缺点
- 选择 ( k ) 值的困难:需要预先指定簇的数量 ( k ),而合适的 ( k ) 值通常不易确定。
- 对初始值敏感:初始质心的选择会影响最终结果,可能陷入局部最优解。
- 对异常值敏感:异常值可能会显著影响质心的位置。
K-Means 算法的 Python 实现
下面通过 Python 代码实现 K-Means 算法,并以一个示例数据集展示其应用。
导入库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeansplt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
生成示例数据集
# 生成示例数据集
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.show()
应用 K-Means 算法
# 应用 K-Means 算法
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='x')
plt.show()
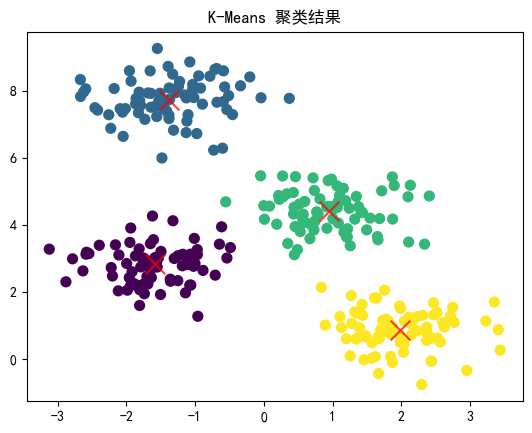
结果解释
在上面的示例中,我们生成了一个有 4 个簇的示例数据集,并使用 K-Means 算法对其进行聚类。最终,我们通过可视化展示了聚类结果以及每个簇的质心。
总结
K-Means 算法是一种简单而有效的聚类算法,广泛应用于各种数据分析和机器学习任务中。本文详细介绍了 K-Means 算法的原理、步骤、公式以及 Python 实现。虽然 K-Means 算法有一些缺点,但通过合理选择参数和预处理数据,可以在许多实际应用中取得良好的效果。希望本文能帮助你更好地理解和应用 K-Means 算法。