交互 网站怎么在百度上免费做广告
文章目录
- 版权声明
- 数据查询
- 环境准备
- 基本查询
- 准备数据
- select基础查询
- 分组、聚合
- JOIN
- RLIKE正则匹配
- UNION联合
- Sampling采用
- Virtual Columns虚拟列
版权声明
- 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利人所有。本博客的目的仅为个人学习和交流之用,并非商业用途。
- 我在整理学习笔记的过程中尽力确保准确性,但无法保证内容的完整性和时效性。本博客的内容可能会随着时间的推移而过时或需要更新。
- 若您是黑马程序员或相关权利人,如有任何侵犯版权的地方,请您及时联系我,我将立即予以删除或进行必要的修改。
- 对于其他读者,请在阅读本博客内容时保持遵守相关法律法规和道德准则,谨慎参考,并自行承担因此产生的风险和责任。本博客中的部分观点和意见仅代表我个人,不代表黑马程序员的立场。
数据查询
环境准备
- hdfs启动
start-dfs.sh - yarn启动
start-yarn.sh - HiveServer2服务 启动
#先启动metastore服务 然后启动hiveserver2服务 nohup bin/hive --service metastore >> logs/metastore.log 2>&1 & nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
基本查询
- 查询语句的基本语法
select [all | distinct] select_expr, select_expr, ..
from table_reference
[WHERE where_condition]
[group by col_list]
[having where_condition]
[order by col_list]
[ cluster by col_list|[DISTRIBUTE BY col_list] [SORT by col_list]
]
[LIMIT number]
准备数据
- 准备数据:订单表
create database itheima;
use itheima;
CREATE TABLE itheima.orders (orderId bigint COMMENT '订单id',orderNo string COMMENT '订单编号',shopId bigint COMMENT '门店id',userId bigint COMMENT '用户id',orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货',goodsMoney double COMMENT '商品金额',deliverMoney double COMMENT '运费',totalMoney double COMMENT '订单金额(包括运费)',realTotalMoney double COMMENT '实际订单金额(折扣后金额)',payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他',isPay tinyint COMMENT '是否支付 0:未支付 1:已支付',userName string COMMENT '收件人姓名',userAddress string COMMENT '收件人地址',userPhone string COMMENT '收件人电话',createTime timestamp COMMENT '下单时间',payTime timestamp COMMENT '支付时间',totalPayFee int COMMENT '总支付金额'
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';-- 上传数据到linux,导入数据
load data local inpath '/home/hadoop/itheima_orders.txt' into table itheima.orders;
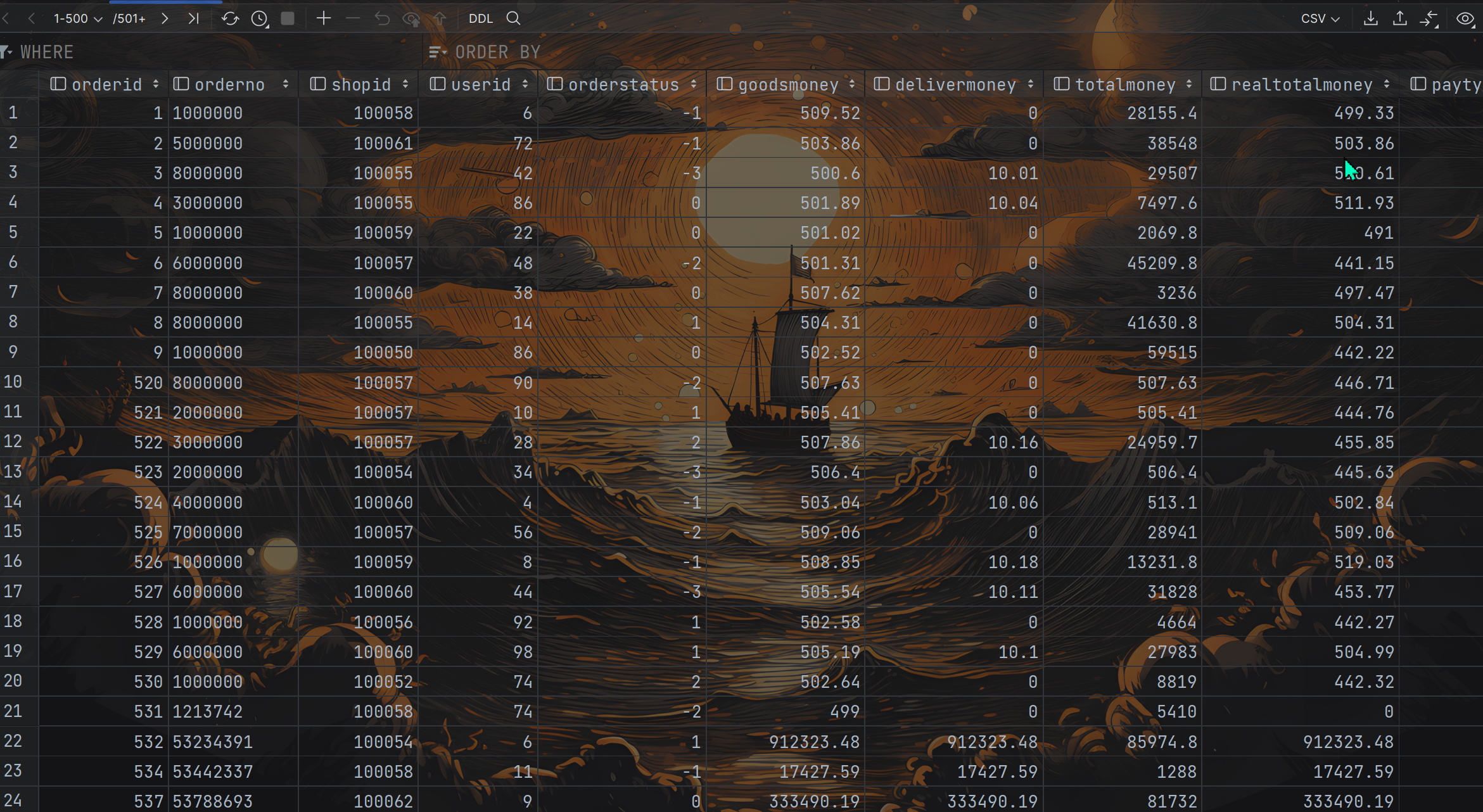
- 准备数据:用户表
CREATE TABLE itheima.users (userId int,loginName string,loginSecret int,loginPwd string,userSex tinyint,userName string,trueName string,brithday date,userPhoto string,userQQ string,userPhone string,userScore int,userTotalScore int,userFrom tinyint,userMoney double,lockMoney double,createTime timestamp,payPwd string,rechargeMoney double
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 导入数据
load data local inpath '/home/hadoop/itheima_users.txt' into table itheima.users;
select基础查询
-- 查询全表数据
SELECT * FROM itheima.orders;-- 查询单列信息
SELECT orderid, userid, totalmoney FROM itheima.orders;-- 查询表有多少条数据
SELECT COUNT(*) FROM itheima.orders;-- 过滤广东省的订单
SELECT * FROM itheima.orders
WHERE useraddress LIKE '%广东%';-- 找出广东省单笔营业额最大的订单
SELECT * FROM itheima.orders
WHERE useraddress LIKE '%广东%'
ORDER BY totalmoney DESC LIMIT 1;
分组、聚合
-- 统计未支付、已支付各自的人数
SELECT ispay, COUNT(*)
FROM itheima.orders
GROUP BY ispay;-- 在已付款的订单中,统计每个用户最高的一笔消费金额
SELECT userid, MAX(totalmoney)
FROM itheima.orders
WHERE ispay = 1 GROUP BY userid;SELECT usr.username, MAX(ord.totalmoney)
FROM itheima.orders ord,itheima.users usr
WHERE ord.userId=usr.userId and ord.ispay = 1
GROUP BY usr.username;-- 统计每个用户的平均订单消费额
SELECT userid, AVG(totalmoney)
FROM itheima.orders
GROUP BY userid;-- 统计每个用户的平均订单消费额,并过滤大于10000的数据
SELECT userid, AVG(totalmoney) AS avg_money
FROM itheima.orders
GROUP BY userid
HAVING avg_money > 10000;
JOIN
-- 订单表和用户表JOIN 找出用户username
SELECT o.orderid, o.userid, u.username
FROM itheima.orders o JOIN itheima.users u
ON o.userid = u.userid;
-- 左外连接
SELECT o.orderid, o.userid, u.username
FROM itheima.orders o
LEFT JOIN itheima.users uON o.userid = u.userid;
RLIKE正则匹配
- 正则表达式是一种规则集合,通过特定的规则字符描述,来判断字符串是否符合规则。
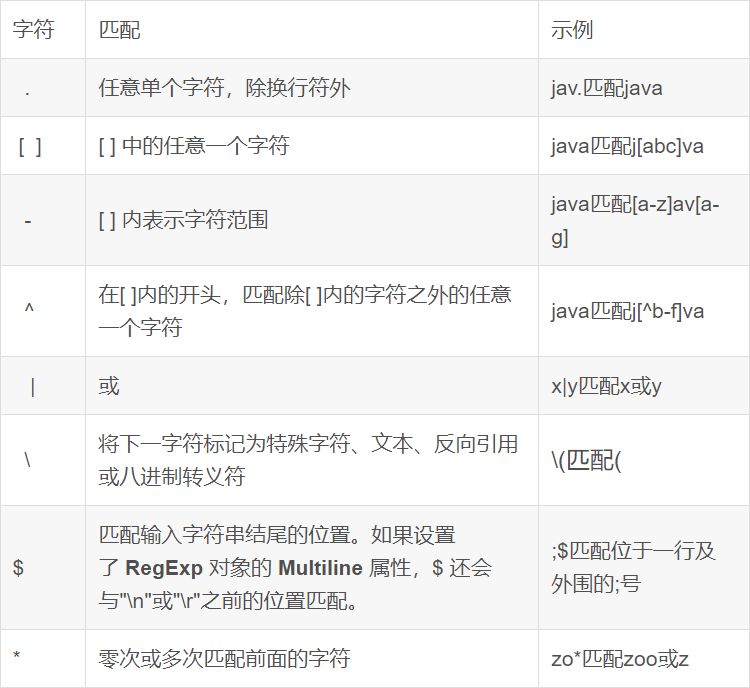
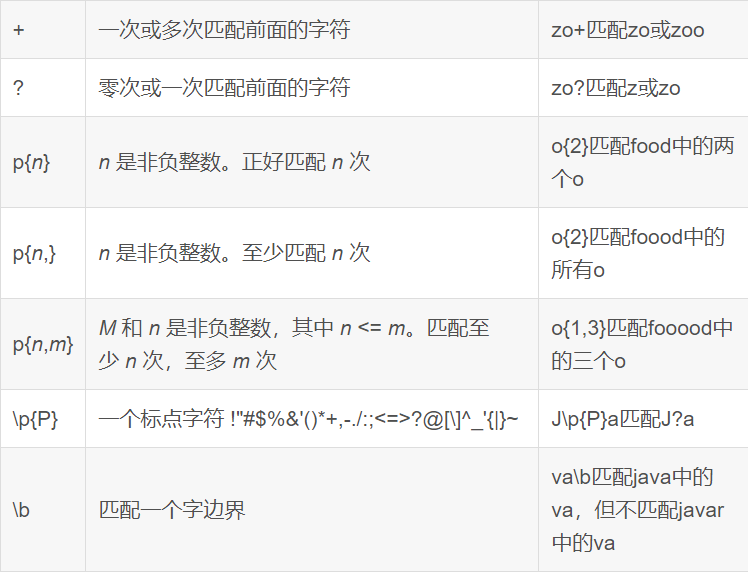
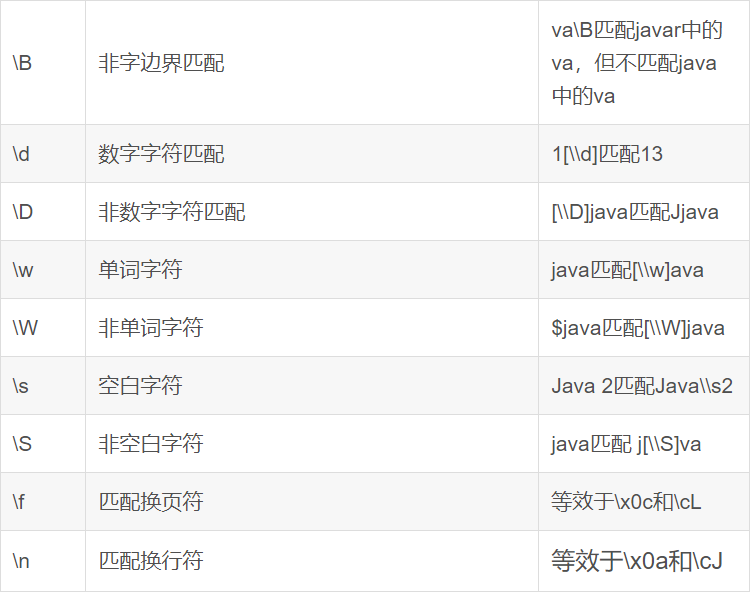
-- 查找广东省数据
SELECT * FROM itheima.orders WHERE useraddress RLIKE '.*广东.*';
-- 查找用户地址是:xx省 xx市 xx区
SELECT * FROM itheima.orders WHERE useraddress RLIKE '..省 ..市 ..区';
-- 查找用户姓为:张、王、邓
SELECT * FROM itheima.orders WHERE username RLIKE '[张王邓]\\S*+';
-- 查找手机号符合:188****0*** 规则
SELECT * FROM itheima.orders WHERE userphone RLIKE '188\\S{4}0[0-9]{3}';
UNION联合
- UNION 用于将多个SELECT语句的结果组合成单个结果集。
- 每个select语句返回的列的数量和名称必须相同。否则,将引发架构错误。
- UNION关键字的作用是?
- 将多个SELECT的结果集合并成一个
- 多个SELECT的结果集需要架构一致,否则无法合并
- 自带去重效果,如果无需去重,需要使用UNIONALL
- UNION用在何处
- 可以用在任何需要SELECT发挥的地方(包括子查询、ISNERTSELECT等)
- 基础语法
select ...union [all] select ...
CREATE TABLE itheima.course(c_id string,c_name string,t_id string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';LOAD DATA LOCAL INPATH '/home/hadoop/course.txt' INTO TABLE itheima.course;-- 基础UNION
SELECT * FROM itheima.course WHERE t_id = '周杰轮'
UNION
SELECT * FROM itheima.course WHERE t_id = '王力鸿';-- 去重演示
SELECT * FROM itheima.course
UNION
SELECT * FROM itheima.course;-- 不去重
SELECT * FROM itheima.course
UNION ALL
SELECT * FROM itheima.course;-- UNION写在FROM中 UNION写在子查询中
SELECT t_id, COUNT(*) FROM(SELECT * FROM itheima.course WHERE t_id = '周杰轮'UNION ALLSELECT * FROM itheima.course WHERE t_id = '王力鸿') AS u GROUP BY t_id;
Sampling采用

TABLE SAMPLE (BUCKET <x> OUT OF <y> [ON <col_name> | rand()])
- x,y:必填。将源表中的数据划分为y个桶,取其中的第x个桶,桶从1开始编号。
- col_name:分桶列名即要进行采样的列名。当表不是聚簇表时,col_name与rand()函数必须二选一,当使用rand()函数时表示对输入的数据随机进行分桶。ON语句中最多支持指定10个列。
语法2,基于数据块抽样
SELECT ... FROM tbl TABLESAMPLE(num ROWS I num PERCENT I num(KM|G));
- num ROWS 表示抽样num条数据
- num PERCENT表示抽样num百分百比例的数据
- num(K | M |G)表示抽取num大小的数据,单位可以是K、M、G表示KB、MB、GB
- 注意:
- 使用这种语法抽样,条件不变的话,每一次抽样的结果都一致
- 即无法做到随机,只是按照数据顺序从前向后取。
- TABLESAMPLE函数的使用
- 桶抽样方式,
TABLESAMPLE(BUCKET x OUT OF y ON(colname rand() ) ),推荐,完全随机,速度略慢块抽样,使用分桶表可以加速 - 块抽样方式,
TABLESAMPLE(num ROWS/num PERCENT」num(K|M|G))速度快于桶抽样方式,但不随机,只是按照数据顺序从前向后取。
- 桶抽样方式,
-- 随机桶抽取, 分配桶是有规则的
-- 可以按照列的hash取模分桶
-- 按照完全随机分桶
-- 其它条件不变的话,每一次运行结果一致
SELECT username, orderId, totalmoney
FROM itheima.orders tablesample(bucket 3 out of 10 on orders.username);-- 完全随机,每一次运行结果不同
select * from itheima.orders
tablesample(bucket 3 out of 10 on rand());-- 数据块抽取,按顺序抽取,每次条件不变,抽取结果不变
-- 抽取100条
select * from itheima.orderstablesample(100 rows);-- 取1%数据
select * from itheima.orderstablesample(20 percent);-- 取 1KB数据
select * from itheima.orders tablesample(1K);Virtual Columns虚拟列
- 虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数
-
Hive自前可用3个虚拟列:
INPUT_FILE_NAME,显示数据行所在的具体文件BLOCK_OFFSET_INSIDE_FILE,显示数据行所在文件的偏移量ROW_OFFSET_INSIDE__BLOCK,显示数据所在HDFS块的偏移量- 此虚拟列需要设置:
SET hive.exec.rowoffset=true才可使用
- 此虚拟列需要设置:
-
虚拟列的作用
- 查看行级别的数据详细参数
- 可以用于WHERE、GROUPBY等各类统计计算中
- 可以协助进行错误排查工作
--虚拟列
SET hive.exec.rowoffset=true;SELECT orderid, username, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM itheima.orders;SELECT *, BLOCK__OFFSET__INSIDE__FILE FROM itheima.orders WHERE BLOCK__OFFSET__INSIDE__FILE < 1000;SELECT orderid, username, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM itheima.orders_bucket;SELECT INPUT__FILE__NAME, COUNT(*) FROM itheima.orders_bucket GROUP BY INPUT__FILE__NAME;