河源哪有做网站北京seo排名外包
双向广搜
定义
双向广度优先搜索(Bi-directional Breadth-First Search, Bi-BFS)是一种在图或树中寻找两点间最短路径的算法。与传统的单向广度优先搜索相比,它从起始点和目标点同时开始搜索,从而有可能显著减少搜索空间,提高搜索效率,特别是在处理大规模图或者寻找最短路径时更为明显。
运用情况
- 最短路径问题:当需要快速找到两个节点间的最短路径时,特别是路径非常长或者图非常大的情况下,双向BFS比单向BFS更高效。
- 有界搜索问题:在一些问题中,比如迷宫求解,我们知道起始点和终点,且关心的是尽快相遇而不是探索整个图,这时双向BFS非常适用。
- 游戏AI:在某些游戏中,为了快速计算玩家与目标之间的最短路径,可以使用双向BFS。
- 网络路由:在网络通信中寻找最短的路由路径时,也可以应用此算法。
注意事项
- 相遇判断:当两个搜索的前沿相遇时,需要确保正确识别并停止搜索,避免重复计算。
- 路径合并:找到相遇点后,需要合并两个方向的路径以得到完整的最短路径。
- 空间复杂度:虽然可以减少搜索的深度,但同时维护两个队列(或集合)可能会增加额外的空间消耗。
- 平衡问题:为了优化性能,需要尽量保持两个方向的搜索速度平衡,可以通过调整每一步扩展的节点数来实现。
解题思路
- 初始化:设置两个队列,一个用于存储从起点出发的节点,另一个用于存储从终点出发的节点。同时,为两个方向的节点分别标记已访问状态,防止重复访问。
- 广度优先遍历:同时进行两个方向的广度优先遍历。每次遍历时,从两个队列中各取出一层的节点进行扩展,并将新扩展的节点加入到相应的队列中。
- 检查相遇:在扩展节点的过程中,检查是否有节点已经被另一个方向访问过。如果发现这样的节点,说明找到了一条从起点到终点的路径,此时停止搜索。
- 路径合并:从相遇节点开始,逆向追踪标记,直到回到起点或终点,这样就可以得到完整的最短路径。
- 优化策略:根据具体问题,可能需要考虑启发式信息、队列管理策略等进一步优化搜索过程。
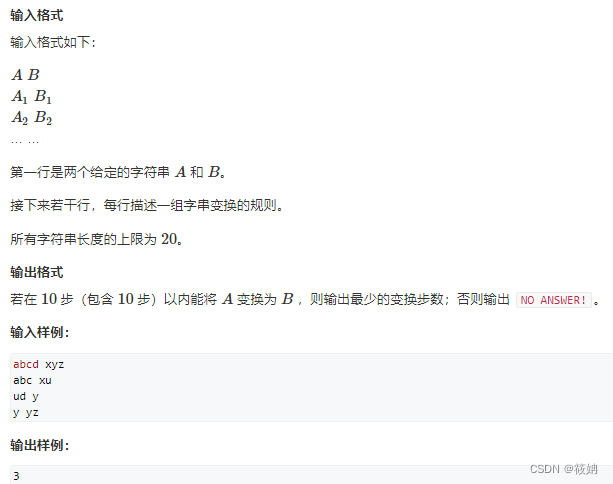
AcWing 190. 字串变换
题目描述
190. 字串变换 - AcWing题库

运行代码
#include <iostream>
#include <cstring>
#include <algorithm>
#include <queue>
#include <unordered_map>using namespace std;const int N = 6;int n;
string A, B;
string a[N], b[N];int extend(queue<string>& q, unordered_map<string, int>&da, unordered_map<string, int>& db, string a[N], string b[N])
{int d = da[q.front()];while (q.size() && da[q.front()] == d){auto t = q.front();q.pop();for (int i = 0; i < n; i ++ )for (int j = 0; j < t.size(); j ++ )if (t.substr(j, a[i].size()) == a[i]){string r = t.substr(0, j) + b[i] + t.substr(j + a[i].size());if (db.count(r)) return da[t] + db[r] + 1;if (da.count(r)) continue;da[r] = da[t] + 1;q.push(r);}}return 11;
}int bfs()
{if (A == B) return 0;queue<string> qa, qb;unordered_map<string, int> da, db;qa.push(A), qb.push(B);da[A] = db[B] = 0;int step = 0;while (qa.size() && qb.size()){int t;if (qa.size() < qb.size()) t = extend(qa, da, db, a, b);else t = extend(qb, db, da, b, a);if (t <= 10) return t;if ( ++ step == 10) return -1;}return -1;
}int main()
{cin >> A >> B;while (cin >> a[n] >> b[n]) n ++ ;int t = bfs();if (t == -1) puts("NO ANSWER!");else cout << t << endl;return 0;
}
代码思路
-
输入处理:首先读取起始字符串A和目标字符串B,然后逐行读取变换规则(子串A[i]到B[i]的变换)直到文件结束。
-
双端BFS:算法采用了双端BFS策略,即同时从字符串A和B出发,试图找到两者之间的最短变换路径。使用两个队列
qa和qb分别存储从A和B出发的可能状态,以及两个哈希表da和db记录每个状态到起点的距离。 -
扩展函数:定义了
extend函数,用于从一个队列中取出所有状态并尝试应用所有变换规则,扩展出新的状态加入队列,并更新距离哈希表。这个函数是BFS的关键,它确保每次扩展只增加一步操作。 -
主循环:在主循环中交替从两端扩展,直到找到变换路径或者达到最大步数限制。
-
结果判断:最后,根据搜索结果输出最少步数或"No Answer!"。
改进思路
-
减少重复计算:当前代码在扩展状态时,对每个状态与每条规则都进行了匹配尝试,这可能会导致大量重复计算,尤其是在规则较多或字符串较长时。可以通过维护一个已访问状态的集合来避免重复探索相同的状态。
-
规则预处理:为了提高效率,可以在开始搜索之前对变换规则进行预处理,比如建立一个从子串到新子串的直接映射,这样在扩展状态时可以直接查找而无需遍历所有规则。
-
剪枝:在双向BFS中,当从两端搜索的边界状态的距离之和已经大于当前最小步数时,可以提前终止搜索,这是一种有效的剪枝策略。
-
内存使用优化:考虑使用更节省空间的数据结构,比如使用滚动数组或者动态调整容器大小来减少内存占用。