网站建设与管理实践心得槐荫区网络营销seo
一. streamx介绍
StreamPark 总体组件栈架构如下, 由 streampark-core 和 streampark-console 两个大的部分组成 , streampark-console 是一个非常重要的模块, 定位是一个综合实时数据平台,流式数仓平台, 低代码 ( Low Code ), Flink & Spark 任务托管平台,可以较好的管理 Flink 任务,集成了项目编译、发布、参数配置、启动、savepoint,火焰图 ( flame graph ),Flink SQL,监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案

StreamX-Core的定位是一个开发时框架,关注编码开发,规范了配置文件,按照约定优于配置的方式进行开发,提供了一个开发时 RunTime Content 和一系列开箱即用的 Connector,扩展了 DataStream 相关的方法,融合了 DataStream 和 Flink sql api,简化繁琐的操作,聚焦业务本身,提高开发效率和开发体验;
StreamXPump的定位是一个数据抽取的组件,类似于flinkx。它基于 streamx-core 中提供的各种 connector 开发,目的是打造一个方便快捷,开箱即用的大数据实时数据抽取和迁移组件,并且集成到 streamx-console 中,解决实时数据源获取问题,目前在规划中;
StreamX-Console是一个综合实时数据平台,低代码(Low Code)平台,可以较好的管理Flink 任务,集成了项目编译、发布、参数配置、启动、savepoint,火焰图(flame graph),Flink SQL,监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。旧时王谢堂前燕,飞入寻常百姓家,让大公司有能力研发使用的项目,现在人人可以使用,其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案。
二.环境要求
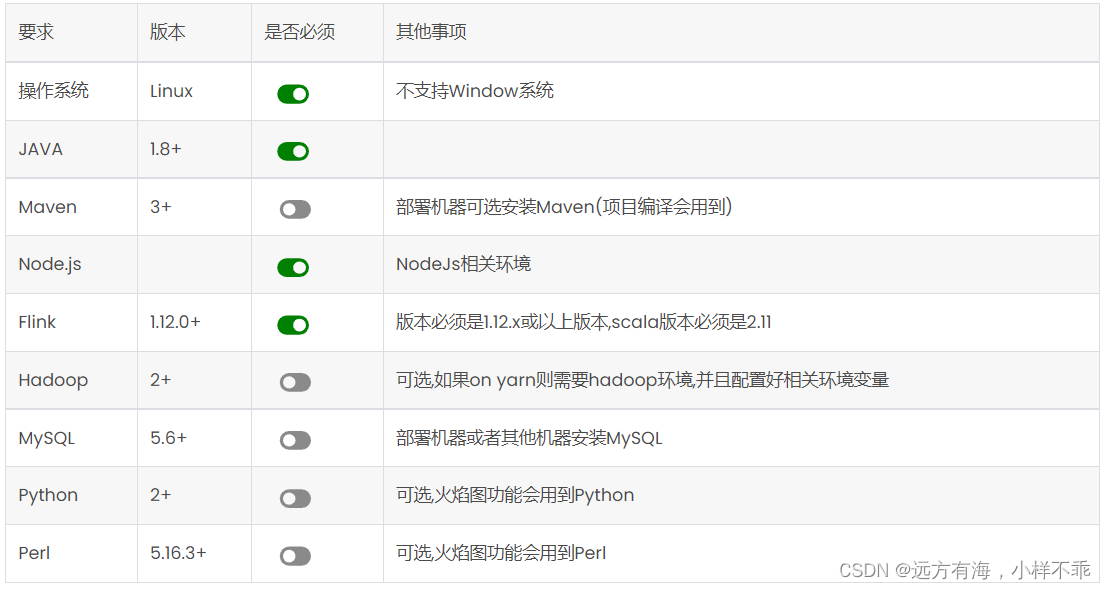
streamx安装包下载:https://github.com/apache/incubator-streampark/releases
三.streamx依赖环境修改(仅限于cdh版本集群)
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_231-amd64
export PATH=$PATH:$JAVA_HOME/bin:$ORACLE_HOME:$ORACLE_HOME/sqlldr
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export FLINK_HOME=/data/flink
export HADOOP_CLASSPATH=`hadoop classpath` # streamx
export STREAMX_HOME=/data/streamx/streamx
export PATH=/data/streamx/streamx/bin:$PATH:/data/flink/bin
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HIVE_HOME=$HADOOP_HOME/../hive
export HBASE_HOME=$HADOOP_HOME/../hbase export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs
export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce
export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn
export PATH=$PATH:$HIVE_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$LIVY_HOME/bin:$SCALA_HOME/bin:$MAVEN_HOME/bin:$HBASE_HOME/bin:$FLINK_HOME/bin
四.修改streamx配置文件
修改部分标注:
1.mysql数据库信息修改
2.hadoop-user-name: hdfs 默认为root
3.local: /data/streamx/streamx/streamx_workspace streamx的安装目录
4.remote: hdfs://xxx:8020/streamx hdfs的namenode地址
server:port: 11000undertow:buffer-size: 1024direct-buffers: truethreads:io: 4worker: 20logging:level:root: infospring:application.name: streamxmvc:pathmatch:matching-strategy: ant_path_matcherdevtools:restart:enabled: falseservlet:multipart:enabled: truemax-file-size: 500MBmax-request-size: 500MBdatasource:dynamic:# 是否开启 SQL日志输出,生产环境建议关闭,有性能损耗p6spy: falsehikari:connection-timeout: 30000max-lifetime: 1800000max-pool-size: 15min-idle: 5connection-test-query: select 1pool-name: HikariCP-DS-POOL# 配置默认数据源primary: primarydatasource:# 数据源-1,名称为 primaryprimary:username: rootpassword: Zhengda@1driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://cdh-xxxxx:3306/streamx?useSSL=false&useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8aop.proxy-target-class: truemessages.encoding: utf-8jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8main:allow-circular-references: truebanner-mode: offmanagement:endpoints:web:exposure:include: [ 'httptrace', 'metrics' ]#mybatis plus 设置
mybatis-plus:type-aliases-package: com.streamxhub.streamx.console.*.entitymapper-locations: classpath:mapper/*/*.xmlconfiguration:jdbc-type-for-null: nullglobal-config:db-config:id-type: auto# 关闭 mybatis-plus的 bannerbanner: falsestreamx:# HADOOP_USER_NAMEhadoop-user-name: hdfs# 本地的工作空间,用于存放项目源码,构建的目录等.workspace:local: /data/streamx/streamx/streamx_workspaceremote: hdfs://cdh-xxxxxx:8020/streamx # support hdfs:///streamx/ 、 /streamx 、hdfs://host:ip/streamx/# remote docker register namespace for streamxdocker:register:image-namespace: streamx# instantiating DockerHttpClienthttp-client:max-connections: 10000connection-timeout-sec: 10000response-timeout-sec: 12000# flink-k8s tracking configurationflink-k8s:tracking:silent-state-keep-sec: 10polling-task-timeout-sec:job-status: 120cluster-metric: 120polling-interval-sec:job-status: 2cluster-metric: 3# packer garbage resources collection configurationpacker-gc:# maximum retention time for temporary build resourcesmax-resource-expired-hours: 120# gc task running interval hoursexec-cron: 0 0 0/6 * * ?shiro:# token有效期,单位秒jwtTimeOut: 86400# 后端免认证接口 urlanonUrl: >/passport/**,/systemName,/user/check/**,/websocket/**,/metrics/**,/index.html,/assets/**,/css/**,/fonts/**,/img/**,/js/**,/loading/**,/*.js,/*.png,/*.jpg,/*.less,/五.元数据库初始化
创建数据库
CREATE DATABASE `streamx` CHARACTER SET utf8 COLLATE utf8_general_ci;
初始化SQL
use streamx;
source /data/streamx/streamx/script/final.sql
六.streamx平台登录
http://x.xx.x:11000
默认用户名:admin 默认密码:streamx
七.streamx 的flink环境配置
注意事项:
1.Flink中的scala版本要与streamx的对应的scala版本要一致
2.streamx兼容多版本的Flink,scala版本都要一致